




Diffus AI影像產生器
Diffus 於 2023 年 5 月發布,是一個基於雲端的平台,它將Stable Diffusion的複雜架構直接引入瀏覽器。該工具託管超過 70,000 個模型,並提供 ComfyUI 等先進的基於節點的工作流程,無需昂貴的本地 GPU 硬體。雖然 Diffus 的複雜設定需要一定的學習成本才能掌握,但Pollo AI能以直覺易用的方式提供高保真、端到端的影像。立即免費試用Pollo AI !
主要特色
- 龐大的模型庫:存取超過 70,000 個檢查點、LoRA 和文本反轉,進行無限的風格探索。
- ComfyUI 整合:直接在瀏覽器中建構複雜的、基於節點的生成工作流程,以實現極致的自訂。
- ControlNet 精通:利用深度圖和邊緣偵測來指導構圖、角色姿勢和結構輪廓。
- ADetailer 精準細節:自動偵測並優化臉部和手部,以消除常見的生成失真。
- HiRes.fix 放大:在生成過程中,使用 50 多種專門的放大演算法來提高解析度。
- Flux Kontext 編輯器:透過文字引導指令修改現有圖像,同時保持角色特徵和佈局。
- 無縫換臉:在不同場景中替換角色臉孔,以保持故事敘述中的視覺一致性。
- 修補與外擴:編輯畫布的特定區域或將場景擴展到其原始邊界之外。
龐大的模型庫
Diffus 以其提供超過 7 萬個社群和專業模型的龐大資料庫而脫穎而出。這讓創作者能夠在寫實渲染、動漫美學和專業建築風格之間無縫切換,而無需管理大量本地檔案。它作為一個集中式中心,讓最新的開源突破能夠即時用於測試和生產。

ComfyUI 整合
對於高階使用者而言,Diffus 提供 ComfyUI 的完整支援,這是一個基於節點的介面,將圖像生成視為模組化管線。使用者可以建構複雜的工作流程,精確地決定模型如何處理提示,從潛在空間雜訊到最終的 VAE 解碼。這種級別的架構控制在雲端平台上很少見,因此深受那些將 AI 視為技術工藝的人喜愛。
ControlNet 精通
對於無法依賴隨機生成的專業人士,Diffus 提供 ControlNet 來強制執行嚴格的構圖規則。透過上傳參考草圖、深度圖或人體姿勢,系統確保最終輸出符合故事板或佈局的精確結構要求。它將生成過程從「擲骰子」轉變為精確的數位繪圖工具。
ADetailer 精準細節
ADetailer(後處理細節)功能專門針對最惡名昭彰的生成缺陷——扭曲的臉部和變形的手指。它的工作原理是在生成的最後階段,對這些區域應用二次、局部處理。這確保即使在複雜的廣角鏡頭中,人物也能保持解剖學上的準確性和視覺清晰度。
與 Diffus 相比,Pollo AI 更進一步,將這些結構一致性直接整合到其核心模型中。Pollo AI 的模型無需使用者手動配置二次處理或節點結構,即可直觀地理解人體解剖結構。它開箱即用,即可生成完美無瑕的臉部和精確的構圖,省去了手動工具所需的「拼湊」工作。
HiRes.fix 放大
Diffus 中的 HiRes.fix 工具允許藝術家將其創作提升至專業印刷解析度,而不會引入高解析度 SD 生成中常見的「雙頭」偽影。它首先以較低解析度智慧計算構圖,然後在第二次處理中放大並添加細節。這確保即使在大幅放大後,圖像的原始完整性也能得以保留。
Flux Kontext 編輯器
Flux Kontext 的整合引入了強大的文本引導編輯功能。使用者可以匯入現有圖像,並指示系統在嚴格保留主體特徵的前提下,更改光照、替換物體或修改背景。它充當了純生成與後製之間的橋樑,允許針對單一視覺概念進行快速迭代。
為了實現更專業的控制,Pollo AI 照片編輯器提供卓越、更流暢的使用體驗。Diffus 需要理解特定的模型上下文,而 Pollo AI 則採用一體化智慧編輯器。它支援使用自然語言進行物件移除、風格轉換和背景替換,確保最終圖像看起來像一張統一的專業照片,而非經過處理的檔案。
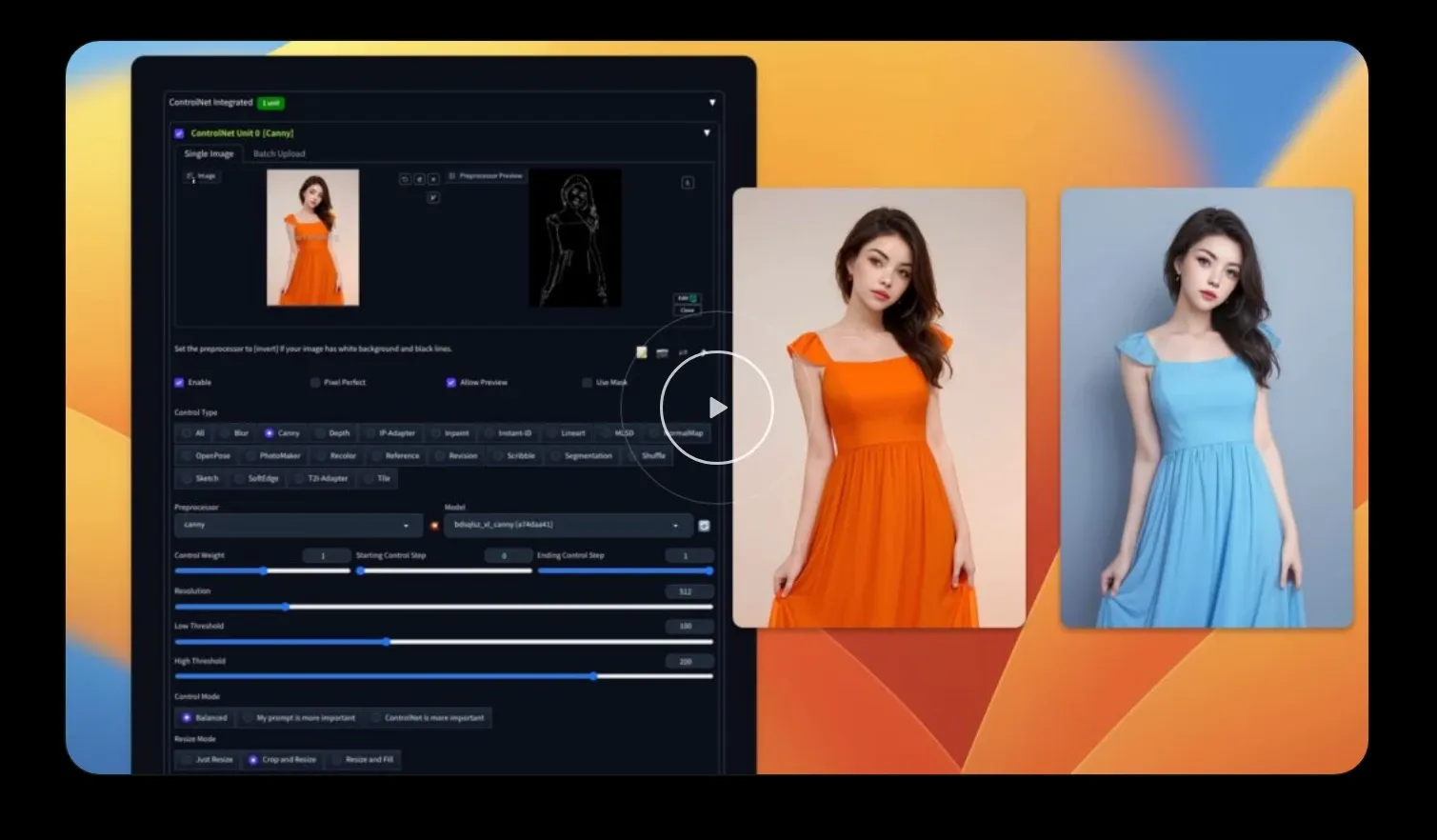
無縫換臉
在數位敘事中,保持角色一致性是一項重大挑戰。Diffus 透過專用的換臉工具來解決這個問題,該工具確保角色在不同畫面中仍保持可識別性。這對於創作漫畫小說或行銷活動的創作者來說至關重要,因為主角的身分必須在各種環境和服裝中保持不變。
修補與外擴
這些工具提供一個數位畫布,藝術家可以在上面擦除不需要的元素或無限擴展環境。如果風景感覺過於擁擠,外擴功能會使用周圍的像素作為參考來「想像」其餘的景色。修補工具允許進行局部修復,例如更改特定服裝而不會影響圖像的其他部分。
Diffus 產品定位與背景
Diffus 作為由 Edward Cui 創立的自力更生倡議,在生成式 AI 領域嶄露頭角。作為一家擁有小型專屬團隊的私人實體,該公司發現市場存在一個顯著的缺口:在本地運行複雜的 Stable Diffusion 環境的進入門檻很高。
透過將這些要求嚴苛的計算任務遷移到雲端,Diffus 將自己定位為休閒提示驅動生成器和重型本地安裝之間的橋樑。
Diffus 專門針對獨立駭客、概念藝術家和行銷機構,他們需要 Automatic1111 和 ComfyUI 等工具的精確性,但缺乏昂貴的硬體基礎設施。
Diffus 主要應用場景
- 遊戲資產原型製作:獨立開發者利用龐大的模型庫和 ControlNet 快速生成符合特定藝術方向的一致角色精靈、環境紋理和概念藝術。
- 行銷活動視覺效果:廣告公司利用該平台建立高解析度、品牌一致的圖像,使用自訂 LoRA 確保企業吉祥物或產品風格在所有促銷材料中保持一致。
- 數位藝術精修:專業插畫家使用修補和 ADetailer 來修復其作品中的特定缺陷,將傳統數位繪畫技術與智慧自動化相結合,以完善手部和面部表情等複雜細節。
- 故事板和漫畫創作:視覺故事敘述者依賴換臉和姿勢控制功能,以在連續面板中保持角色身分和精確分鏡,簡化敘事製作過程。
Diffus 評論:使用者對 Diffus AI 的真實評價
在 AppSumo 和 Trustpilot 等平台,Diffus 的技術能力普遍受到好評,尤其是對 ComfyUI 的支援。然而,使用者回饋也指出,在系統穩定性和客戶支援方面存在嚴重的問題點。
最主要的問題點在於計費和技術可靠性。一位使用者反映:「我花了 36 美元試用他們的模型,但每次生成都返回紅色文字錯誤。我完全沒有收到任何圖像,他們的支援部門也對我的電子郵件置之不理數週。」
此外,介面的複雜性仍然是一個障礙。另一位評論者指出:「這個網站雜亂無章,令人困惑。我花在調試 API 上的時間比實際創作藝術的時間還多。這是一個很棒的概念,但執行起來感覺像是一個容易崩潰的測試版專案。」
Pollo AI 透過提供穩定、高可用性的環境來解決這些可靠性問題。使用者無需擔心「紅色文字錯誤」或因生成失敗而浪費積分;該平台提供一致、高傳真度的結果,可立即使用,並由專業支援提供後盾。
功能比較:Diffus 與 Pollo AI
比較因素 | Diffus | |
輸出類型 | 高度客製化,需要手動精修。 | 可直接用於出版,完美無瑕的端到端圖像。 |
技術優勢 | ComfyUI 整合和自訂模型上傳。 | 情境理解與無縫多模型智慧。 |
編輯工作量 | 高。 | 零。 |

為什麼創作者紛紛轉向Pollo AI
50多個專業人工智慧模型
Pollo AI整合了Flux 、 Nano Banana和Seedream等精英模型,讓您在一個統一的空間中存取最佳模型。
主題一致性
在多個場景中保持品牌或角色形象的完美一致性。 Pollo Pollo AI可確保您的關鍵視覺元素保持不變。
常見問題解答
Diffus 是用來做什麼的?
這是一個基於雲端的平台,旨在運行Stable Diffusion模型和複雜的介面(如 ComfyUI),使用戶無需高端本地硬體即可生成和精確控制數位影像。
Diffus 是否支援自訂模型?
是的,使用者可以上傳自己的檢查點、LoRA 和文字反轉,這使得它對需要保持特定、一致的藝術風格的創作者來說具有很高的適應性。
Diffus 適合初學者嗎?
雖然它提供了一些基本的生成工具,但該平台主要面向專業人士。初學者往往會覺得介面和大量的參數設定令人不知所措。
我可以用Diffus修復手部或臉部瑕疵嗎?
是的,Diffus 包含 ADetailer 等專用工具,它可以在生成過程中自動偵測和細化臉部和手部,以提高解剖結構的準確性。
Diffus 需要高效能電腦嗎?
不,所有渲染和處理都在雲端伺服器上完成。使用者只需使用現代瀏覽器和穩定的網路連線即可使用其全部功能。
產生的圖片是私密的嗎?
根據他們的條款,生成的圖像將保留在用戶的帳戶中,但用戶可以選擇與更廣泛的社群分享他們的作品和工作流程。

停止糾結於複雜的節點,開始創建
無需再為學習曲線和分散的工具而煩惱,即可獲得可用的影像。立即體驗Pollo AI流暢、高保真的處理流程。