



Seedance 2.0: คู่มือฉบับสมบูรณ์พร้อมภาคปฏิบัติสำหรับยุคที่ทุกคนกลายเป็นผู้กำกับ
ในช่วงไม่กี่วันที่ผ่านมา Seedance 2.0 ซึ่งเป็นโมเดลวิดีโอ AI ของ ByteDance ได้ครองโลกอินเทอร์เน็ตไปโดยปริยาย
วิดีโอที่สร้างโดย Seedance 2.0 กำลังแพร่หลายอยู่ทั่วไปในขณะนี้
ผู้คนกำลังใช้มันเพื่อสร้างฉากไล่ล่าระดับภาพยนตร์ บางคนกำลังสร้างการเคลื่อนไหวของกล้องแบบภาพยนตร์ที่คุณมักเห็นในโฆษณาทุนสูง บางคนถึงกับเปลี่ยนมันให้กลายเป็นละครย้อนยุค เรื่องราวเกี่ยวกับการเดินทางข้ามเวลา หรือภาพยนตร์แอ็คชั่นศิลปะการต่อสู้เต็มรูปแบบ—ภาพที่ได้คมชัดและละเอียดมากจนยากที่จะบอกได้ว่าสร้างขึ้นโดย AI หรือถ่ายทำโดยนักแสดงจริง
และพูดตามตรง นี่ไม่ใช่การพูดเกินจริงเลย
ด้วยการอัปเดตครั้งนี้ Seedance 2.0 ได้ทำลายอุปสรรคในการสร้างวิดีโอด้วย AI ไปอย่างสิ้นเชิง
พอแล้วกับการพูดคุย มาเริ่มกันด้วยภาพตัดต่อสั้นๆ กันเลย ↓
แล้ว...หน้าตาเป็นยังไงบ้าง?
ทำไมมันถึงได้รับความนิยมอย่างรวดเร็ว? เพราะมันแก้ปัญหาที่รบกวนผู้สร้างมานานหลายปีได้สำเร็จ: วิดีโอ AI เคยเน้นเรื่องการสร้างเนื้อหา แต่ตอนนี้มันเน้นเรื่องการควบคุมแล้ว
ผสมผสานภาพนิ่ง วิดีโอ เสียง และข้อความได้อย่างอิสระ ใครๆ ก็สามารถกำกับได้

ครั้งนี้สถานการณ์แตกต่างออกไป
Seedance 2.0 ไม่ได้เป็นเพียงแค่ เครื่องมือแปลงข้อความเป็นวิดีโออีกต่อ ไปแล้ว มันได้พัฒนาไปสู่แพลตฟอร์มสร้างวิดีโอแบบมัลติโมดอลอย่างแท้จริง ที่สามารถเข้าใจเจตนาในการสร้างสรรค์ได้
คุณสามารถป้อนภาพ คลิปวิดีโอ เสียง และข้อความพร้อมกันได้ คุณบอกโปรแกรมว่าแต่ละส่วนมีหน้าที่อะไร จากนั้นโปรแกรมจะผสมผสานทุกอย่างเข้าด้วยกันเป็นวิดีโอที่สมบูรณ์
ฟังดูซับซ้อนไปหน่อยใช่ไหม? ไม่เป็นไรหรอก
ฉันจะอธิบายทุกฟีเจอร์และขั้นตอนการทำงานทีละขั้น และแสดงให้คุณเห็นว่าผู้คนใช้งานกันอย่างไร
สิ่งแรกที่ต้องรู้: Seedance 2.0 ทำอะไรได้บ้าง?
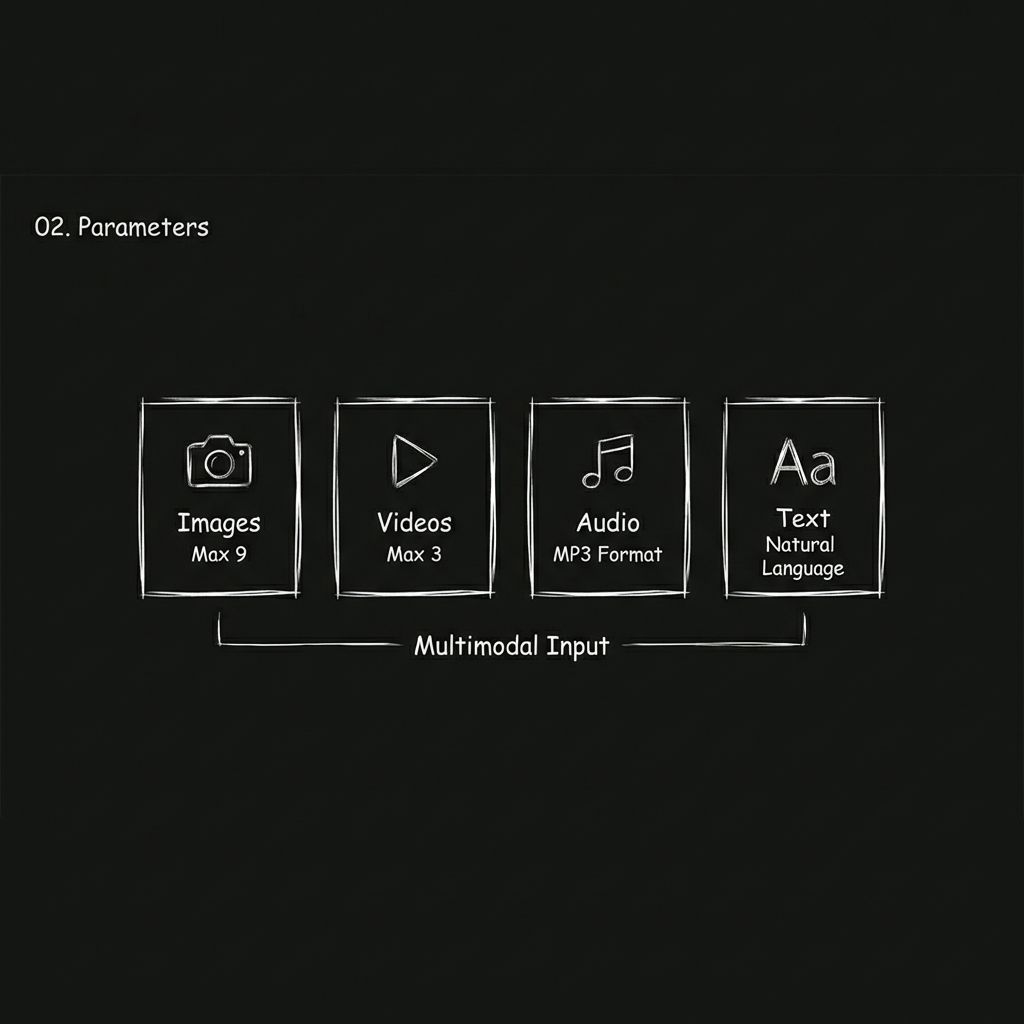
หัวใจสำคัญของการอัปเกรด Seedance 2.0 คือ การรองรับหลายรูปแบบ (Multimodality)
ใน โมเดล AI วิดีโอรุ่น ก่อนๆ ตัวเลือกในการป้อนข้อมูลมักจำกัดอยู่เพียงสองอย่าง คือ เขียนข้อความ หรืออัปโหลดภาพเฟรมแรกเพียงภาพเดียว
หากคุณต้องการควบคุมการเคลื่อนไหวของกล้อง การแสดงออกทางสีหน้า หรือจังหวะของดนตรีประกอบ ทุกอย่างจะต้องถูกถ่ายทอดออกมาเป็นข้อความ ไม่ว่ามันจะได้ผลหรือไม่นั้นขึ้นอยู่กับว่าคุณเก่งแค่ไหนในการเขียนคำแนะนำ
Seedance 2.0 เปลี่ยนแปลงสิ่งนี้โดยขยายอินพุตออกเป็นสี่รูปแบบที่แตกต่างกัน
รูปภาพ
คุณสามารถอัปโหลดภาพได้สูงสุด 9 ภาพ ภาพเหล่านี้สามารถใช้กำหนดลักษณะของตัวละคร สไตล์ฉาก รายละเอียดของเสื้อผ้า ภาพสินค้า หรือแม้แต่เฟรมภาพในสตอรี่บอร์ดก็ได้
วิดีโอ
คุณสามารถอัปโหลดคลิปวิดีโอได้สูงสุด 3 คลิป โดยมีความยาวรวมไม่เกิน 15 วินาที นางแบบสามารถใช้คลิปเหล่านี้เป็นแบบอย่างในการเรียนรู้การเคลื่อนไหวของกล้อง จังหวะการเคลื่อนไหว และรูปแบบการเปลี่ยนฉาก ในทางปฏิบัติแล้ว วิธีนี้เปรียบเสมือนการให้ตัวอย่างภาพแก่นางแบบเพื่อใช้ในการเรียนรู้
เสียง
รองรับการอัปโหลดไฟล์ MP3 ได้สูงสุด 3 ไฟล์ โดยมีความยาวรวมไม่เกิน 15 วินาที คุณสามารถระบุเพลงประกอบ รูปแบบเอฟเฟกต์เสียง หรือแม้แต่ใช้โทนเสียงบรรยายจากวิดีโออื่นได้
ข้อความ
คุณเพียงแค่บรรยายภาพ การกระทำ และจังหวะที่คุณต้องการ โดยใช้ภาษาธรรมชาติมาตรฐานในการป้อนข้อมูล
สามารถผสมผสานประเภทข้อมูลขาเข้าทั้ง 4 แบบได้อย่างอิสระ จำนวนไฟล์ที่อัปโหลดได้ทั้งหมดจากทุกรูปแบบจำกัดอยู่ที่ 12 ไฟล์
วิดีโอที่สร้างขึ้นมีความยาวได้สูงสุด 15 วินาที คุณสามารถเลือกความยาวได้ระหว่าง 4 ถึง 15 วินาที และวิดีโอที่ได้จะมีเอฟเฟกต์เสียงและเพลงประกอบในตัว
กล่าวโดยสรุป คุณสามารถกำกับ AI ได้เหมือนกับผู้กำกับภาพยนตร์ตัวจริงเสียที:
- ภาพเป็นตัวกำหนดรูปแบบการออกแบบ
- วิดีโอเป็นตัวกำหนดการเคลื่อนไหว
- เสียงเป็นตัวกำหนดจังหวะ
- เนื้อหาเป็นตัวกำหนดเรื่องราว
ข้อมูลจำเพาะของอินพุตและเอาต์พุตของ Seedance 2.0
| พารามิเตอร์ | คำอธิบาย |
| การป้อนภาพ | สูงสุด 9 ภาพ |
| อินพุตวิดีโอ | สามารถส่งคลิปได้สูงสุด 3 คลิป โดยมีความยาวรวมไม่เกิน 15 วินาที |
| อินพุตเสียง | รองรับไฟล์ MP3 สูงสุด 3 ไฟล์ โดยมีความยาวรวมไม่เกิน 15 วินาที |
| การป้อนข้อความ | คำอธิบายด้วยภาษาธรรมชาติ (รองรับภาษาอังกฤษและภาษาจีน) |
| ระยะเวลาเอาต์พุต | 4 ถึง 15 วินาที |
| เอาต์พุตเสียง | เอฟเฟกต์เสียงและเพลงประกอบในตัว |
| ขีดจำกัดไฟล์ทั้งหมด | สามารถอัปโหลดไฟล์ได้สูงสุด 12 ไฟล์ |
คำแนะนำสั้นๆ ก่อนเริ่มต้น : เอกสารอ้างอิงจำนวนมากไม่ได้หมายความว่าจะได้ผลลัพธ์ที่ดีขึ้นเสมอไป
ให้ความสำคัญกับเนื้อหาที่มีผลกระทบต่อภาพหรือจังหวะการดำเนินเรื่องมากที่สุด และจัดสรรเวลาในการอัปโหลดอย่างชาญฉลาด
วิธีใช้งาน: คำแนะนำทีละขั้นตอน
ขั้นตอนที่ 1. เลือกจุดเริ่มต้นที่เหมาะสม
เปิด Jimeng แล้วค้นหา Seedance 2.0
คุณสามารถเข้าถึง Seedance 2.0 ผ่านทาง Jimeng ได้ และเร็วๆ นี้จะพร้อมใช้งานบน หน้า Pollo AI Image to Video ด้วย
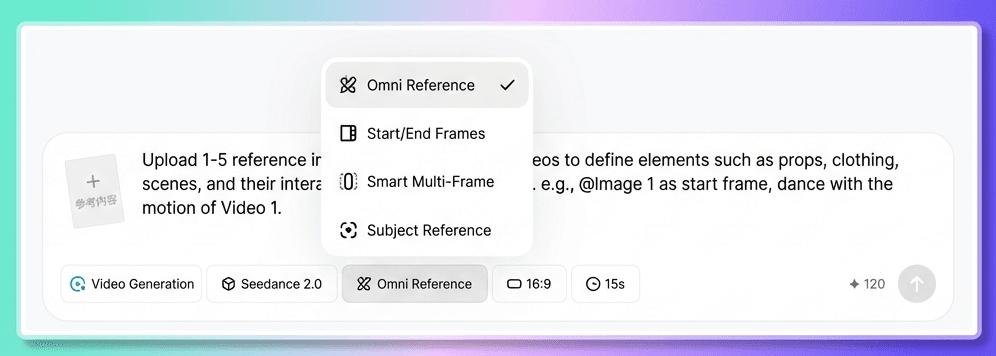
คุณจะเห็นทางเข้าสองทางที่แตกต่างกัน
- เฟรมแรกและเฟรมสุดท้าย : ใช้ตัวเลือกนี้เมื่อคุณอัปโหลดเฉพาะภาพเฟรมแรกภาพเดียวพร้อมกับข้อความแจ้งเตือน
- ข้อมูลอ้างอิงแบบรวมทุกอย่างในที่เดียว : ใช้ตัวเลือกนี้เมื่อคุณต้องการข้อมูลป้อนเข้าหลายรูปแบบ เช่น รูปภาพ วิดีโอ เสียง และข้อความรวมกัน
คุณจะตัดสินใจเลือกใช้ตัวเลือกใด? ใช้กฎง่ายๆ ดังนี้: หากเอกสารของคุณประกอบด้วยภาพเพียงภาพเดียวและข้อความ ให้เลือก First and Last Frame; หากคุณมีภาพมากกว่าหนึ่งภาพ หรือมีวิดีโอหรือเสียงเกี่ยวข้อง ให้เลือก All-in-One Reference
โดยส่วนใหญ่แล้ว All-in-One Reference เป็นตัวเลือกที่ดีกว่า เนื่องจากรองรับอินพุตอ้างอิงทุกประเภท และยังเป็นส่วนที่ Seedance 2.0 สามารถแสดงความสามารถล่าสุดได้อย่างเต็มที่
ขั้นตอนที่ 2. อัปโหลดไฟล์ของคุณ
คลิกปุ่มอัปโหลดและเลือกไฟล์จากอุปกรณ์ของคุณ คุณสามารถลากรูปภาพ วิดีโอ และไฟล์เสียงเข้ามาได้โดยตรง เมื่อการอัปโหลดเสร็จสมบูรณ์ ไฟล์ทั้งหมดจะปรากฏในพื้นที่ป้อนข้อมูล คุณสามารถวางเมาส์เหนือแต่ละรายการเพื่อดูตัวอย่างเนื้อหาได้
ก่อนอัปโหลด โปรดจำไว้ว่า: พิจารณาให้ดีว่าไฟล์ใดสำคัญที่สุด คุณสามารถอัปโหลดได้สูงสุด 12 ไฟล์ ดังนั้นควรจัดลำดับความสำคัญของไฟล์ที่มีผลกระทบต่อสไตล์ภาพและจังหวะการนำเสนอมากที่สุด
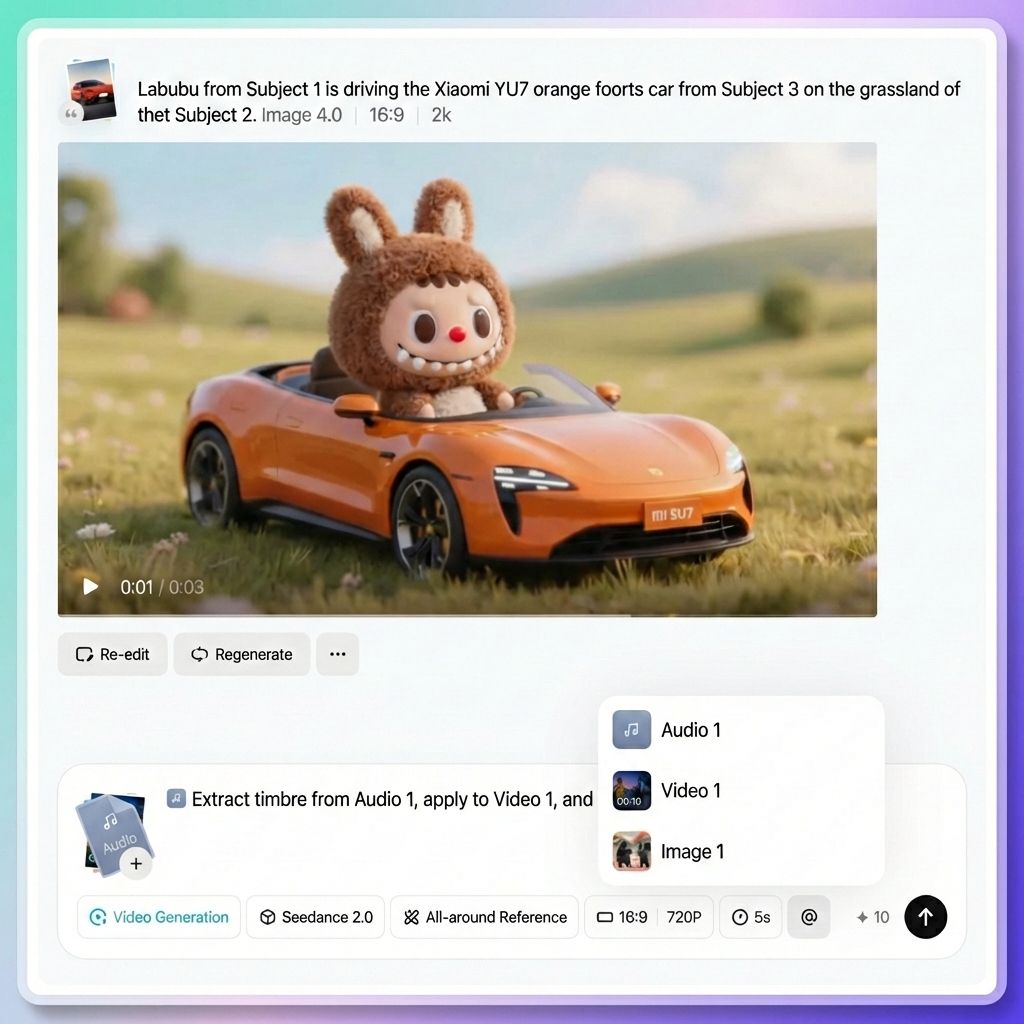
ขั้นตอนที่ 3. กำหนดบทบาทให้กับสินทรัพย์แต่ละรายการโดยใช้เครื่องหมาย “@” (ขั้นตอนที่สำคัญที่สุด)
นี่คือส่วนสำคัญของการโต้ตอบใน Seedance 2.0 และเป็นส่วนที่ผู้เริ่มต้นหลายคนมักมองข้ามไป
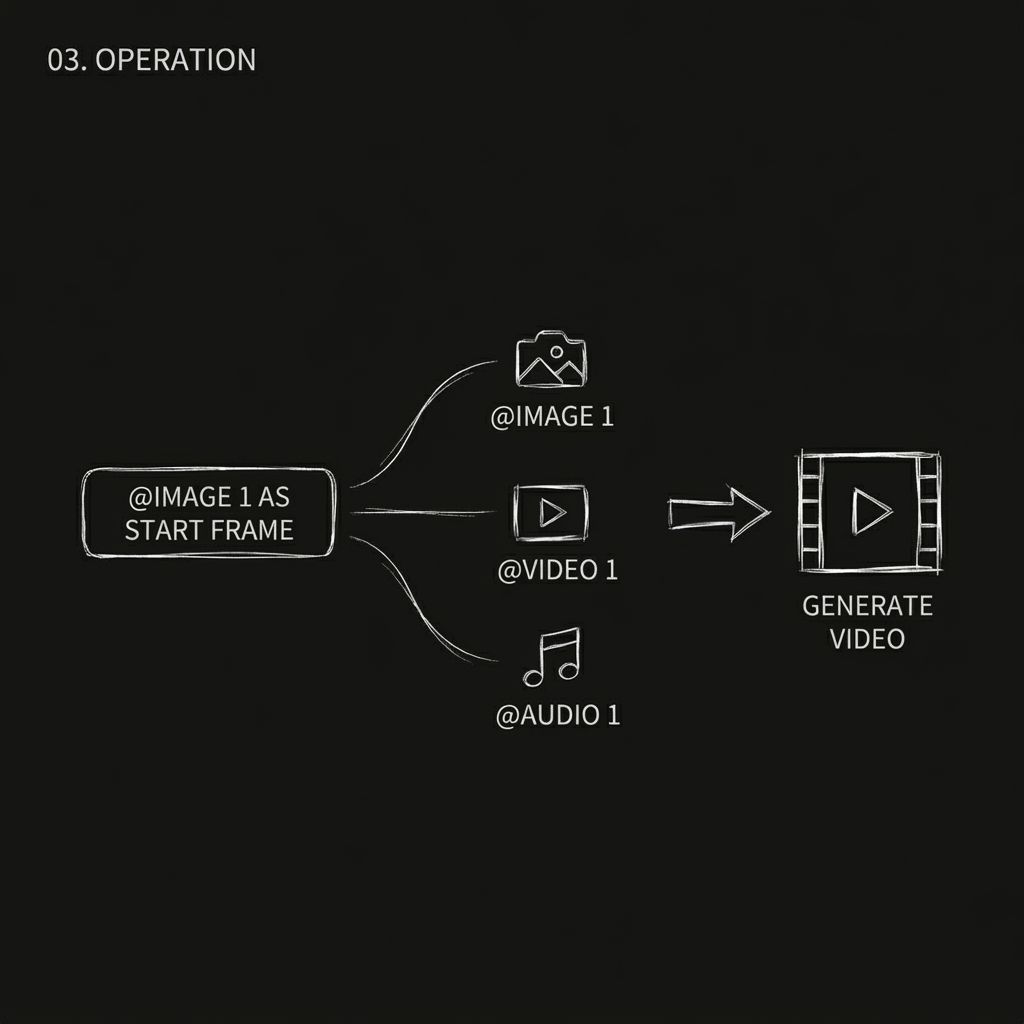
หลังจากอัปโหลดไฟล์ภาพแล้ว คุณต้องระบุให้โมเดลทราบอย่างชัดเจนว่าแต่ละไฟล์ใช้สำหรับอะไร โดยใช้ @asset name ในข้อความแจ้งเตือน โมเดลจะไม่เดา หากคุณไม่ระบุอย่างชัดเจน โมเดลอาจใช้ไฟล์ภาพอย่างไม่ถูกต้อง
ตัวอย่างเช่น:
- @ภาพที่ 1 เป็นเฟรมแรก
- @วิดีโอ 1 ใช้เป็นข้อมูลอ้างอิงกล้อง
- @Audio 1 สำหรับเพลงประกอบ
วิธีเรียกใช้งานเครื่องหมาย “@”
วิธีที่ 1
พิมพ์สัญลักษณ์ “@” ลงในช่องป้อนข้อมูลโดยตรง รายชื่อไฟล์ที่อัปโหลดทั้งหมดจะปรากฏขึ้น คลิกไฟล์ที่คุณต้องการอ้างอิง แล้วไฟล์นั้นจะถูกแทรกเข้าไปในข้อความแจ้งเตือน
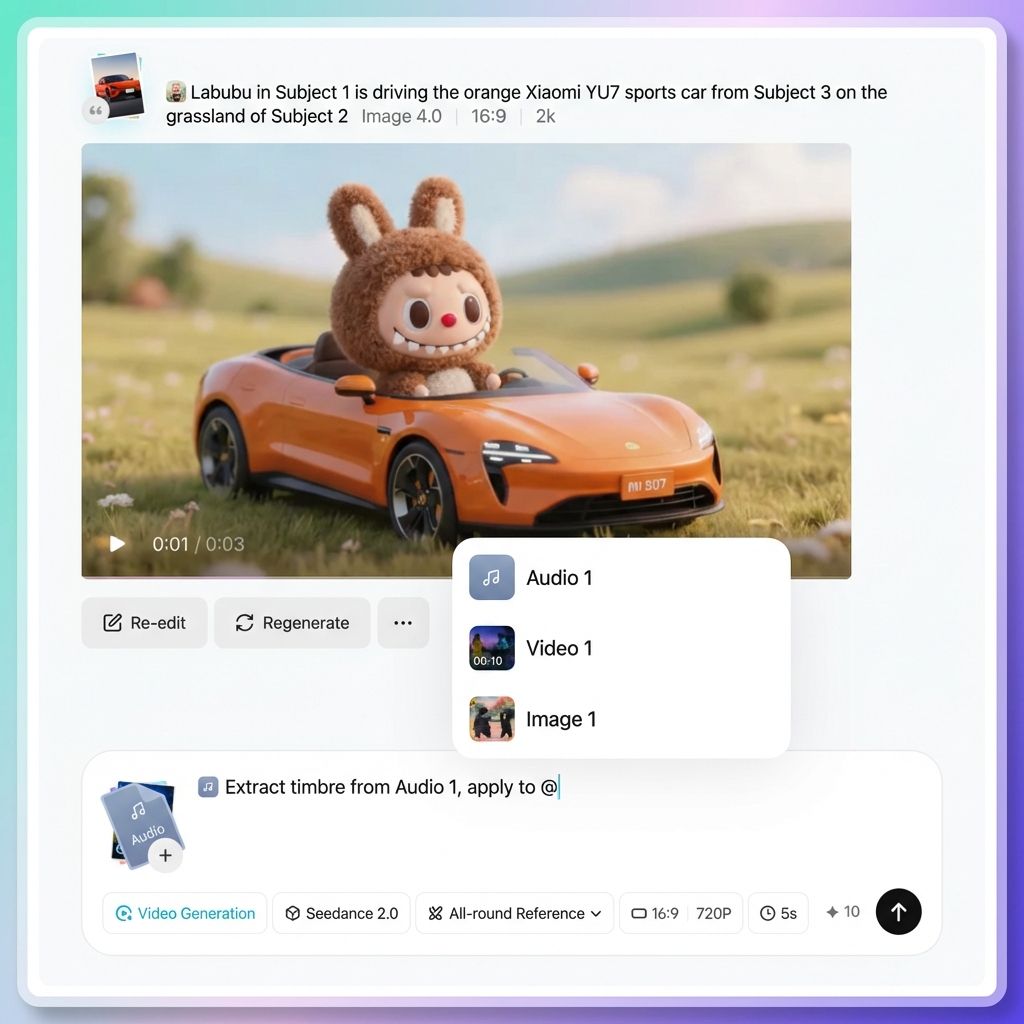
วิธีที่ 2
คลิกปุ่ม “@” ในแถบเครื่องมือพารามิเตอร์ที่อยู่ถัดจากช่องป้อนข้อมูล ซึ่งจะแสดงรายการสินทรัพย์ขึ้นมาด้วย
ตัวอย่างการใช้เครื่องหมาย “@” อย่างถูกต้อง
- ระบุเฟรมแรกและอ้างอิง: ใช้ @Image 1 เป็นเฟรมแรก อ้างอิงภาษาของกล้องเป็น @Video 1 และใช้ @Audio 1 สำหรับเพลงประกอบ
- ระบุบทบาทของตัวละคร: ตัวละครหญิงใน @Image 1 เป็นตัวละครหลัก และตัวละครชายใน @Image 2 เป็นตัวละครสมทบ
- ระบุจุดอ้างอิงการเคลื่อนไหวของกล้อง: อ้างอิงการเคลื่อนไหวและการเปลี่ยนฉากทั้งหมดของกล้องจาก @Video 1 อย่างครบถ้วน
- ระบุภาพอ้างอิง: ใช้ @Image 3 เป็นภาพอ้างอิงสำหรับฉากด้านซ้าย และใช้ @Image 4 เป็นภาพอ้างอิงสำหรับฉากด้านขวา
- ระบุการอ้างอิงการกระทำ: ตัวละครใน @Image 1 ควรแสดงท่าทางการเต้นตามแบบจาก @Video 1
- ระบุเสียงอ้างอิง: เสียงบรรยายควรอ้างอิงถึงโทนเสียงจาก @Video 1
ข้อผิดพลาดทั่วไปที่ควรระวัง
เมื่อคุณทำงานกับไฟล์จำนวนมาก ควรตรวจสอบให้แน่ใจเสมอว่าการอ้างอิง "@" ทุกครั้งตรงกับไฟล์ที่ถูกต้อง หากคุณอ้างอิงภาพเป็นวิดีโอ หรือเผลอกำหนดภาพของตัวละคร A ให้กับตัวละคร B ผลลัพธ์อาจผิดเพี้ยนไปอย่างรวดเร็ว
คุณสามารถเลื่อนเมาส์ไปวางเหนือไฟล์หรือข้อมูลอ้างอิงใดๆ ในข้อความแจ้งเตือนเพื่อดูตัวอย่างและตรวจสอบให้แน่ใจว่าทุกอย่างเชื่อมโยงอย่างถูกต้อง
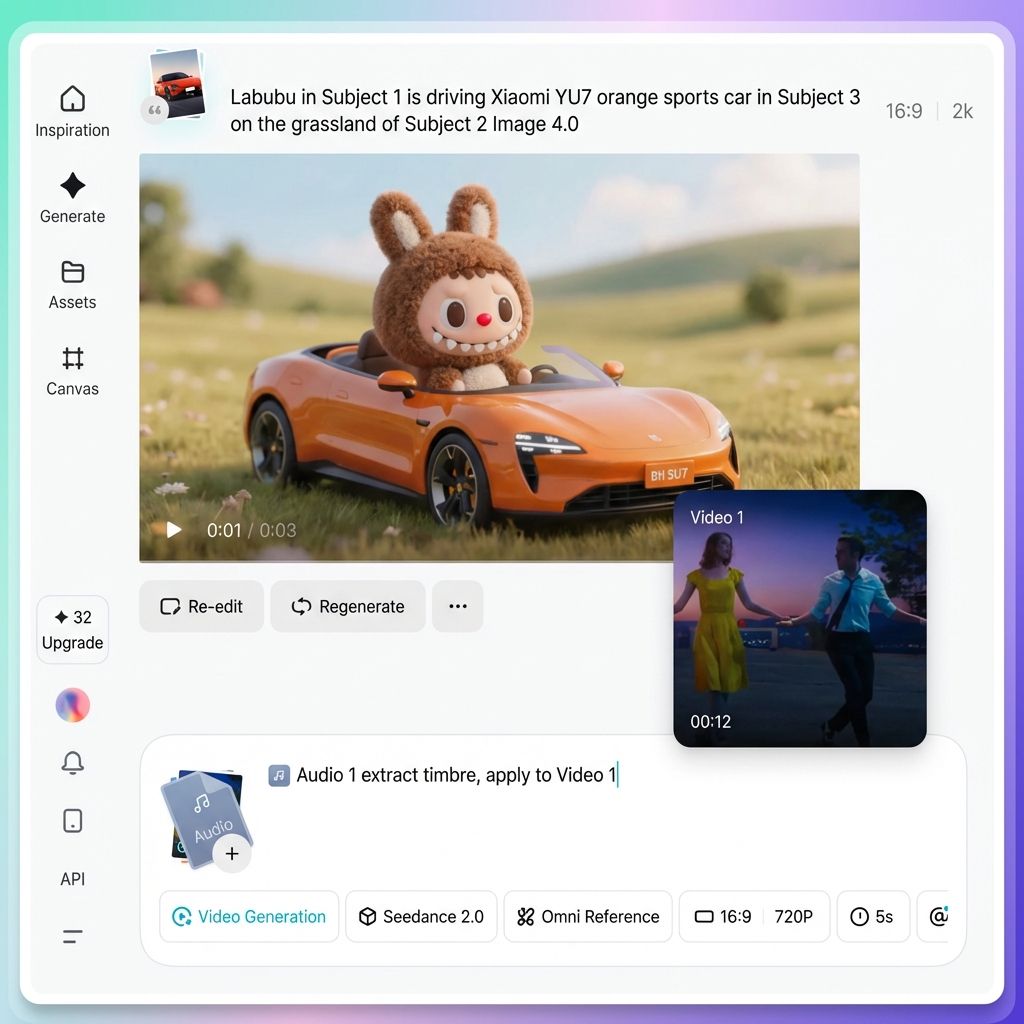
ขั้นตอนที่ 4. เขียนคำถามกระตุ้นความคิดที่ชัดเจนและมีประสิทธิภาพ
เมื่อคุณกำหนดบทบาทให้กับสินทรัพย์ทั้งหมดโดยใช้เครื่องหมาย “@” แล้ว ที่เหลือก็คือการอธิบายภาพและการกระทำที่คุณต้องการด้วยภาษาธรรมชาติ
นี่คือเคล็ดลับสี่ข้อที่นำไปใช้ได้จริงสำหรับการเขียนคำถามกระตุ้นความคิดที่ดีขึ้น

เคล็ดลับที่ 1. เขียนโดยใช้โครงสร้างแบบลำดับเวลา
หากวิดีโอของคุณมีหลายฉากหรือมีการเปลี่ยนเนื้อเรื่องหลายช่วง ควรแบ่งคำอธิบายออกเป็นส่วนๆ ตามช่วงเวลา
ตัวอย่างเช่น:
0–3 วินาที
พระเอกยกบอลบาสเก็ตบอลขึ้นในมือ มองขึ้นไปทางกล้อง แล้วพูดว่า “ผมแค่อยากดื่มอะไรสักหน่อย ผมกำลังจะเดินทางข้ามเวลาจริงๆเหรอเนี่ย?”
4–8 วินาที
กล้องสั่นอย่างรุนแรงกะทันหัน ฉากตัดไปที่คืนฝนตกในบ้านโบราณแห่งหนึ่ง นางเอกในชุดพื้นเมืองมองกล้องด้วยสีหน้าเย็นชา
9–13 วินาที
กล้องตัดไปที่ตัวละครตัวหนึ่งซึ่งแต่งกายด้วยชุดสมัยราชวงศ์หมิง…
การเขียนในลักษณะนี้ช่วยให้แบบจำลองเข้าใจจังหวะและเนื้อหาของแต่ละส่วนได้แม่นยำยิ่งขึ้น
เคล็ดลับที่ 2. ระบุให้ชัดเจนว่า “อ้างอิง” กับ “แก้ไข” นั้นแตกต่างกันอย่างไร
สองแนวคิดนี้ไม่เหมือนกัน
“อ้างอิงการเคลื่อนไหวของกล้องจาก @Video 1” หมายถึงการใช้รูปแบบการเคลื่อนไหวของกล้องนั้นเพื่อสร้างเนื้อหาใหม่
“แทนที่ตัวละครหญิงใน @Video 1 ด้วยนักแสดงโอเปร่าแบบดั้งเดิม” หมายถึงการแก้ไขวิดีโอต้นฉบับนั่นเอง
โปรดระบุให้ชัดเจนว่าคุณต้องการตัวเลือกใด เพื่อให้โมเดลสามารถตอบสนองได้อย่างถูกต้อง
เคล็ดลับที่ 3. ระบุรายละเอียดให้ชัดเจนในภาษาของกล้อง
ไม่ต้องกังวลเรื่องการเขียนมากเกินไป ตอนนี้โมเดลมีความเข้าใจภาษาของกล้องเป็นอย่างดีแล้ว
การผลัก การดึง การแพน การติดตาม การดอลลี่ การหมุนรอบแกน การถ่ายภาพจากด้านบน การถ่ายภาพมุมต่ำ การถ่ายภาพแบบเทคเดียว การซูมแบบฮิตช์ค็อก เลนส์ฟิชอาย มันเข้าใจศัพท์เฉพาะทางระดับมืออาชีพเหล่านี้ทั้งหมด
หากคุณไม่คุ้นเคยกับศัพท์เทคนิคก็ไม่เป็นไร คำอธิบายธรรมดาก็ใช้ได้เช่นกัน เช่น “กล้องค่อยๆ เคลื่อนจากด้านหลังตัวละครมาด้านหน้า”
เคล็ดลับที่ 4. เพิ่มเอฟเฟ็กต์การเปลี่ยนผ่านสำหรับการกระทำต่อเนื่อง
หากคุณต้องการให้ตัวละครแสดงการกระทำต่อเนื่องกันหลายขั้นตอน โปรดอธิบายการเปลี่ยนผ่านแต่ละขั้นตอนให้ชัดเจน
ตัวอย่างเช่น “ตัวละครเปลี่ยนท่าจากกระโดดไปเป็นการกลิ้งตัวโดยตรง ทำให้การเคลื่อนไหวต่อเนื่องและลื่นไหล” ซึ่งจะช่วยหลีกเลี่ยงการตัดต่อแบบกระทันหันที่ไม่เป็นธรรมชาติในวิดีโอฉบับสมบูรณ์
ขั้นตอนที่ 5. เลือกช่วงเวลาและสร้าง
เลือกความยาววิดีโอที่คุณต้องการได้ตั้งแต่ 4 ถึง 15 วินาที
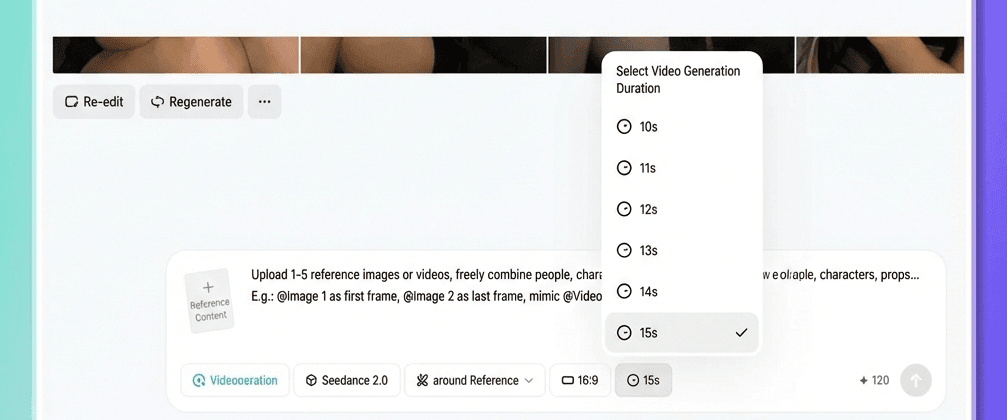
ข้อควรทราบที่สำคัญอย่างหนึ่ง:
หากคุณกำลังขยายวิดีโอที่มีอยู่แล้ว เช่น เพิ่มอีกห้าวินาทีให้กับส่วนท้ายของคลิป ระยะเวลาที่คุณเลือกในที่นี้จะหมายถึงเฉพาะส่วนที่สร้างขึ้นใหม่เท่านั้น ไม่ใช่ความยาวทั้งหมดของวิดีโอ หากคุณต้องการขยายวิดีโอออกไปห้าวินาที ให้เลือกห้าวินาที
จากนั้นคลิก สร้าง และรอผลลัพธ์
หากคุณไม่พอใจ คุณสามารถสร้างผลลัพธ์ซ้ำได้หลายครั้ง ผลลัพธ์จาก AI มีองค์ประกอบของความสุ่ม ดังนั้นแม้จะใช้ข้อมูลป้อนเข้าเดียวกัน ผลลัพธ์แต่ละครั้งก็อาจแตกต่างกันเล็กน้อย เพียงแค่เลือกเวอร์ชันที่คุณชอบที่สุด
เจาะลึกความสามารถหลักของ Seedance 2.0
ด้านล่างนี้คือความสามารถที่ทรงพลังที่สุดสิบประการของ Seedance 2.0 แต่ละความสามารถมาพร้อมกับคำแนะนำการใช้งานจริงและตัวอย่างประกอบ
ความสามารถที่ 1. การพัฒนาคุณภาพของภาพอย่างก้าวกระโดด
เรามาเริ่มต้นจากพื้นฐานกันก่อน
Seedance 2.0 ได้รับการอัปเกรดพื้นฐานอย่างเต็มรูปแบบ ระบบฟิสิกส์มีความแม่นยำมากขึ้น การเคลื่อนไหวราบรื่นขึ้น และรูปแบบภาพมีความสอดคล้องกันตลอดทั้งฉาก
ในระดับพื้นฐานที่สุดของการสร้างภาพ มีความก้าวหน้าเชิงคุณภาพเกิดขึ้นอย่างมาก:
- ระบบฟิสิกส์สมจริงยิ่งขึ้น : การเคลื่อนไหวของเสื้อผ้า การกระเด็นของน้ำ และการชนกันของวัตถุ ล้วนแสดงพฤติกรรมที่เป็นธรรมชาติมากขึ้น
- การเคลื่อนไหวที่ราบรื่นและเป็นธรรมชาติยิ่งขึ้น : การเดิน การวิ่ง และแม้แต่การเคลื่อนไหวที่ซับซ้อนก็ไม่ดูแข็งทื่อหรือเหมือนหุ่นยนต์อีกต่อไป
- ความเข้าใจคำสั่งที่แม่นยำยิ่งขึ้น : หากคุณพูดว่า “เด็กผู้หญิงคนหนึ่งกำลังแขวนผ้าอย่างสง่างาม” ระบบจะเข้าใจความหมายของคำว่า “สง่างาม” อย่างแท้จริง
- ความสม่ำเสมอของสไตล์ที่เสถียรยิ่งขึ้น : สไตล์ภาพยังคงสอดคล้องกันตั้งแต่ต้นจนจบ โดยไม่มีการเปลี่ยนแปลงอย่างกะทันหัน

ตัวอย่างการใช้งาน
เด็กหญิงคนหนึ่งตากผ้าอย่างสง่างาม หลังจากตากผ้าชิ้นหนึ่งเสร็จ เธอก็หยิบผ้าอีกชิ้นจากถังแล้วเขย่าอย่างแรง
สิ่งนี้หมายความว่าอย่างไรในทางปฏิบัติ?
เมื่อคุณสร้างฉากอย่างเช่น “หญิงสาวกำลังแขวนผ้าอย่างสง่างาม จากนั้นหยิบผ้าอีกผืนจากถังแล้วเขย่าอย่างแรง” การเคลื่อนไหวของผ้า แรงในแขนของเธอ และพื้นผิวของผ้าทั้งหมดนั้นให้ความรู้สึกใกล้เคียงกับภาพจริงอย่างน่าทึ่ง
ฉากที่ซับซ้อนกว่านี้ก็สามารถทำได้เช่นกัน
กล้องจับภาพชายคนหนึ่งที่สวมชุดดำวิ่งหนีด้วยความเร็วสูง กลุ่มคนวิ่งไล่ตามเขาจากด้านหลัง ภาพเปลี่ยนไปเป็นมุมมองด้านข้าง ด้วยความตกใจ เขาชนเข้ากับแผงขายผลไม้ริมถนน ล้มลง ลุกขึ้น และวิ่งต่อไป
ฉากต่างๆ ที่เกี่ยวข้องกับการไล่ล่า การชน และการเปลี่ยนมุมกล้องแบบไดนามิก สามารถสร้างได้อย่างสม่ำเสมอในเวอร์ชัน 2.0 แล้ว
ยังมีตัวอย่างที่เหนือความคาดหมายอีกมากมาย บางผู้สร้างใช้เพียงคำสั่งเดียวในการสร้างภาพตัวละครในภาพวาดที่แอบเอื้อมมือไปหยิบกระป๋องโคลา ดื่มไปเล็กน้อย แล้วรีบวางกระป๋องกลับที่เดิมเมื่อได้ยินเสียงฝีเท้า จากนั้นภาพก็ค่อยๆ ซูมเข้าไปใกล้ฉากหลังสีดำ โดยมีเพียงกระป๋องโคลาพร้อมคำบรรยายประกอบภาพ ความซับซ้อนของการเล่าเรื่องในระดับนี้แทบจะเป็นไปไม่ได้เลยในอดีต
ความสามารถที่ 2. การผสมผสานหลายรูปแบบอย่างอิสระ
นี่คือการอัปเกรดที่สำคัญที่สุดในเวอร์ชัน 2.0 คุณสามารถใช้สื่อประเภทใดก็ได้เป็นแหล่งอ้างอิงได้แล้ว
สูตรดังกล่าวสามารถสรุปได้ดังนี้:
Seedance 2.0 = การอ้างอิงแบบหลายรูปแบบ + การสร้างสรรค์ที่แข็งแกร่ง + ความเข้าใจคำแนะนำที่แม่นยำ
คุณสามารถอ้างอิงได้จาก:
- การกระทำ เอฟเฟกต์ และรูปแบบภาพ
- การเคลื่อนไหวของกล้องและรูปแบบการถ่ายทำ
- ลักษณะตัวละครและสไตล์ฉาก
- เสียงและจังหวะดนตรี

เคล็ดลับที่นำไปใช้ได้จริง
| สิ่งที่คุณต้องการทำ | วิธีการเขียนโจทย์ |
| มีภาพคีย์เฟรมและต้องการอ้างอิงการเคลื่อนไหวในวิดีโอ | "@ใช้ภาพที่ 1 เป็นคีย์เฟรม อ้างอิงการสั่นของกล้องจาก @วิดีโอ 1" |
| ขยายวิดีโอที่มีอยู่ | "ขยาย @Video 1 ออกไปอีก 5 วินาที" (ตั้งค่าระยะเวลาการสร้างเป็น 5 วินาที) |
| รวมวิดีโอหลายๆ คลิปเข้าด้วยกัน | "แทรกฉากระหว่าง @Video 1 และ @Video 2 เนื้อหาคือ xxx" |
| ใช้เสียงจากวิดีโอ | ไม่จำเป็นต้องอัปโหลดไฟล์เสียงแยกต่างหาก เพียงแค่อ้างอิงถึงวิดีโอโดยตรง |
| การดำเนินการอย่างต่อเนื่อง | "ตัวละครเปลี่ยนท่าจากกระโดดไปเป็นการกลิ้งตัวโดยตรง รักษาการเคลื่อนไหวให้ราบรื่นและต่อเนื่อง" |
ความสามารถที่ 3: การปรับปรุงความสม่ำเสมออย่างมีนัยสำคัญ
ใครก็ตามที่เคยทำงานกับวิดีโอ AI จะรู้ว่าความสม่ำเสมอเป็นปัญหาที่น่าหงุดหงิดที่สุด
ใบหน้าเปลี่ยนไปในแต่ละช็อต รายละเอียดสินค้าหายไปเมื่อเปลี่ยนมุมกล้อง และรูปแบบของฉากก็เปลี่ยนไปอย่างกะทันหัน
เวอร์ชัน 2.0 พยายามอย่างจริงจังที่จะแก้ไขปัญหานี้
หลังจากอัปโหลดภาพอ้างอิงตัวละครแล้ว รูปลักษณ์ เสื้อผ้า และท่าทางของบุคคลนั้นจะคงที่ตลอดทั้งวิดีโอ เช่นเดียวกับการนำเสนอผลิตภัณฑ์ เมื่อหมุนกระเป๋าจากหลายมุม รายละเอียดด้านหน้า ด้านข้าง และวัสดุยังคงเหมือนเดิม
องค์ประกอบที่สามารถคงที่ได้:
- ลักษณะใบหน้า (โครงสร้างใบหน้า สีผิว รูปแบบการแสดงออกทางสีหน้า)
- รายละเอียดของเสื้อผ้า (เนื้อผ้า สี ลวดลาย)
- องค์ประกอบของแบรนด์ (โลโก้, รูปแบบตัวอักษร, โทนสี)
- สไตล์ของฉาก (แสง บรรยากาศ โทนสี)
ตัวอย่างการใช้งาน
ชายคนหนึ่งในภาพที่ 1 เดินลงมาตามทางเดินหลังเลิกงาน ดูเหนื่อยล้ามาก เขาค่อยๆ เดินช้าลง หยุดอยู่ที่หน้าประตูบ้าน หายใจเข้าลึกๆ เพื่อตั้งสติ ค้นหากุญแจ ไขประตู แล้วเดินเข้าไป ลูกสาวตัวน้อยและสุนัขของเขาวิ่งเข้ามาหาเขาอย่างมีความสุขและกอดเขา

โดยอ้างอิงจาก @Image1 ลักษณะของตัวละครยังคงสม่ำเสมอในลำดับภาพทั้งหมด
ความสามารถที่ 4: การเคลื่อนไหวของกล้องที่แม่นยำและการจำลองการกระทำ
นี่เป็นหนึ่งในคุณสมบัติที่ถูกพูดถึงมากที่สุดของเวอร์ชัน 2.0
ในอดีต หากคุณต้องการให้ AI เลียนแบบการเคลื่อนไหวของกล้องในภาพยนตร์ คุณต้องเขียนรายการคำศัพท์ทางเทคนิคยาวเหยียดและหวังว่ามันจะใช้งานได้ หรือไม่ก็มันจะไม่ได้ผลเลย
ตอนนี้เหลือแค่สองขั้นตอนเท่านั้น:
อัปโหลดวิดีโอตัวอย่างที่มีการเคลื่อนไหวของกล้องที่คุณชื่นชอบ จากนั้นเขียนว่า:
“อ้างอิงการเคลื่อนไหวของกล้องจาก @Video1”
โมเดลจะวิเคราะห์ตรรกะของกล้องในวิดีโอต้นแบบ (การซูมเข้า ซูมออก แพนกล้อง ติดตามกล้อง หมุนกล้อง ซูม ถ่ายภาพต่อเนื่อง ฯลฯ) และนำรูปแบบการเคลื่อนไหวเดียวกันไปใช้กับเนื้อหาใหม่ของคุณ
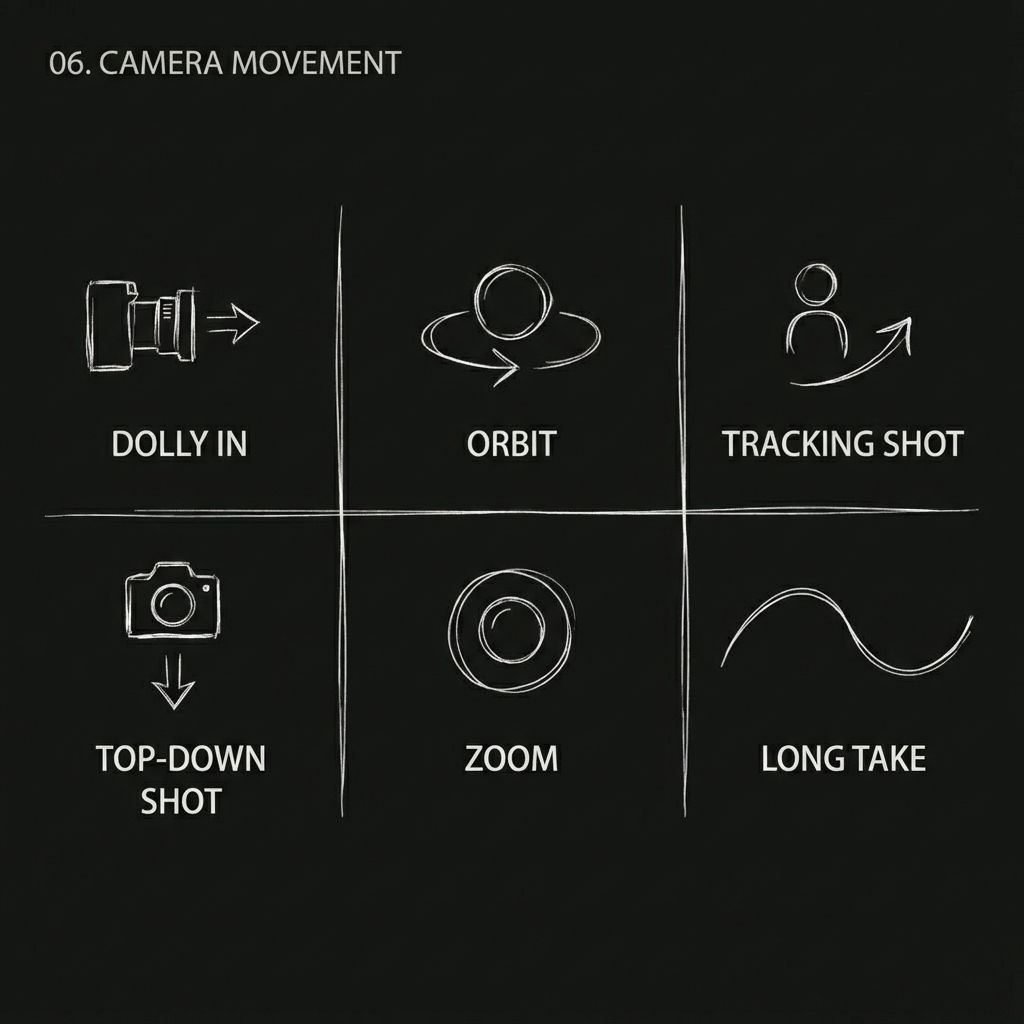
การเคลื่อนไหวของกล้องที่สามารถเลียนแบบได้:
- ซูมแบบฮิตช์ค็อก
- ภาพถ่ายติดตามวงโคจร
- ถ่ายทำต่อเนื่องโดยไม่ถ่ายซ้ำ
- การถ่ายภาพแบบ Push / Pull / Pan / Tracking
- ภาพถ่ายมุมต่ำ
- ภาพมุมสูงจากด้านบน
ตัวอย่าง: การจำลองฉากจากภาพยนตร์กำลังภายในคลาสสิก
ความสามารถที่ 5 การสร้างแม่แบบและเอฟเฟ็กต์สร้างสรรค์ขึ้นใหม่ได้อย่างแม่นยำ
เห็นคอนเซ็ปต์โฆษณาเจ๋งๆ เอฟเฟ็กต์การเปลี่ยนฉาก หรือคลิปวิดีโอที่ถูกใจไหม?
อัปโหลดโดยตรงเพื่อใช้เป็นข้อมูลอ้างอิง โมเดลจะสามารถระบุจังหวะการเคลื่อนไหว โครงสร้างภาพ และภาษาของกล้องภายในภาพนั้น และช่วยให้คุณสร้างเวอร์ชันของคุณเองได้
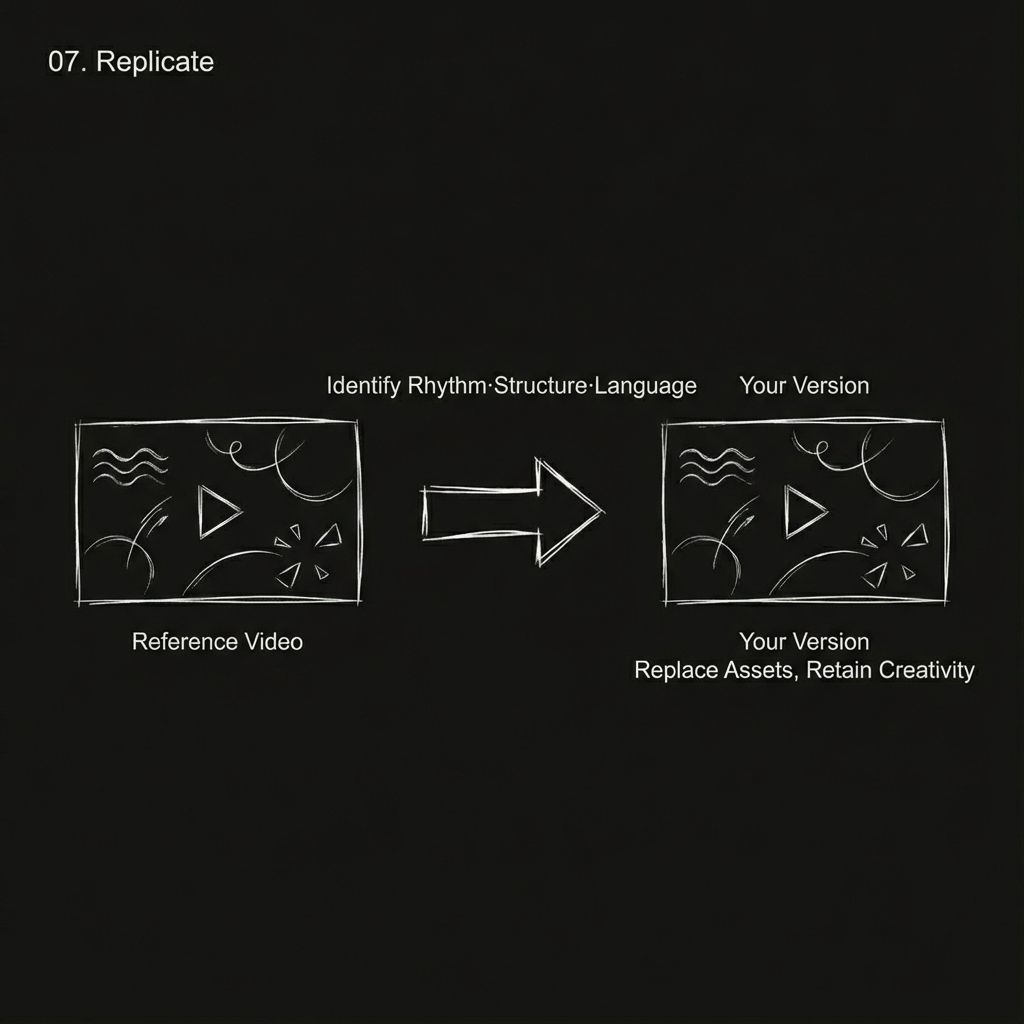
ประเภทของเนื้อหาเชิงสร้างสรรค์ที่สามารถนำมาสร้างใหม่ได้:
- การเปลี่ยนฉากที่สร้างสรรค์ เช่น การแตกกระจายของชิ้นส่วนปริศนา การกระจายตัวของอนุภาค และการเปลี่ยนฉากแบบพอร์ทัลสไตล์ม่านตา
- รูปแบบโฆษณาสำเร็จรูป
- การตัดต่อจังหวะแบบ MV
- ฉากเทคนิคพิเศษในภาพยนตร์
- เอฟเฟ็กต์การแปลงชุดและการสลับใบหน้า
ตัวอย่าง:
เอฟเฟกต์พิเศษถูกตั้งค่าสูงสุดแล้ว…
ความสามารถที่ 6. การขยายและการต่อวิดีโอ
มีวิดีโอที่ถูกใจอยู่แล้วและอยากต่อเรื่องราวให้สมบูรณ์ยิ่งขึ้นใช่ไหม? หรืออาจจะอยากเพิ่มเรื่องราวเบื้องหลังก่อนคลิปที่มีอยู่แล้ว? ฟีเจอร์การต่อขยายวิดีโอช่วยจัดการได้ทั้งสองอย่าง
ยื่นไปข้างหน้า
อัปโหลดวิดีโอที่มีอยู่แล้ว และเขียนว่า “ขยาย @Video 1 ออกไปอีก X วินาที” ตามด้วยคำอธิบายของฉากใหม่ที่คุณต้องการสร้าง
ยื่นไปข้างหลัง
เขียนว่า “ขยายเวลา X วินาทีก่อน” แล้วเพิ่มคำอธิบายเกี่ยวกับเหตุการณ์ก่อนหน้าที่คุณต้องการสร้าง
ข้อกำหนดการใช้งาน
บอกโมเดลให้ชัดเจนว่า: “ขยายเวลา @Video 1 ออกไปอีก X วินาที”
เมื่อทำการสร้าง ให้เลือกช่วงเวลาเท่ากับความยาวของส่วนขยาย ตัวอย่างเช่น หากคุณต้องการขยายออกไปห้าวินาที ให้เลือกห้าวินาทีเป็นความยาวในการสร้าง
คุณสามารถเพิ่มองค์ประกอบเนื้อเรื่องใหม่และคำอธิบายภาพในส่วนเพิ่มเติมได้
รองรับทั้งการต่อขยายไปข้างหน้าและข้างหลัง
ตัวอย่างการใช้งาน
โดยการอ้างอิงรูปภาพและวิดีโอ คลิปต้นฉบับสองวินาทีข้างต้นสามารถขยายให้ยาวเป็นสิบห้าวินาทีได้
ส่วนที่ขยายออกไปสามารถอธิบายได้อย่างละเอียด รวมถึงการเคลื่อนไหวของกล้อง องค์ประกอบภาพ และข้อความบนหน้าจอ
ความสามารถที่ 7. เสียงสมจริงยิ่งขึ้น
วิดีโอที่สร้างด้วยเวอร์ชัน 2.0 มาพร้อมกับเอฟเฟกต์เสียงและเพลงประกอบในตัว และคุณภาพเสียงโดยรวมได้รับการปรับปรุงอย่างมากเมื่อเทียบกับเวอร์ชันก่อนหน้า
ต่อไปนี้เป็นตัวอย่างการใช้งานที่เกี่ยวข้องกับเสียงหลายประการ
การอ้างอิงน้ำเสียง
อัปโหลดคลิปวิดีโอหรือเสียง แล้วให้โมเดลเลียนแบบน้ำเสียงหรือสไตล์การบรรยายจากคลิปนั้น
การสนทนาหลายภาษา
ตัวละครสามารถพูดภาษาจีน อังกฤษ สเปน เกาหลี และภาษาอื่นๆ ได้ การแสดงอารมณ์ทำได้ค่อนข้างดี
บทสนทนาหลายตัวละคร
วิดีโอหนึ่งคลิปสามารถมีตัวละครได้หลายตัว โดยแต่ละตัวพูดบทพูดของตนเอง ตัวอย่างที่ประสบความสำเร็จ ได้แก่ รายการทอล์คโชว์ระหว่างแมวกับสุนัข บทสนทนาในละครย้อนยุค และบทสนทนาทางยุทธวิธีทางการทหาร
การสนับสนุนภาษาถิ่น
ผู้สร้างบางคนประสบความสำเร็จในการสร้างตัวละครที่พูดสำเนียงเสฉวนขณะสั่งชานม ผลลัพธ์ที่ได้ดูสมจริงอย่างน่าประหลาดใจ
การจับคู่เอฟเฟกต์เสียง
เสียงฝีเท้า เสียงฟ้าร้อง เสียงฝูงชน เสียงอุปกรณ์กระทบกัน และเสียงสภาพแวดล้อมอื่นๆ สามารถสร้างขึ้นได้ด้วยความแม่นยำในระดับที่เหมาะสม
ความสามารถที่ 8. การถ่ายทำแบบเทคเดียวที่ต่อเนื่องและสมบูรณ์ยิ่งขึ้น
การถ่ายทำแบบ "เทคเดียวจบ" จำเป็นต้องให้ฉากคงความต่อเนื่องเป็นเวลานาน พร้อมทั้งจัดการกับการเปลี่ยนผ่านเชิงพื้นที่และการเคลื่อนไหวของกล้องที่ซับซ้อน ซึ่งเป็นความท้าทายที่ยากลำบากสำหรับ AI มาโดยตลอด
Seedance 2.0 มีความก้าวหน้าอย่างเห็นได้ชัดในด้านนี้ หากคุณอัปโหลดภาพหลายภาพจากฉากต่างๆ และเขียนข้อความเช่น "ภาพถ่ายต่อเนื่องที่ติดตามนักวิ่งจากถนนขึ้นบันได ผ่านทางเดิน ไปยังดาดฟ้า และสุดท้ายมองเห็นวิวเมือง" โมเดลจะสามารถเปลี่ยนฉากได้อย่างเป็นธรรมชาติโดยไม่มีการหยุดชะงักที่เห็นได้ชัด
นอกจากนี้ยังสามารถสร้างฉากถ่ายทำแบบเทคเดียวที่ซับซ้อนกว่าได้อีกด้วย ตัวอย่างเช่น “จากมุมมองบุคคลที่หนึ่ง มองผ่านหน้าต่างเครื่องบินที่เมฆกลายเป็นไอศกรีม จากนั้นดึงกล้องกลับเข้าไปในห้องโดยสารขณะที่ตัวละครหยิบไอศกรีมขึ้นมาและกัดกิน”
แม้แต่ฉากถ่ายทำแบบเทคเดียวจบ ที่มีการเปลี่ยนมุมมองและผสมผสานความสมจริงกับจินตนาการ Seedance 2.0 ก็สามารถจัดการได้
นอกจากนี้ยังมีฉากถ่ายทำแบบเทคเดียวจบสไตล์หนังสายลับระทึกขวัญ กล้องติดตามสายลับหญิงในชุดสีแดงที่เคลื่อนตัวผ่านฝูงชน เธอเลี้ยวเข้ามุมและพบกับหญิงสาวสวมหน้ากาก จากนั้นก็ติดตามต่อไปยังคฤหาสน์ที่เป้าหมายหายตัวไป โดยไม่มีการตัดต่อแม้แต่ครั้งเดียว
การสร้างความเข้มข้นของเรื่องราวในระดับนี้ได้ในช็อตเดียวถือว่าน่าประทับใจมากแล้ว
ตัวอย่างการใช้งาน
@Image1 @Image2 @Image3 @Image4 @Image5 เป็นภาพถ่ายต่อเนื่องที่ติดตามนักวิ่งจากถนนขึ้นบันได ผ่านทางเดิน ไปยังดาดฟ้า และสุดท้ายก็มองเห็นทิวทัศน์ของเมือง
เคล็ดลับ
จัดเรียงภาพหลายภาพตามลำดับ นางแบบจะนำเสนอฉากเหล่านี้ตามลำดับภายในภาพต่อเนื่อง
ความสามารถที่ 9. การตัดต่อวิดีโอด้วย AI
มีวิดีโออยู่แล้วและไม่อยากเริ่มใหม่ทั้งหมด แต่ต้องการแก้ไขเพียงบางส่วนใช่ไหม? ตอนนี้คุณสามารถใช้วิดีโอที่มีอยู่เป็นอินพุตและทำการแก้ไขเฉพาะส่วนได้แล้ว
การแทนที่ตัวละคร
แทนที่ตัวละคร A ในวิดีโอด้วยตัวละคร B โดยคงการกระทำและสีหน้าท่าทางเดิมไว้ ตัวอย่างเช่น “แทนที่นักร้องนำหญิงในวิดีโอ 1 ด้วยนักแสดงนำชายจากภาพที่ 1 โดยเลียนแบบการเคลื่อนไหวเดิมทั้งหมด”
การพลิกผันพล็อต
คงฉากและตัวละครไว้เหมือนเดิม แต่เขียนเนื้อเรื่องใหม่ทั้งหมด ผู้สร้างบางคนเปลี่ยนฉากชมพระจันทร์สุดโรแมนติกบนสะพานให้กลายเป็นฉากหักมุมสุดดราม่าที่พระเอกผลักนางเอกตกน้ำ ในขณะที่บางคนเปลี่ยนฉากเจรจาต่อรองตึงเครียดในบาร์ให้กลายเป็นฉากตลกที่ใครบางคนหยิบถุงขนมขนาดใหญ่ออกมาแทน
การปรับเปลี่ยนองค์ประกอบ
เปลี่ยนทรงผม เพิ่มอุปกรณ์ประกอบฉาก หรือเปลี่ยนฉากหลัง ตัวอย่างเช่น “เปลี่ยนทรงผมของผู้หญิงในวิดีโอ 1 ให้เป็นผมยาวสีแดง และให้ฉลามขาวตัวใหญ่จาก @Image 1 ค่อยๆ โผล่ขึ้นมาครึ่งตัวด้านหลังเธอ”
การผสานรวมแบรนด์
แทรกองค์ประกอบของแบรนด์ลงในวิดีโอที่มีอยู่แล้ว ตัวอย่างเช่น เพิ่มภาพระยะใกล้ของถุงกระดาษที่มีโลโก้แบรนด์ลงในวิดีโอไก่ทอด
ตัวอย่าง — การแทนที่ตัวอักษร:
สร้างตัวละครจากตำนานดำ: วูคง แล้วให้เขาต่อสู้กับกัปตันอเมริกา
ความสามารถที่ 10: การตัดต่อที่ซิงค์กับจังหวะดนตรี
อัปโหลดวิดีโอเพลงที่มีจังหวะเป็นตัวอย่าง โมเดลสามารถตรวจจับการเปลี่ยนแปลงของจังหวะและตัดฉากให้ตรงกับจังหวะได้อย่างแม่นยำ
การซิงค์จังหวะพื้นฐาน
อัปโหลดภาพประกอบและวิดีโอตัวอย่างเพลง จากนั้นเขียนข้อความดังนี้:
“ซิงค์ภาพให้เข้ากับจังหวะของ @Video”
การซิงค์จังหวะแบบไดนามิก
เขียน:
“ทำให้ตัวละครมีชีวิตชีวามากขึ้น เสริมสไตล์ภาพที่ชวนฝันโดยรวม เพิ่มความตึงเครียดทางภาพ และปรับขนาดภาพตามความเหมาะสมโดยอิงจากดนตรี”
การซิงค์จังหวะของภูมิทัศน์
เมื่อต้องการนำภาพทิวทัศน์หลายภาพมาประกอบกับเพลง ให้เขียนว่า:
“ฉากทิวทัศน์อ้างอิงถึงจังหวะของ @Video และซิงค์การเปลี่ยนฉากให้เข้ากับสไตล์ภาพและจังหวะดนตรี”
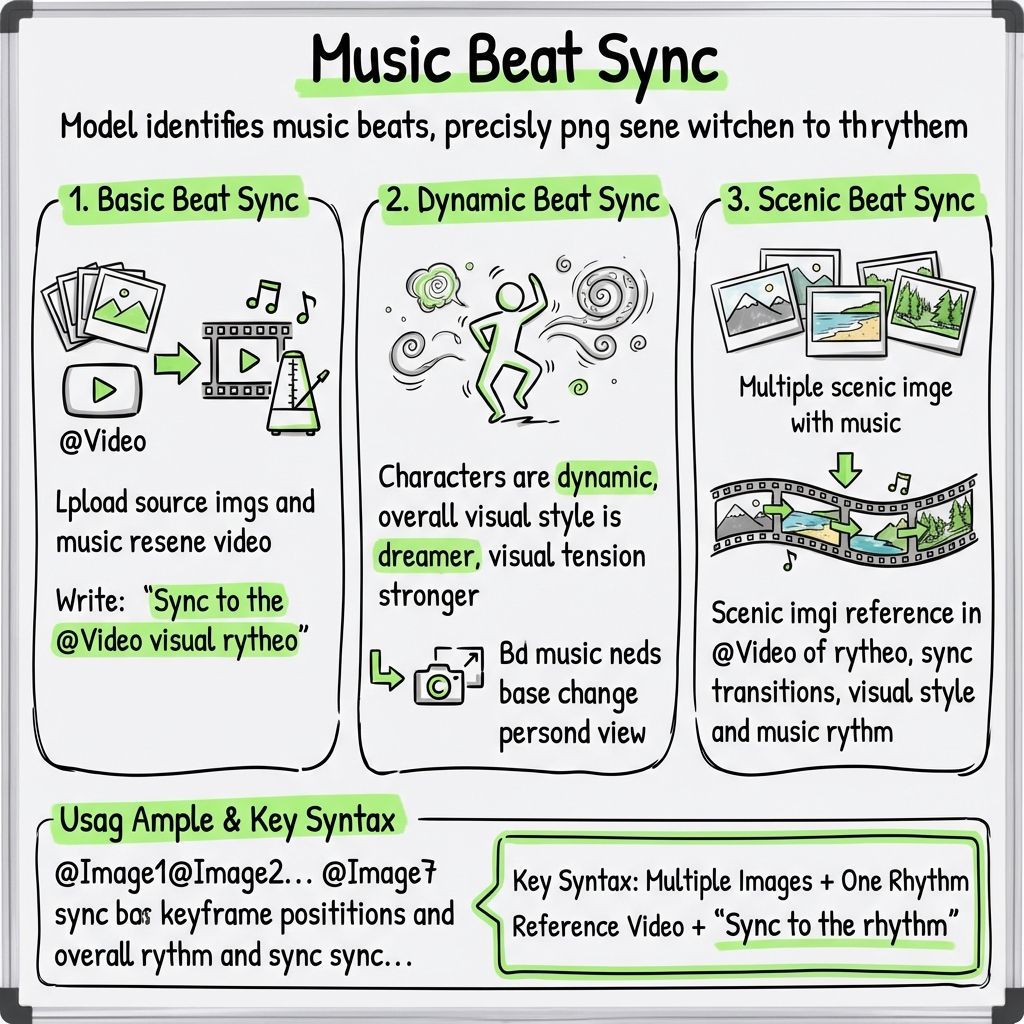
ตัวอย่างการใช้งาน
@Image1 @Image2 @Image3 @Image4 @Image5 @Image6 @Image7
ซิงค์ภาพเหล่านี้ให้ตรงกับตำแหน่งคีย์เฟรมและจังหวะโดยรวมของ @Video ทำให้ตัวละครดูมีชีวิตชีวามากขึ้น และให้สไตล์ภาพโดยรวมดูเหมือนฝันมากขึ้น
สูตรสำคัญ
ภาพหลายภาพ + วิดีโออ้างอิงจังหวะหนึ่งรายการ + “ซิงค์ให้ตรงกับจังหวะ”
ความสามารถที่ 11. การแสดงออกทางอารมณ์ที่น่าเชื่อถือยิ่งขึ้น
การแสดงออกทางสีหน้าที่แข็งทื่อและการเปลี่ยนอารมณ์ที่ไม่เป็นธรรมชาติเป็นปัญหาที่พบได้ทั่วไปในวิดีโอที่สร้างโดย AI มานานแล้ว เวอร์ชัน 2.0 แสดงให้เห็นถึงการปรับปรุงที่ชัดเจนในด้านนี้
คุณสามารถอัปโหลดวิดีโอเพื่อใช้เป็นข้อมูลอ้างอิงทางอารมณ์ และให้แบบจำลองเลียนแบบการเปลี่ยนแปลงสีหน้าจากวิดีโอนั้นได้ ตัวอย่างเช่น “ผู้หญิงใน @Image 1 เดินไปที่กระจก หยุดคิดอยู่ครู่หนึ่ง แล้วก็ร้องไห้ออกมาอย่างกะทันหัน การกระทำของการจับกระจกและความรุนแรงทางอารมณ์ของการระเบิดอารมณ์นั้น ควรอ้างอิงจาก @Video 1 อย่างเต็มที่”

คุณยังสามารถอธิบายการเปลี่ยนแปลงทางอารมณ์ได้อย่างแม่นยำด้วยข้อความ ตัวอย่างเช่น การเปลี่ยนจากอ่อนโยนเป็นเย็นชา จากตึงเครียดเป็นผ่อนคลาย หรือจากโกรธเป็นโล่งใจ โมเดลสามารถเข้าใจการเปลี่ยนแปลงทางอารมณ์เหล่านี้และสะท้อนออกมาผ่านทางสีหน้า ภาษากาย และน้ำเสียงได้
มันยังสามารถรับมือกับการแสดงออกที่เกินจริงในเชิงตลกได้อีกด้วย ตัวอย่างเช่น “ตัวละครเงยหน้าขึ้นมาทันทีแล้วเริ่มตะโกนเสียงดัง”