



OpenArt Image Generator-anmeldelse: Jeg testet OpenArt Image Generator i flere uker, og det revolusjonerte min digitale kunstopplevelse
OpenArt er en av de mest allsidige AI-bildegeneratorene som kan brukes til å lage bilder fra tekst.
Basert på OpenArt SDXL-, OpenArt Creative- og Stable Diffusion XL AI-modellene, varierer stilen på bildeutgangen fra fotorealistiske landskap og portretter til abstrakt kunst og digitale illustrasjoner.
Etter å ha testet programvaren, fant jeg ut at dette verktøyet utmerker seg i å generere forskjellige bildestiler basert på instruksjonene mine og trene AI-bildemodellene mine.
Uansett om jeg vil skape en person eller skildre et landskap, kan det generere bilder på sekunder.
Dessuten integrerte den en AI-robot i programvaren, slik at jeg kan justere resultatet ved å chatte med chatboten.
Men siden det fortsatt er i utviklingsfasen av tekst-til-video-generering, foretrekker jeg å bruke det som en tekst-til-bilde-generator og -redigerer i stedet for en videogenerator.
I de følgende delene vil jeg dele hvordan OpenArt AI-bildegeneratoren har revolusjonert min digitale kunstopplevelse.
Min personlige erfaring med OpenArt AI-bildegenerator
I løpet av de siste ukene har jeg brukt tid på å teste verktøyet grundig. Jeg utforsket OpenArts funksjoner og begrensninger, fra generering av tekst til bilde til bilderedigering.
Først tok jeg en titt på AI-teknologien deres, som også er OpenArts viktigste konkurransefortrinn. OpenArt bruker sofistikerte skybaserte databehandlingsteknologier for å drive ComfyUI-arbeidsflyter i skyen.
Dette sikrer at jeg kan utføre design og kreative bestrebelser når som helst og hvor som helst. Dermed trenger jeg ikke å bekymre meg for ytelsen og begrenset lagringsplass på mine lokale enheter.
Så er jeg imponert over at den kan lage forskjellige bildestiler. Uansett om jeg vil lage et realistisk portrett eller en fotorealistisk scene, kan jeg gjøre det via OpenArt.
På hjemmesiden så jeg to moduser: Imae og Storytelling. Den ene brukes til å generere og redigere bildene, og den andre brukes til å lage konsistente karakterer og lage videoer.
Siden jeg hovedsakelig fokuserte på å generere bilder, bestemte jeg meg for å starte med tekst-til-bilde-funksjonen.
Etter å ha valgt Flux (dev)-modellen som standard, skrev jeg inn ledeteksten:
Fotorealistisk portrett av {Einstein}, sentrert i bildet, vendt mot kameraet, symmetrisk ansikt, idealmenneske, 85 mm objektiv, f8, fotografi, ultradetaljer, naturlig lys, lys bakgrunn, foto, studiobelysning.
Fra én enkelt ledetekst kan OpenArt generere opptil fire bilder. Her har jeg satt meg fore å generere to bilder.
Begge bildene gjenspeiler essensen av et profesjonelt studioportrett. Ansiktene deres er symmetriske og milde, noe som er i tråd med oppfordringens krav til «idealmenneske».
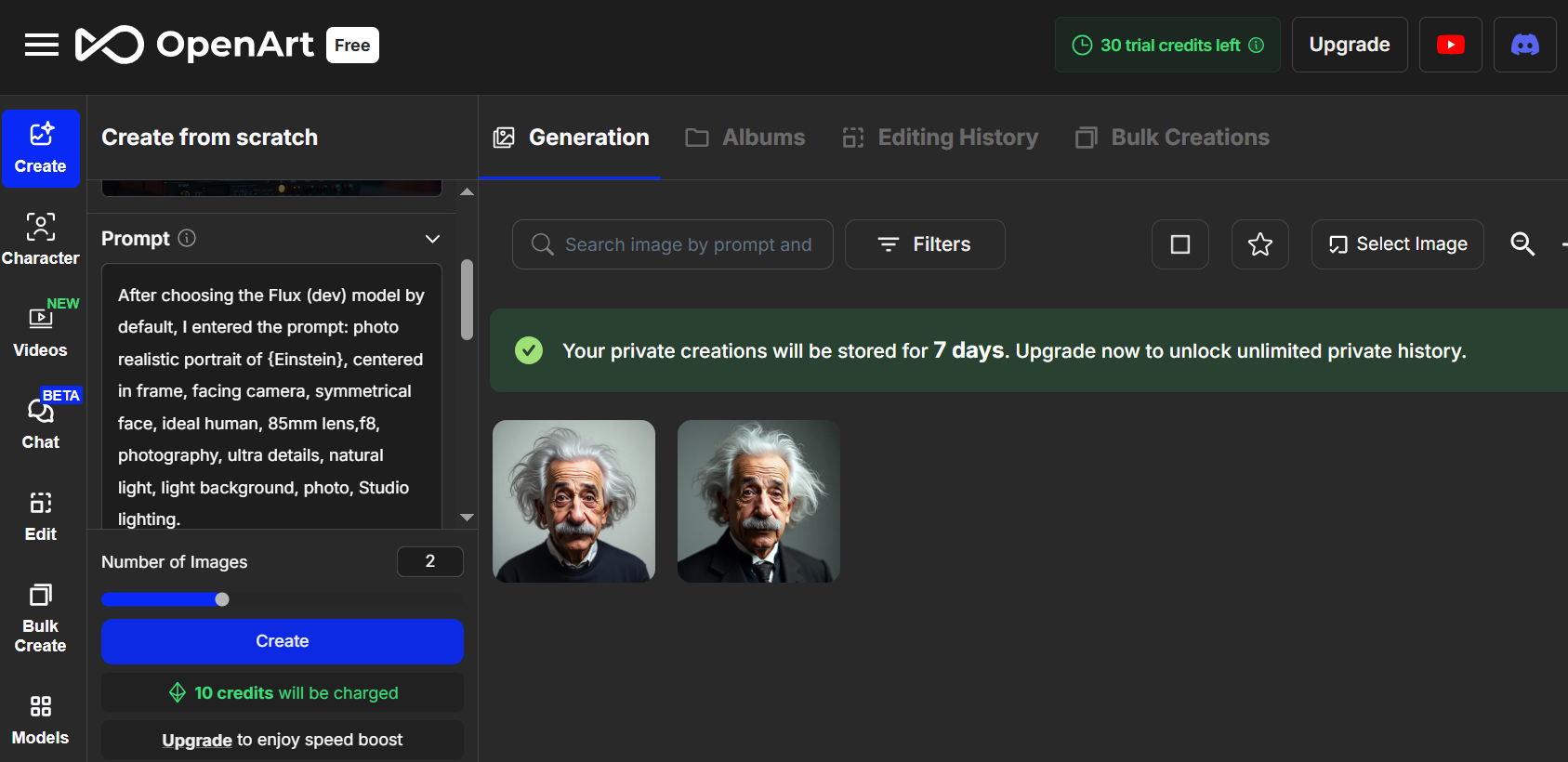
Forskjellene mellom disse to utgangene er imidlertid også merkbare.
Det venstre bildet er bare litt uskarpt, spesielt i kanten av karakterens ansikt og hår, og dette gjør det generelle bildet uskarpt og mindre skarpt og detaljert enn det til høyre.

Den høyre er skarpere med mer definerte trekk og mer skarpe detaljer. Den ser mer fotorealistisk ut.
Kontrasten og belysningen i det høyre bildet virker også litt mer balansert, med ansiktsstrukturer og hudtekstur som er litt mer tydelige.

Dette var en god start, men jeg ville bare lage et mer profesjonelt kunstverk. Heldigvis fant jeg noe bra – en OpenArt-ledetekstmal.
Basert på de forhåndsinnstilte strukturene kunne jeg lage verk som bakgrunnsbilder, 3D-figurer, logoer for idrettslag osv.
Jeg klikket på malen for bakgrunnsbilde-ledeteksten og fikk en ny ledetekst: Flere lag med silhuett {elv}, med silhuett av {båt}, skarpe kanter, ved solnedgang, med tett tåke i luften, vektorstil, horisontsilhuett, landskapsbakgrunn av Alena Aenami, Firewatch-spillstil, vektorstilbakgrunn
Disse to bildene viser en lignende scene med en solnedgang over et fjellandskap med en elv som reflekterer himmelens farger. Man kan imidlertid også se subtile forskjeller mellom dem.
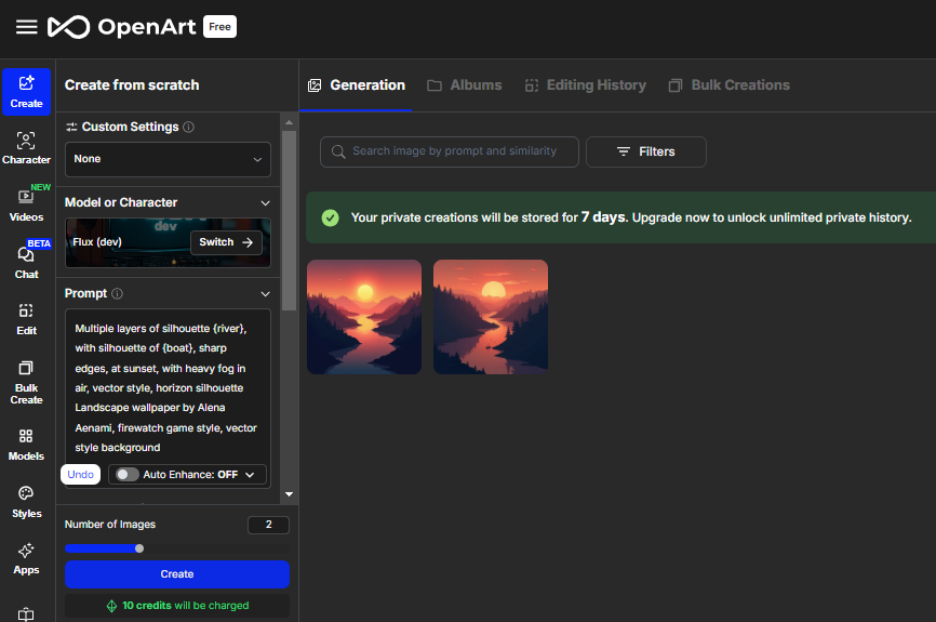
Det første bildet har en mer levende og varmere farge. Solen viser en lysere oransje fargetone, og himmelen viser mer intense nyanser av rosa og lilla.

Det andre bildet har en litt mørkere og kaldere tone. Solen virker mindre intens, og himmelen viser en mer dempet blanding av farger.

Jeg foretrakk den til venstre, så jeg klikket på bildet for å forbedre og finjustere det.
Så ble bakgrunnsbildet plassert på lerretet. Her så jeg en gruppe redigeringsverktøy. For å endre bildet tenkte jeg på å redigere eksisterende bilder med funksjoner som innmaling, utmaling og fjerning av objekter.
Jeg forstørret bildet på lerretet, men jeg fant ut at det ikke var behov for å fjerne eller skjule uønskede elementer i et bilde.
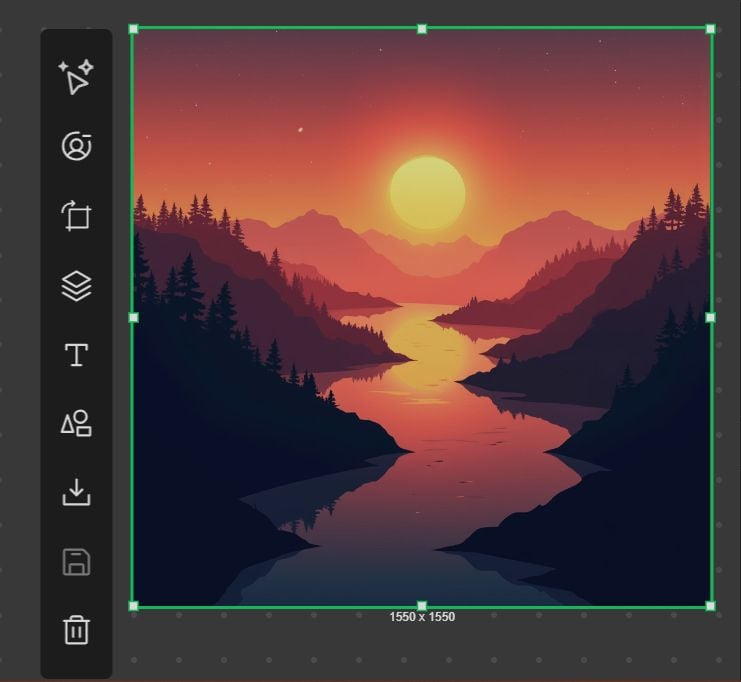
Så bestemte jeg meg for å overføre stilen for å bruke en annen kunstnerisk stil. På topppanelet trykket jeg på alternativet «Stilisert» og valgte en stil fra høyre panel.
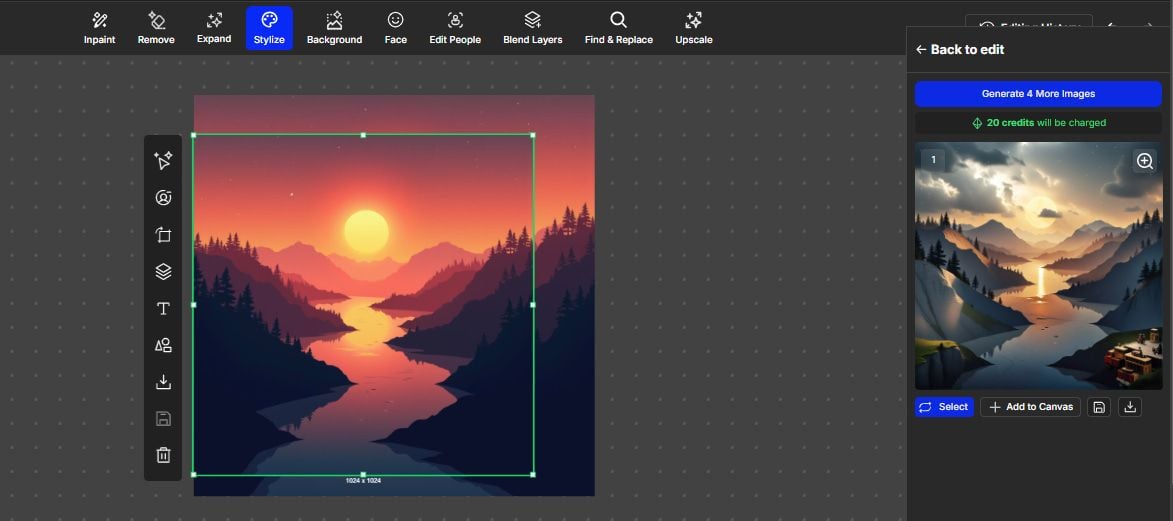
Etter å ha endret stilen, ble både fargepaletten og elementene i scenen endret. Refleksjonen av månen på innsjøen gir en følelse av symmetri og balanse til komposisjonen. Ved å legge til og fjerne elementer endret AI historien bildet fortalte betydelig.

Begge bildene brukte farger for å formidle ulike stemninger og tider på dagen. Etter å ha endret stilen ble scenen mer rolig.
Dominert av kjølige blå- og lillafarger, fremkalte det en følelse av ro og fred. Dessuten tilførte en liten hytte også et snev av varme, som antydet tilstedeværelsen av mennesker.
Deretter prøvde jeg å endre bildet ved å chatte med AI-boten. Jeg valgte Gemini AI-modellen, lastet opp bildet som nettopp ble generert, og deretter skrev jeg inn ledeteksten: Gjør dette om til Ghibli-studiostil.
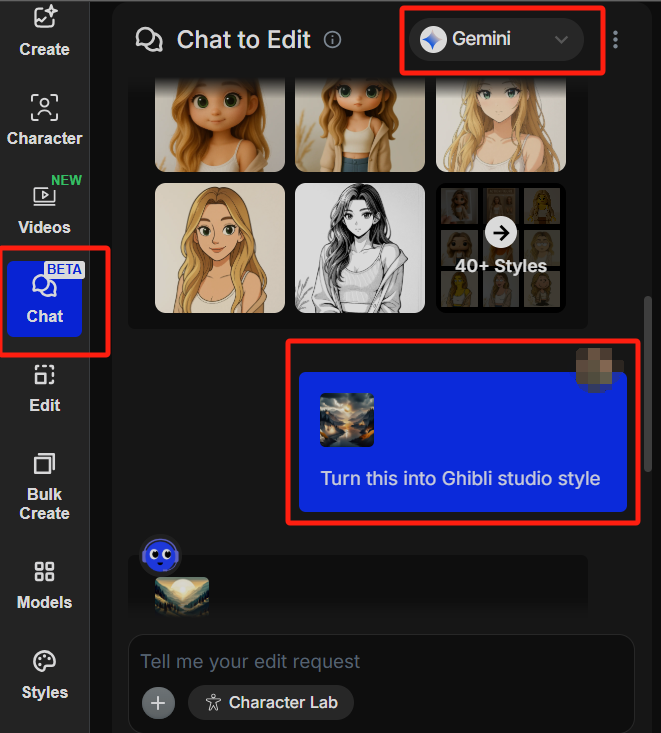
I løpet av noen sekunder ga den meg tilbakemelding i dialogboksen og fortalte meg hvordan den skulle generere et bilde i Studio Ghibli-stil:
Jeg vil lage et bilde i Studio Ghibli-stil, som viser et fredelig fjellandskap i skumring eller daggry. En stor, glødende måne vil henge på himmelen over en svingete elv som renner gjennom dalene. Furutrær vil pryde åssidene, og et mykt, varmt lys vil utstråle fra månen og reflektere seg i vannet. To små figurer vil være synlige på en av åsene, noe som gir et snev av menneskelig tilstedeværelse til det enorme landskapet, som minner om de detaljerte bakgrunnene og det atmosfæriske perspektivet som ofte finnes i Ghibli-filmer.
Denne gangen ble det lagt til to personer, og denne gangen flere trær. Disse menneskene gjorde at scenen føltes mer levende og innbydende, mens trær spredt over landskapet forsterker følelsen av dybde og rikdom i miljøet.
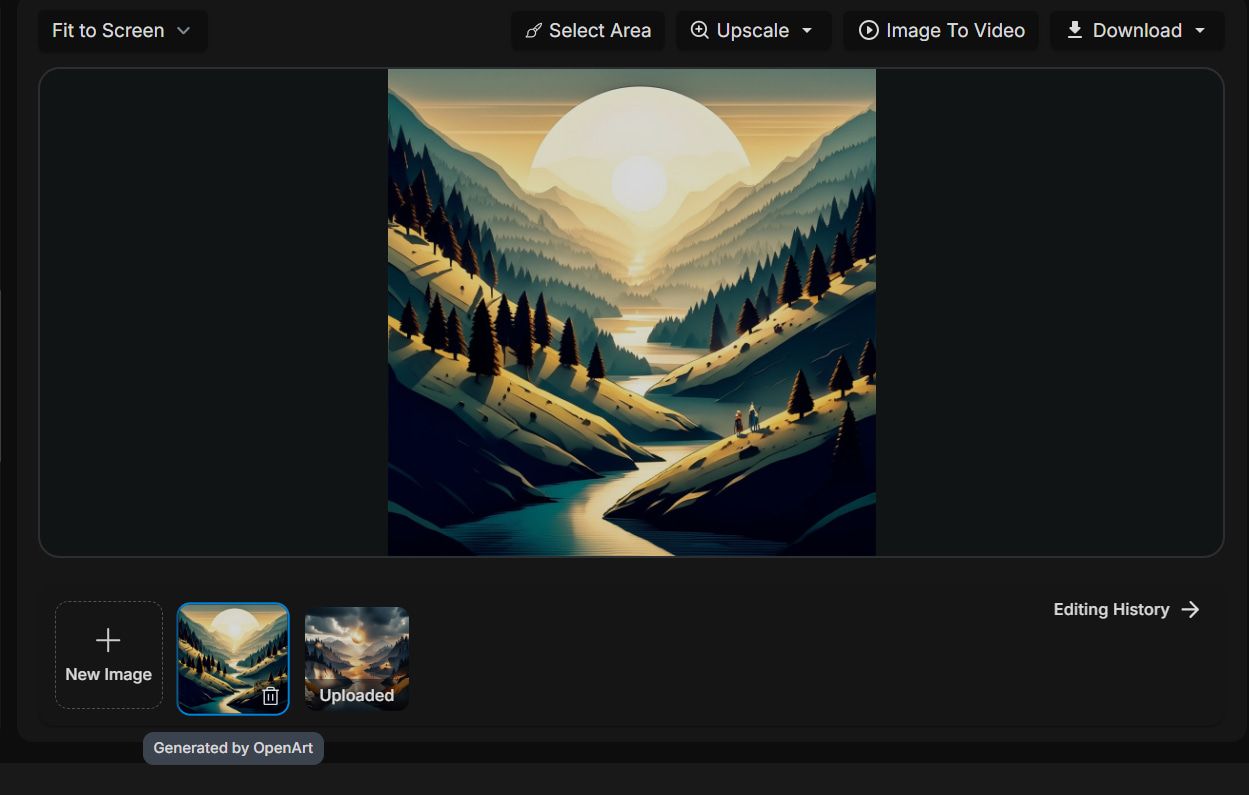
Jeg foretrakk Ghibli Studio-stilen, fordi de varme fargene og solens tilstedeværelse også bidro til en mer levende og energisk stemning. Den virket også mer tiltalende for noen seere.
Sist, men ikke minst, er OpenArt smart nok til at jeg kan trene modellene mine basert på mine spesifikke behov og preferanser. Dette gir en svært personlig tilpasset opplevelse.
For eksempel skriver jeg et innlegg om vår nye merkevareprogramvare. Jeg bestemmer meg for å generere noen konseptbilder om dette produktet. Deretter kan jeg trene en AI-modell. Følgelig kan jeg samle et stort antall relevante bildeeksempler ved å trene AI-modeller og generere bilder med OpenArt.
Oppsummert fungerer OpenArt bra når det gjelder å generere ulike bildestiler. Uansett om du er en original kunstner eller en 3D-modellbygger, kan du få litt innsikt fra de genererte bildene.
I tillegg kan du opprette AI-bildegeneratormodeller basert på dine spesifikke behov. Siden denne funksjonen bruker mange flere studiepoeng, opptil 2000 studiepoeng, kan du prøve den når du kjører et større prosjekt.
Pollo AI: Det neste kapittelet i min kreative reise
Nylig har Pollo AI dukket opp som et attraktivt alternativ til OpenArt. Jeg har prøvd dette verktøyet. Det er som en alt-i-ett-plattform som integrerer bilde- og videogenerering på ett sted.
Når det gjelder bildegenereringsfunksjonen, kan jeg ikke bare lage bilder fra tekstmeldinger, men jeg kan også konvertere bilde til bilde .
Viktigst av alt, den har den nyeste bildegenereringsmodellen, Seedream 5.0 Lite .
Konklusjon
OpenArt-bildegeneratoren har effektivisert måten jeg lager kunstverk på. Med dette verktøyet kan jeg generere bilder fra tekst, redigere resultatet med de innebygde redigeringsverktøyene og til og med trene AI-bildemodeller basert på mine spesifikke behov. Det visuelle resultatet av høy kvalitet er fullt av detaljer og en følelse av historiefortelling.