



Seedance 2.0: Ein umfassender Leitfaden für die Ära, in der jeder zum Regisseur wird.
In den letzten Tagen hat ByteDances KI-Videomodell Seedance 2.0 das Internet vollständig erobert.
Mit Seedance 2.0 erstellte Videos sind derzeit überall zu sehen.
Manche nutzen es, um Verfolgungsjagden auf Kinoniveau zu erstellen. Andere ahmen die filmischen Kamerafahrten nach, die man sonst nur aus aufwendigen Werbespots kennt. Einige produzieren damit sogar Historiendramen, Zeitreisegeschichten oder actionreiche Martial-Arts-Filme – Aufnahmen, die so klar und detailreich sind, dass man kaum erkennen kann, ob sie von einer KI erstellt oder mit echten Schauspielern gedreht wurden.
Und ehrlich gesagt ist das keine Übertreibung.
Mit diesem Update hat Seedance 2.0 die Barriere für die KI-Videoerstellung praktisch von Grund auf fallen gelassen.
Genug geredet – fangen wir mit einer kurzen Montage an ↓
Also… wie sieht es aus?
Warum wurde es so schnell so populär? Weil es endlich ein Problem löste, das Kreative jahrelang geplagt hatte: Bei KI-Videos ging es früher nur um die Generierung. Jetzt geht es um die Kontrolle.
Bilder, Videos, Audio und Texte können beliebig kombiniert werden – Regie kann jeder führen.

Diesmal ist alles anders.
Seedance 2.0 ist nicht mehr nur ein Text-zu-Video-Tool . Es hat sich zu einer wahrhaft multimodalen Videoproduktionsplattform entwickelt, die die kreative Absicht verstehen kann.
Sie können Bilder, Videoclips, Audio und Text gleichzeitig einfügen. Sie legen fest, welche Funktion jedes Element haben soll. Anschließend fügt das Programm alles zu einem vollständigen Video zusammen.
Klingt etwas abstrakt? Das ist in Ordnung.
Ich werde jede Funktion und jeden Arbeitsablauf Schritt für Schritt erklären und Ihnen genau zeigen, wie die Leute es nutzen.
Das Wichtigste zuerst: Was kann Seedance 2.0 eigentlich leisten?
Im Kern besteht die wichtigste Verbesserung von Seedance 2.0: Multimodalität.
Bei früheren KI-Videomodellen waren die Eingabemöglichkeiten in der Regel auf zwei Dinge beschränkt: entweder eine Texteingabeaufforderung schreiben oder ein einzelnes Bild des ersten Frames hochladen.
Wollte man Kamerabewegungen, Gesichtsausdrücke oder das Tempo der Hintergrundmusik steuern, musste alles in Textform festgehalten werden. Ob das funktionierte oder nicht, hing fast ausschließlich davon ab, wie gut man darin war, Anweisungen zu formulieren.
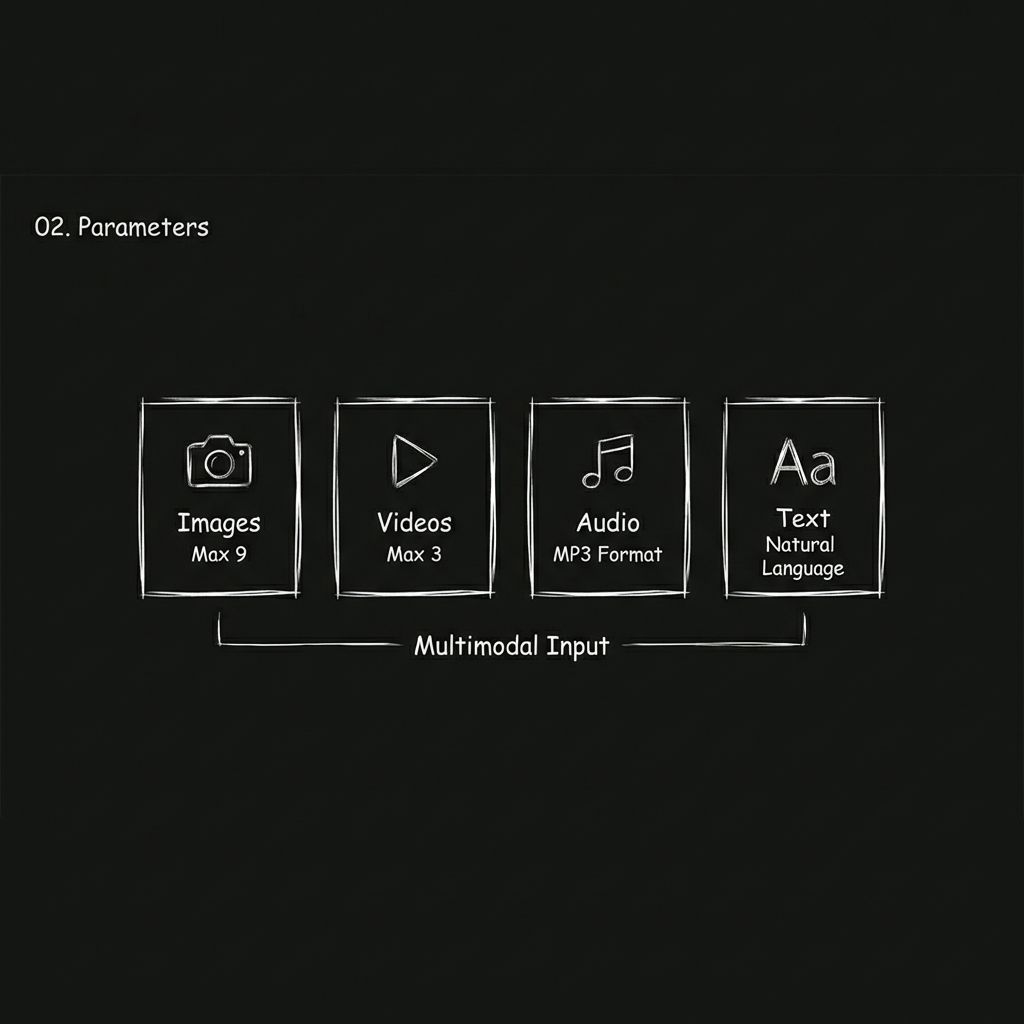
Seedance 2.0 ändert dies, indem es die Eingaben in vier verschiedene Modalitäten erweitert.
Bilder
Sie können bis zu 9 Bilder hochladen. Diese können das Aussehen von Charakteren, den Szenenstil, Kleidungsdetails, Produktabbildungen oder sogar Storyboard-Frames definieren.
Video
Sie können bis zu drei Videoclips mit einer Gesamtlänge von maximal 15 Sekunden hochladen. Das Modell kann anhand dieser Clips Kamerabewegungen, Bewegungsrhythmen und Übergangsstile analysieren. Im Prinzip erhalten Sie so ein visuelles Beispiel, von dem das Modell lernen kann.
Audio
MP3-Uploads werden unterstützt, bis zu 3 Dateien mit einer Gesamtdauer von maximal 15 Sekunden. Sie können Hintergrundmusik und Soundeffekte festlegen oder sogar den Erzählton aus einem anderen Video übernehmen.
Text
Sie beschreiben einfach die gewünschten visuellen Elemente, Aktionen und das gewünschte Tempo, indem Sie normale natürliche Sprache eingeben.
Alle vier Eingabetypen können frei kombiniert werden. Die Gesamtzahl der hochgeladenen Dateien über alle Modalitäten hinweg ist auf 12 begrenzt.
Das generierte Video kann bis zu 15 Sekunden lang sein. Sie können eine beliebige Dauer zwischen 4 und 15 Sekunden wählen. Das Video enthält integrierte Soundeffekte und Hintergrundmusik.
Einfach ausgedrückt: Sie können KI endlich wie ein echter Filmemacher steuern:
- Bilder definieren den visuellen Stil.
- Video definiert Bewegung.
- Audio definiert Rhythmus.
- Der Text definiert die Geschichte.
Seedance 2.0 Eingabe- und Ausgabespezifikationen
| Parameter | Beschreibung |
| Bildeingabe | Bis zu 9 Bilder |
| Videoeingang | Bis zu 3 Clips mit einer Gesamtdauer von höchstens 15 Sekunden. |
| Audioeingang | Unterstützt MP3, bis zu 3 Dateien mit einer Gesamtdauer von maximal 15 Sekunden |
| Texteingabe | Beschreibung in natürlicher Sprache (Englisch und Chinesisch werden unterstützt) |
| Ausgabedauer | 4 bis 15 Sekunden |
| Audioausgang | Eingebaute Soundeffekte und Hintergrundmusik |
| Gesamtdateilimit | Maximal 12 Dateien insgesamt für alle hochgeladenen Materialien |
Ein kurzer Tipp vorab : Mehr Referenzmaterial führt nicht immer zu besseren Ergebnissen.
Konzentrieren Sie sich auf die Elemente, die den größten Einfluss auf die Optik oder das Erzähltempo haben, und nutzen Sie Ihre Upload-Slots mit Bedacht.
So verwenden Sie es: Eine Schritt-für-Schritt-Anleitung
Schritt 1. Wählen Sie den richtigen Einstiegspunkt
Öffne Jimeng und suche nach Seedance 2.0.
Sie können Seedance 2.0 über Jimeng aufrufen. Es wird demnächst auch auf der Pollo AI Image to Video-Seite verfügbar sein.
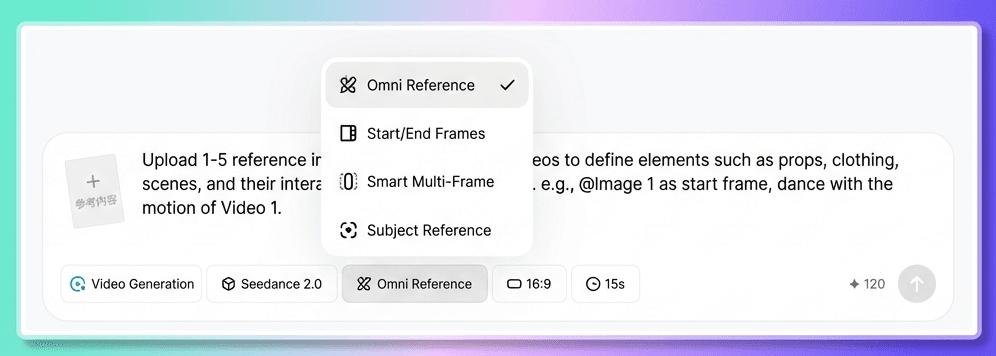
Sie werden zwei verschiedene Eingänge sehen.
- Erstes und letztes Bild : Verwenden Sie diese Option, wenn Sie nur ein einzelnes erstes Bild zusammen mit einer Textaufforderung hochladen.
- All-in-One-Referenz : Verwenden Sie diese Option, wenn Sie multimodale Eingaben benötigen, z. B. eine Kombination aus Bildern, Video, Audio und Text.
Wie entscheiden Sie, welches Format Sie verwenden? Befolgen Sie eine einfache Regel: Besteht Ihr Material nur aus einem Bild und Text, wählen Sie „Erstes und letztes Bild“; haben Sie mehr als ein Bild oder sind Video- oder Audiodateien enthalten, wählen Sie „All-in-One-Referenz“.
In den meisten Fällen ist All-in-One Reference die bessere Wahl. Es unterstützt alle Arten von Referenzeingaben und ermöglicht es Seedance 2.0, seine neuesten Funktionen voll auszuschöpfen.
Schritt 2. Laden Sie Ihre Assets hoch
Klicken Sie auf die Schaltfläche „Hochladen“ und wählen Sie Dateien von Ihrem Gerät aus. Bilder, Videos und Audiodateien können Sie direkt per Drag & Drop hineinziehen. Sobald der Upload abgeschlossen ist, werden alle Dateien im Eingabebereich angezeigt. Bewegen Sie den Mauszeiger über die einzelnen Elemente, um eine Vorschau des Inhalts anzuzeigen.
Noch ein kurzer Hinweis vor dem Hochladen: Überlegen Sie sich gut, welche Elemente am wichtigsten sind. Sie können insgesamt bis zu 12 Dateien hochladen. Priorisieren Sie daher diejenigen, die den größten Einfluss auf den visuellen Stil und das Erzähltempo haben.
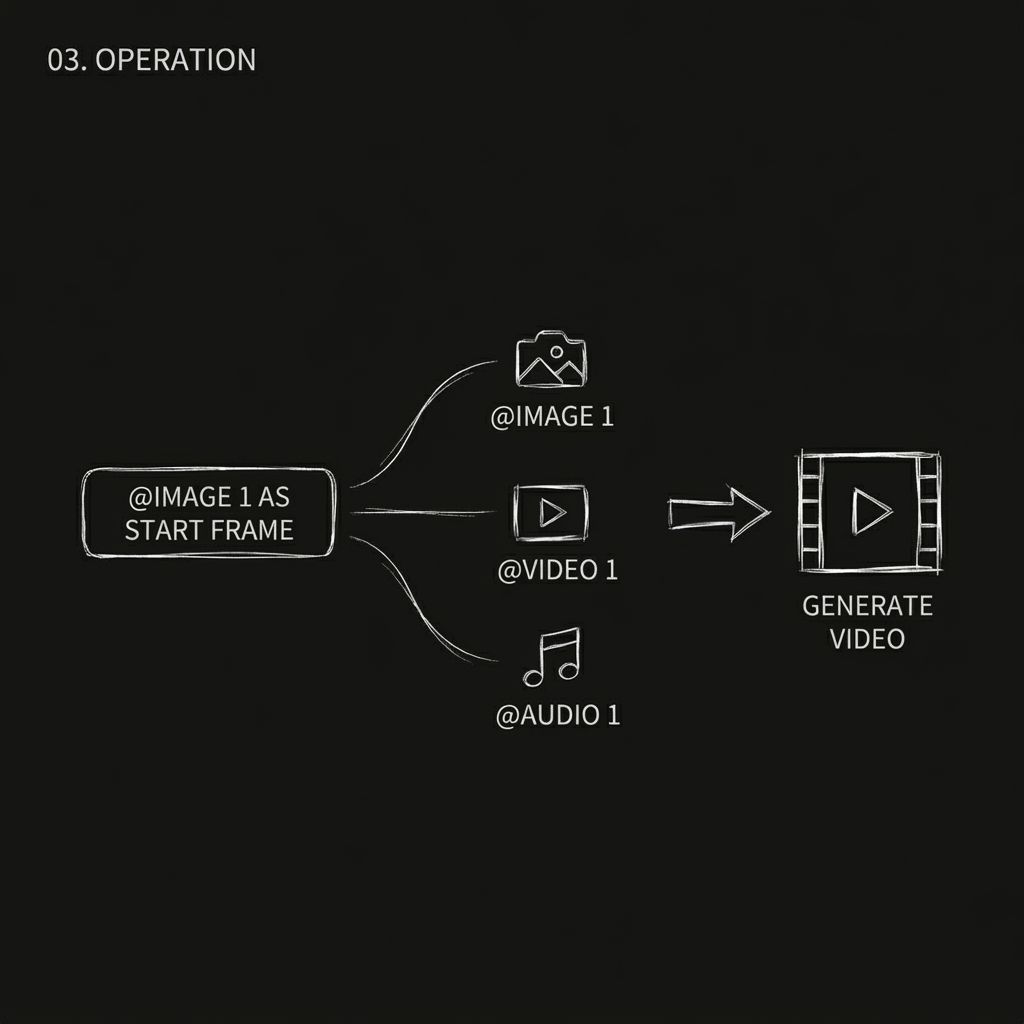
Schritt 3. Weisen Sie jedem Asset mithilfe von „@“ eine Rolle zu (Wichtigster Schritt)
Dies ist die zentrale Interaktion in Seedance 2.0 und gleichzeitig der Teil, den viele Anfänger oft übersehen.
Nach dem Hochladen Ihrer Assets müssen Sie dem Modell mithilfe von `@asset name` in Ihrer Eingabeaufforderung explizit den Zweck jedes einzelnen Assets mitteilen. Das Modell errät nicht automatisch, wofür es die Assets verwendet. Wenn Sie den Zweck nicht klar angeben, kann es zu Fehlverwendungen kommen.
Zum Beispiel:
- @Bild 1 als erstes Bild
- @Video 1 als Kamerareferenz
- @Audio 1 für Hintergrundmusik
Wie man „@“ auslöst
Methode 1
Geben Sie das „@“-Symbol direkt in das Eingabefeld ein. Es erscheint eine Liste aller hochgeladenen Assets. Klicken Sie auf das gewünschte Asset, um es in die Eingabeaufforderung einzufügen.
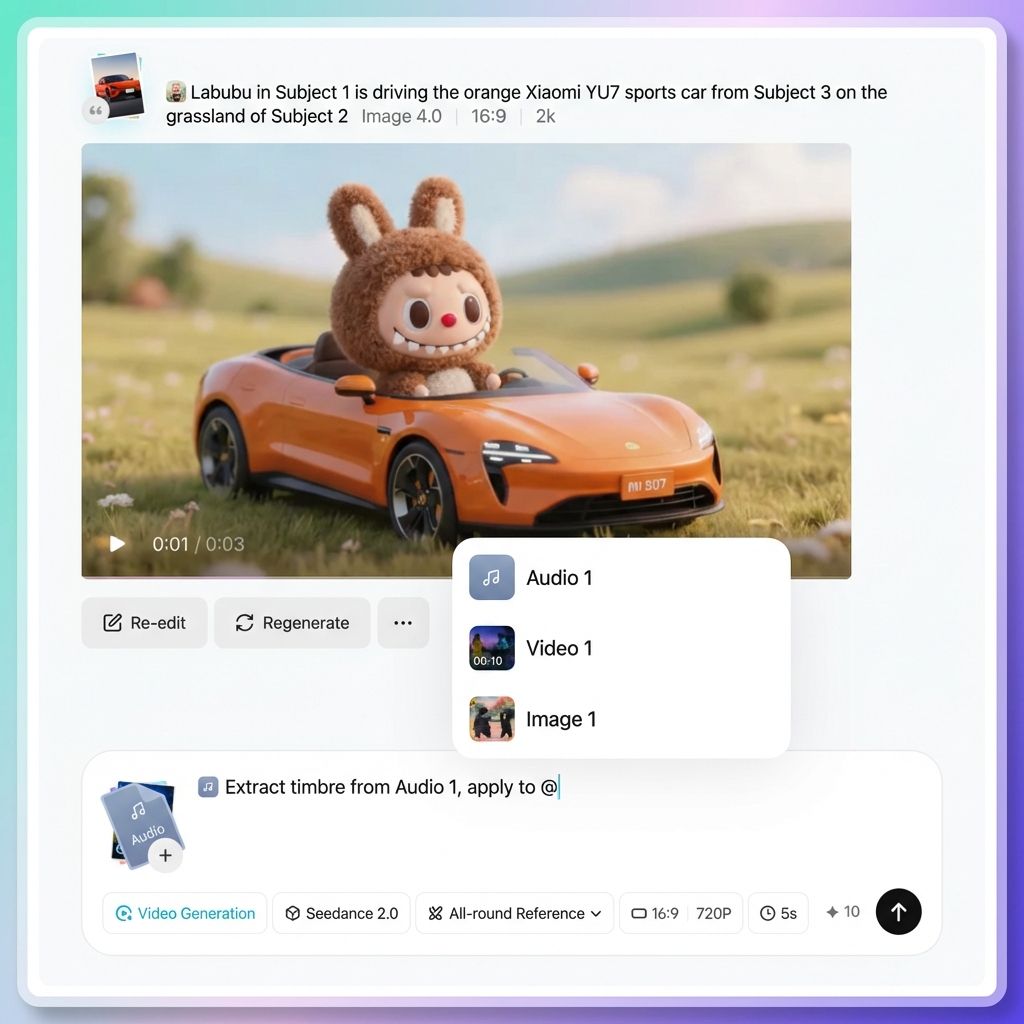
Methode 2
Klicken Sie auf die Schaltfläche „@“ in der Parameterleiste neben dem Eingabefeld. Dadurch wird auch die Anlagenliste angezeigt.
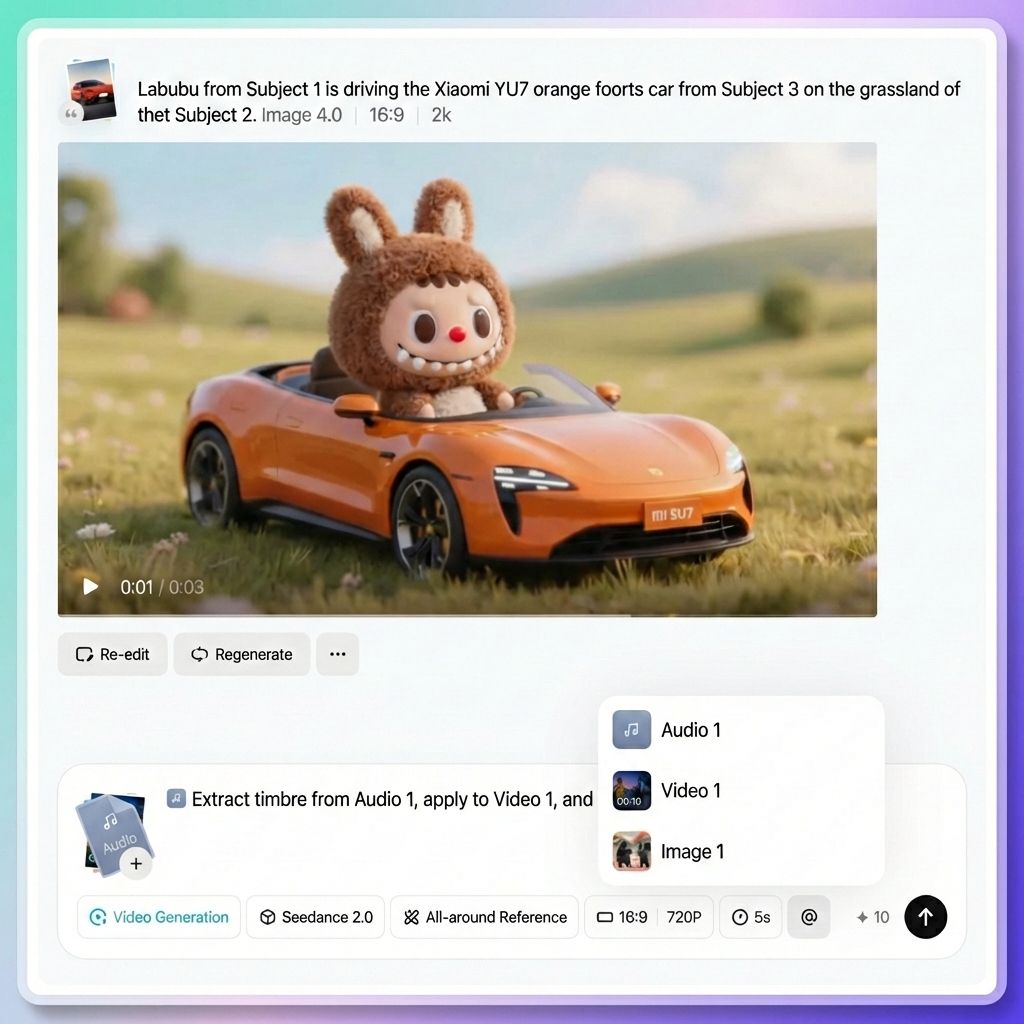
Beispiele für die korrekte Verwendung des „@“-Zeichens
- Legen Sie das erste Bild und die Referenz fest: @Image 1 als erstes Bild, die Kamerasprache von @Video 1 und @Audio 1 für die Hintergrundmusik.
- Rollenverteilung: Die weibliche Figur in @Image 1 als Hauptfigur und die männliche Figur in @Image 2 als Nebenfigur.
- Referenz für Kamerabewegungen festlegen: Alle Kamerabewegungen und Übergänge aus @Video 1 vollständig referenzieren.
- Szenenreferenzen angeben: Verwenden Sie @Image 3 als Referenz für die linke Szene und @Image 4 als Referenz für die rechte Szene.
- Aktionsreferenz angeben: Die Figur in @Image 1 sollte die Tanzbewegungen aus @Video 1 referenzieren.
- Stimmreferenz angeben: Die Sprecherstimme sollte sich an der Stimmlage aus @Video 1 orientieren.
Häufige Fehlerquelle, vor der man sich hüten sollte
Wenn Sie mit vielen Assets arbeiten, überprüfen Sie immer doppelt, ob jede „@“-Referenz auf die richtige Datei verweist. Wenn Sie beispielsweise ein Bild als Video referenzieren oder versehentlich das Bild von Figur A Figur B zuweisen, kann das Ergebnis schnell unübersichtlich werden.
Sie können mit der Maus über ein beliebiges referenziertes Element in der Eingabeaufforderung fahren, um eine Vorschau anzuzeigen und sicherzustellen, dass alles korrekt verknüpft ist.
Schritt 4. Formulieren Sie eine klare und effektive Aufgabenstellung.
Sobald Sie allen Assets mithilfe von „@“ Rollen zugewiesen haben, geht es im Folgenden darum, die gewünschten visuellen Elemente und Aktionen in natürlicher Sprache zu beschreiben.
Hier sind vier praktische Tipps für bessere Aufgabenstellungen.

Tipp 1. Schreiben Sie in einer Zeitleistenstruktur.
Wenn Ihr Video mehrere Szenen oder Erzählwechsel enthält, ist es am besten, diese in zeitlich geordnete Abschnitte zu unterteilen.
Zum Beispiel:
0–3 Sekunden
Der männliche Hauptdarsteller hebt einen Basketball in der Hand, blickt in die Kamera und sagt: „Ich wollte doch nur etwas trinken. Werde ich jetzt etwa eine Zeitreise unternehmen?“
4–8 Sekunden
Die Kamera wackelt plötzlich heftig. Die Szene wechselt zu einer regnerischen Nacht in einem alten Haus. Eine Hauptdarstellerin in traditioneller Tracht blickt kühl in die Kamera.
9–13 Sekunden
Die Kamera schwenkt zu einer Figur in Kleidung der Ming-Dynastie…
Diese Schreibweise hilft dem Modell, Tempo und Inhalt jedes Abschnitts genauer zu verstehen.
Tipp 2. Machen Sie deutlich, was „Referenz“ und was „Bearbeitung“ ist.
Diese beiden Konzepte sind nicht dasselbe.
„Die Kamerabewegung von @Video 1 als Referenz nutzen“ bedeutet, dessen Kamerabewegungsstil zu verwenden, um neue Inhalte zu generieren.
„Ersetze die weibliche Figur in @Video 1 durch eine traditionelle Opernsängerin“ bedeutet, das Originalvideo selbst zu verändern.
Machen Sie deutlich, welches Modell Sie wünschen, damit das Modell korrekt reagieren kann.
Tipp 3. Verwenden Sie präzise Kamerasprache.
Machen Sie sich keine Sorgen, wenn Sie zu viel schreiben. Das Modell versteht die Kamerasprache mittlerweile sehr gut.
Schieben, Ziehen, Schwenken, Verfolgen, Dollyfahrt, Kreisfahrt, Aufnahmen von oben, Aufnahmen aus der Froschperspektive, One-Take-Aufnahmen, Hitchcock-Zooms, Fisheye-Objektive. Es versteht all diese professionellen Begriffe.
Wenn Sie mit Fachbegriffen nicht vertraut sind, ist das auch kein Problem. Einfache Beschreibungen reichen völlig aus, zum Beispiel: „Die Kamera bewegt sich langsam von hinter der Figur nach vorn.“
Tipp 4. Übergänge für kontinuierliche Aktionen hinzufügen
Wenn eine Figur eine Abfolge zusammenhängender Aktionen ausführen soll, müssen die Übergänge klar beschrieben werden.
Zum Beispiel: „Die Figur geht nahtlos von einem Sprung in eine Rolle über, wodurch die Bewegung kontinuierlich und flüssig bleibt.“ Dies hilft, unnatürliche Schnitte im fertigen Video zu vermeiden.
Schritt 5. Dauer auswählen und generieren
Wählen Sie die gewünschte Videolänge, irgendwo zwischen 4 und 15 Sekunden.
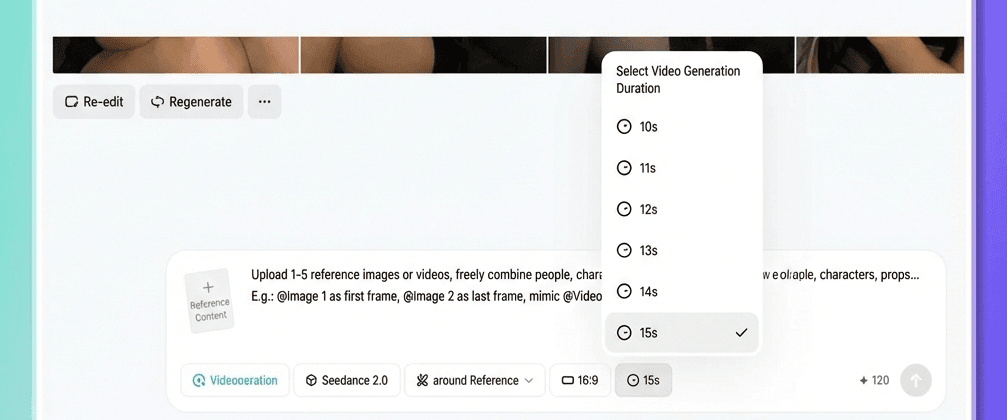
Eine wichtige Anmerkung:
Wenn Sie ein bestehendes Video verlängern, beispielsweise um fünf Sekunden an das Ende eines Clips anhängen, bezieht sich die hier ausgewählte Dauer nur auf den neu generierten Abschnitt, nicht auf die Gesamtlänge des Videos. Um das Video um fünf Sekunden zu verlängern, wählen Sie fünf Sekunden aus.
Klicken Sie anschließend auf „Generieren“ und warten Sie auf das Ergebnis.
Sollten Sie nicht zufrieden sein, können Sie den Vorgang gerne mehrmals wiederholen. KI-Ergebnisse beinhalten ein Element der Zufälligkeit, sodass selbst bei gleichen Eingaben jedes Ergebnis leicht variieren kann. Wählen Sie einfach die Version, die Ihnen am besten gefällt.
Ein detaillierter Einblick in die Kernfunktionen von Seedance 2.0
Nachfolgend sind die zehn wichtigsten Funktionen von Seedance 2.0 aufgeführt. Jede Funktion wird mit praktischen Anwendungshinweisen und Beispielen aus der Praxis erläutert.
Fähigkeit 1. Ein großer Sprung in der visuellen Qualität
Fangen wir mit den Grundlagen an.
Seedance 2.0 wurde von Grund auf neu entwickelt. Die Physik wirkt realistischer, die Bewegungen sind flüssiger und der visuelle Stil bleibt innerhalb einer Szene konsistenter.
Auf der grundlegendsten Ebene der Bilderzeugung hat es einen qualitativen Sprung gegeben:
- Realistischere Physik : Kleidungsbewegungen, Wasserspritzer und Objektkollisionen verhalten sich natürlicher.
- Geschmeidigere und natürlichere Bewegungen : Gehen, Laufen und selbst komplexe Aktionen wirken nicht mehr steif oder mechanisch.
- Genaueres Verständnis der Anweisung : Wenn man sagt „ein Mädchen, das anmutig Wäsche aufhängt“, versteht das System tatsächlich, was „anmutig“ bedeutet.
- Mehr Stabilität im Stil : Der visuelle Stil bleibt vom Anfang bis zum Ende stimmig, ohne plötzliche Umschwung.

Anwendungsbeispiel
Ein Mädchen hängt anmutig Wäsche zum Trocknen auf. Nachdem sie ein Stück fertig gelassen hat, nimmt sie ein anderes aus einem Eimer und schüttelt es kräftig.
Was bedeutet das in der Praxis?
Wenn man eine Szene wie „ein Mädchen, das anmutig Wäsche aufhängt, dann eine andere aus einem Eimer nimmt und sie kräftig schüttelt“ erzeugt, wirken die Bewegung des Stoffes, die Kraft in ihren Armen und die Textur des Stoffes erstaunlich nah an realen Aufnahmen.
Auch komplexere Szenen sind problemlos realisierbar.
Die Kamera folgt einem schwarz gekleideten Mann, der in hoher Geschwindigkeit davonrennt. Eine Gruppe von Menschen verfolgt ihn. Die Kamera schwenkt zur Seite. In seiner Panik prallt er gegen einen Obststand am Straßenrand, stürzt, steht wieder auf und rennt weiter.
Szenen mit Verfolgungsjagden, Kollisionen und dynamischen Kameraübergängen können in Version 2.0 nun konsistent generiert werden.
Es gibt sogar noch extremere Beispiele. Manche Künstler haben mit nur einer einzigen Anweisung eine Figur in einem Gemälde heimlich nach einer Coladose greifen lassen, einen Schluck nehmen, sie beim Hören von Schritten schnell wieder zurückstellen und dann in eine Schlusseinstellung übergehen lassen, die auf einen schwarzen Hintergrund mit nur der Coladose und künstlerischen Untertiteln zufährt. Eine solche narrative Komplexität wäre früher fast undenkbar gewesen.
Fähigkeit 2. Kostenlose multimodale Kombination
Dies ist die wichtigste Verbesserung in Version 2.0. Sie können nun jede Art von Material als Referenz verwenden.
Die Formel lässt sich wie folgt zusammenfassen:
Seedance 2.0 = multimodale Referenzierung + starke kreative Generierung + präzises Instruktionsverständnis
Sie können Folgendes als Referenz verwenden:
- Aktionen, Effekte und visuelle Formate
- Kamerabewegung und Bildsprache
- Charakterdarstellung und Szenenstil
- Klang und musikalischer Rhythmus

Praktische Tipps
| Was Sie tun möchten | Wie man die Aufgabenstellung formuliert |
| Ich habe ein Keyframe-Bild und möchte die Videobewegung als Referenz verwenden. | "@Bild 1 als Schlüsselbild verwenden, die Kamerabewegung aus @Video 1 als Referenz nutzen" |
| Erweitern Sie ein bestehendes Video | "Verlängere @Video 1 um 5 Sekunden" (Generierungsdauer auf 5 Sekunden festlegen) |
| Mehrere Videos kombinieren | „Füge eine Szene zwischen @Video 1 und @Video 2 ein, Inhalt ist xxx“ |
| Verwenden Sie den Ton aus einem Video | Es ist nicht nötig, die Audiodatei separat hochzuladen, verlinken Sie einfach direkt auf das Video. |
| Kontinuierliche Aktion | „Die Figur geht nahtlos vom Sprung in eine Rolle über, die Bewegung sollte flüssig und kontinuierlich bleiben.“ |
Fähigkeit 3: Wesentliche Verbesserung der Konsistenz
Wer schon einmal mit KI-Video gearbeitet hat, weiß, dass die Konsistenz das frustrierendste Problem ist.
Die Gesichter verändern sich zwischen den Einstellungen, Produktdetails verschwinden beim Wechsel des Blickwinkels, und der Szenenstil springt plötzlich hin und her.
Version 2.0 unternimmt ernsthafte Anstrengungen, dieses Problem zu lösen.
Nach dem Hochladen eines Referenzbildes bleiben Aussehen, Kleidung und Körperhaltung der Person im gesamten Video unverändert. Dasselbe gilt für Produktpräsentationen. Selbst bei Aufnahmen einer Tasche aus verschiedenen Blickwinkeln bleiben Vorder-, Seiten- und Materialdetails unverändert.
Elemente, die konstant bleiben können:
- Gesichtsmerkmale (Gesichtsstruktur, Hautton, Ausdrucksstil)
- Kleidungsdetails (Textur, Farbe, Muster)
- Markenelemente (Logo, Typografie, Farbschema)
- Szenenstil (Beleuchtung, Atmosphäre, Farbton)
Anwendungsbeispiel
Mann @Image1 geht nach der Arbeit erschöpft einen Flur entlang. Seine Schritte werden langsamer. Er bleibt vor seiner Haustür stehen, atmet tief durch, um sich zu sammeln, sucht nach seinen Schlüsseln, schließt auf und tritt ein. Seine kleine Tochter und sein Hund laufen ihm freudig entgegen und umarmen ihn.

Durch den Bezug auf @Image1 bleibt das Erscheinungsbild der Figur während der gesamten Sequenz konsistent.
Funktion 4: Präzise Wiedergabe von Kamerabewegungen und Aktionen
Dies ist eines der meistdiskutierten Features von Version 2.0.
Früher musste man, wenn man wollte, dass KI filmische Kamerabewegungen imitiert, entweder eine lange Liste technischer Begriffe schreiben und auf das Beste hoffen, oder es funktionierte einfach nicht.
Jetzt sind nur noch zwei Schritte nötig:
Laden Sie ein Referenzvideo mit der Kamerabewegung hoch, die Ihnen gefällt, und schreiben Sie dann:
„Beachten Sie die Kamerabewegung aus @Video1.“
Das Modell analysiert die Kameralogik im Referenzvideo (Schieben, Ziehen, Schwenken, Verfolgen, Kreisen, Zoomen, Serienaufnahme usw.) und wendet denselben Bewegungsstil auf Ihre neuen Inhalte an.
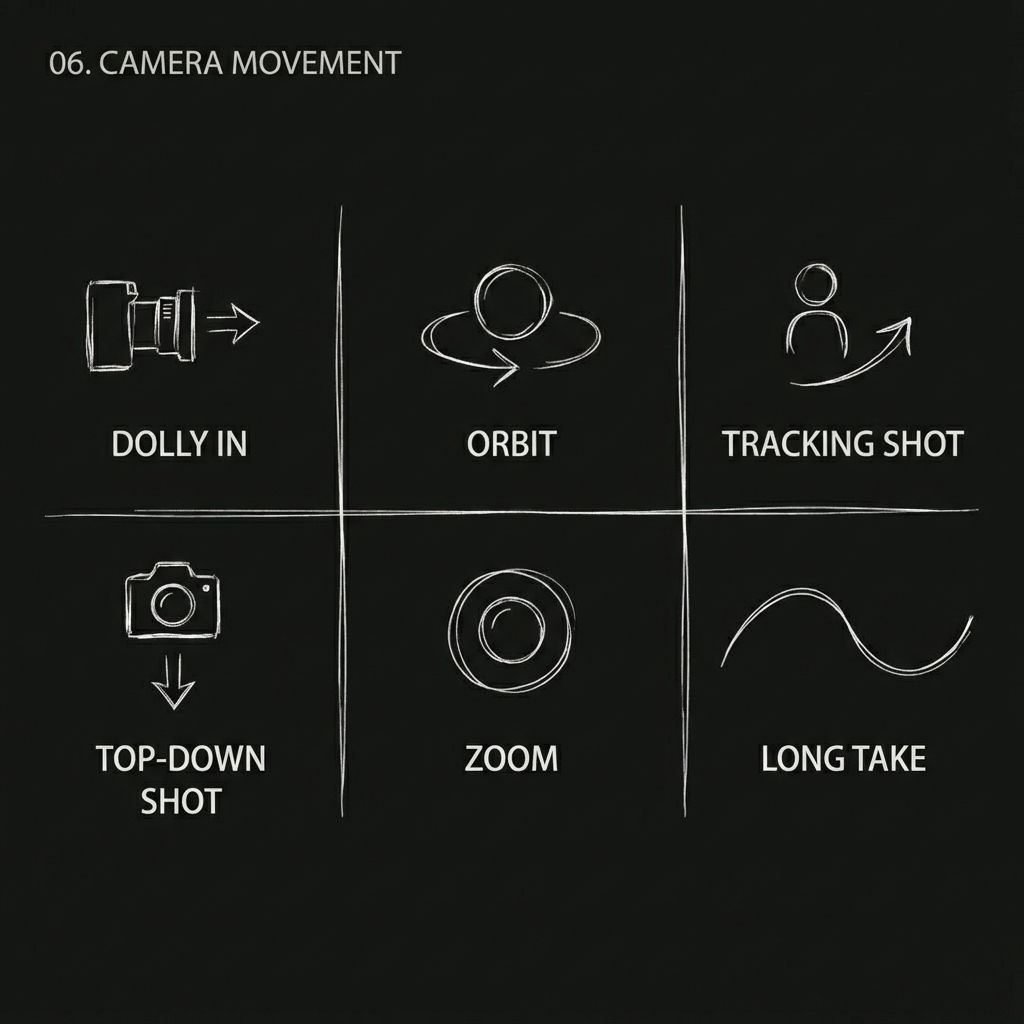
Kamerabewegungen, die nachgebildet werden können:
- Hitchcock-Zoom
- Orbit-Tracking-Aufnahme
- Eine einzige, ununterbrochene Aufnahme
- Schieben / Ziehen / Schwenken / Verfolgungsaufnahmen
- Aufnahme aus der Froschperspektive
- Vogelperspektive
Beispiel: Nachstellung einer klassischen Wuxia-Szene
Fähigkeit 5. Präzise Nachbildung von kreativen Vorlagen und Effekten
Haben Sie ein cooles Werbekonzept, einen Übergangseffekt oder einen Filmausschnitt gefunden, der Ihnen gefällt?
Laden Sie es direkt als Referenz hoch. Das Modell kann den Bewegungsrhythmus, die visuelle Struktur und die Kamerasprache darin erkennen und Ihnen helfen, Ihre eigene Version zu erstellen.
Arten von kreativen Inhalten, die reproduziert werden können:
- Kreative Übergänge, wie etwa das Zerbrechen von Puzzleteilen, die Zerstreuung von Partikeln und Portalübergänge im Iris-Stil
- Fertige Werbestile
- Rhythmusbearbeitung im MV-Stil
- Filmische Spezialeffektaufnahmen
- Outfit-Transformations- und Gesichtstausch-Effekte
Beispiel:
Spezialeffekte voll aufgedreht…
Funktion 6. Videoerweiterung und -fortsetzung
Sie haben bereits ein Video, mit dem Sie zufrieden sind und möchten die Geschichte fortsetzen? Oder möchten Sie vielleicht eine Vorgeschichte vor dem bestehenden Clip hinzufügen? Die Videoerweiterungsfunktion ermöglicht beides.
Nach vorne ausstrecken
Laden Sie das bestehende Video hoch und schreiben Sie „extend @Video 1 by X seconds“, gefolgt von einer Beschreibung der neuen Szenen, die Sie generieren möchten.
Nach hinten ausstrecken
Schreiben Sie „verlängere X Sekunden vorher“ und fügen Sie eine Beschreibung der vorherigen Handlungsebene hinzu, die Sie erstellen möchten.
Nutzungsregeln
Weisen Sie das Modell klar an: „Verlängere @Video 1 um X Sekunden.“
Wählen Sie bei der Generierung eine Dauer, die der Verlängerungslänge entspricht. Wenn Sie beispielsweise um fünf Sekunden verlängern möchten, wählen Sie fünf Sekunden als Generierungslänge.
Im Erweiterungsteil können Sie neue Handlungselemente und visuelle Beschreibungen einfügen.
Sowohl Vorwärts- als auch Rückwärtserweiterung werden unterstützt.
Anwendungsbeispiel
Durch die Verwendung von Bildern und Videos kann der ursprüngliche zweisekündige Clip oben auf fünfzehn Sekunden verlängert werden.
Der erweiterte Teil kann detailliert beschrieben werden, einschließlich Kamerabewegungen, visueller Elemente und Text auf dem Bildschirm.
Funktion 7. Realistischerer Klang
Videos, die mit Version 2.0 erstellt wurden, verfügen über integrierte Soundeffekte und Hintergrundmusik, und die allgemeine Audioqualität hat sich im Vergleich zu vorher deutlich verbessert.
Hier sind einige Anwendungsbeispiele im Audiobereich.
Bezug zur Stimmlage
Laden Sie einen Video- oder Audioclip hoch und lassen Sie das Model den Sprechstil oder die Erzählweise daraus imitieren.
Mehrsprachiger Dialog
Die Charaktere sprechen Chinesisch, Englisch, Spanisch, Koreanisch und weitere Sprachen. Die emotionale Darstellung ist sehr gut gelungen.
Dialoge mit mehreren Charakteren
Ein einzelnes Video kann mehrere Charaktere enthalten, die jeweils ihre eigenen Texte sprechen. Erfolgreiche Beispiele hierfür sind Talkshows mit Katzen und Hunden, Dialoge in historischen Dramen und taktische Militärgespräche.
Dialektunterstützung
Einigen Kreativen ist es gelungen, Charaktere zu erschaffen, die im Sichuan-Dialekt sprechen und dabei Milchtee bestellen. Das Ergebnis wirkt überraschend authentisch.
Soundeffekt-Zuordnung
Schritte, Donner, Lärm von Menschenmengen, Zusammenstöße von Geräten und andere Umgebungsgeräusche können alle mit angemessener Genauigkeit erzeugt werden.
Fähigkeit 8. Mehr stimmige Aufnahmen in einer einzigen Einstellung
Eine „One-Take“-Aufnahme erfordert, dass die Szene über einen längeren Zeitraum hinweg ununterbrochen bleibt und gleichzeitig komplexe räumliche Übergänge und Kamerabewegungen bewältigt werden. Dies war schon immer eine große Herausforderung für KI.
Seedance 2.0 hat in diesem Bereich deutliche Fortschritte erzielt. Wenn Sie mehrere Bilder aus verschiedenen Szenen hochladen und beispielsweise schreiben: „Eine kontinuierliche Kamerafahrt, die einem Läufer von der Straße die Treppe hinauf, durch einen Korridor, auf das Dach folgt und schließlich die Stadt überblickt“, kann das Modell natürliche Übergänge zwischen den Szenen ohne sichtbare Brüche realisieren.
Auch komplexere Sequenzen, die in einer einzigen Einstellung gedreht werden, sind möglich. Zum Beispiel: „Aus der Ich-Perspektive blickt man durch ein Flugzeugfenster, wo sich Wolken in Eiscreme verwandeln, und schwenkt dann die Kamera zurück in die Kabine, während die Figur die Eiscreme nimmt und einen Bissen davon nimmt.“
Selbst Sequenzen dieser Art, die in einer einzigen Einstellung gedreht werden und Perspektivwechsel sowie eine Mischung aus Realismus und Fantasie beinhalten, können von Seedance 2.0 realisiert werden.
Es gibt auch Szenen im Stil von Spionagethrillern, die in einer einzigen Einstellung gedreht wurden. Die Kamera folgt einer Agentin in Rot, die sich durch eine Menschenmenge bewegt. Sie biegt um eine Ecke und trifft auf ein maskiertes Mädchen. Die Verfolgung setzt sich in einer Villa fort, wo das Ziel spurlos verschwindet – alles ohne einen einzigen Schnitt.
Diese narrative Dichte in einer einzigen, ununterbrochenen Einstellung zu erreichen, ist schon ziemlich beeindruckend.
Anwendungsbeispiel
@Image1 @Image2 @Image3 @Image4 @Image5, eine durchgehende Kamerafahrt, die einem Läufer von der Straße die Treppe hinauf, durch einen Korridor, auf das Dach folgt und schließlich einen Blick über die Stadt freigibt.
Tipp
Ordnen Sie mehrere Bilder in einer bestimmten Reihenfolge an. Das Model wird diese Szenen nacheinander in der fortlaufenden Aufnahme präsentieren.
Funktion 9. KI-Videobearbeitung
Sie haben bereits ein Video und möchten nicht von vorne beginnen, sondern nur einen Teil davon bearbeiten? Dann können Sie jetzt ein bestehendes Video als Vorlage verwenden und gezielte Änderungen vornehmen.
Charakterersetzung
Ersetzen Sie Figur A im Video durch Figur B, wobei die ursprünglichen Handlungen und Gesichtsausdrücke unverändert bleiben. Zum Beispiel: „Ersetzen Sie die weibliche Hauptsängerin in Video 1 durch den männlichen Hauptdarsteller aus Bild 1 und ahmen Sie dabei die ursprünglichen Bewegungen exakt nach.“
Handlungsumkehr
Die Szene und die Figuren bleiben gleich, aber die Handlung wird komplett umgeschrieben. Manche Drehbuchautoren haben eine romantische Mondbeobachtungsszene auf einer Brücke in eine dramatische Wendung verwandelt, in der der männliche Hauptdarsteller die weibliche Hauptdarstellerin ins Wasser stößt. Andere wiederum haben eine angespannte Verhandlung in einer Bar in einen komischen Moment verwandelt, in dem jemand stattdessen eine riesige Tüte mit Snacks hervorholt.
Elementmodifikation
Ändern Sie die Frisuren, fügen Sie Requisiten hinzu oder tauschen Sie die Hintergründe aus. Zum Beispiel: „Ändern Sie die Frisur der Frau in Video 1 in lange rote Haare und lassen Sie den Weißen Hai aus Bild 1 langsam halb hinter ihr auftauchen.“
Markenintegration
Integrieren Sie Markenelemente in ein bestehendes Video. Fügen Sie beispielsweise in einem Video über gebratenes Hähnchen eine Nahaufnahme einer Papiertüte mit Markenlogo hinzu.
Beispiel – Zeichenersetzung:
Erschaffe Black Myth: Wukong neu und lass ihn dann gegen Captain America kämpfen.
Funktion 10: Beat-synchronisierte Bearbeitung
Laden Sie ein rhythmisches Musikvideo als Referenz hoch. Das Modell kann Tempoänderungen erkennen und Szenenschnitte präzise im Takt ausführen.
Grundlegende Beat-Synchronisierung
Laden Sie Bildmaterial und ein Musikreferenzvideo hoch und schreiben Sie dann:
„Synchronisiere die Visuals auf den Rhythmus von @Video.“
Dynamische Beat-Synchronisation
Schreiben:
„Gestalten Sie die Charaktere dynamischer, verstärken Sie den insgesamt verträumten visuellen Stil, erhöhen Sie die visuelle Spannung und passen Sie den Bildausschnitt je nach Musik an.“
Landscape Beat Sync
Wenn Sie mehrere Landschaftsbilder mit Musik kombinieren, schreiben Sie:
„Landschaftsszenen greifen den Rhythmus von @Video auf und synchronisieren die Übergänge mit dem visuellen Stil und den Musikbeats.“
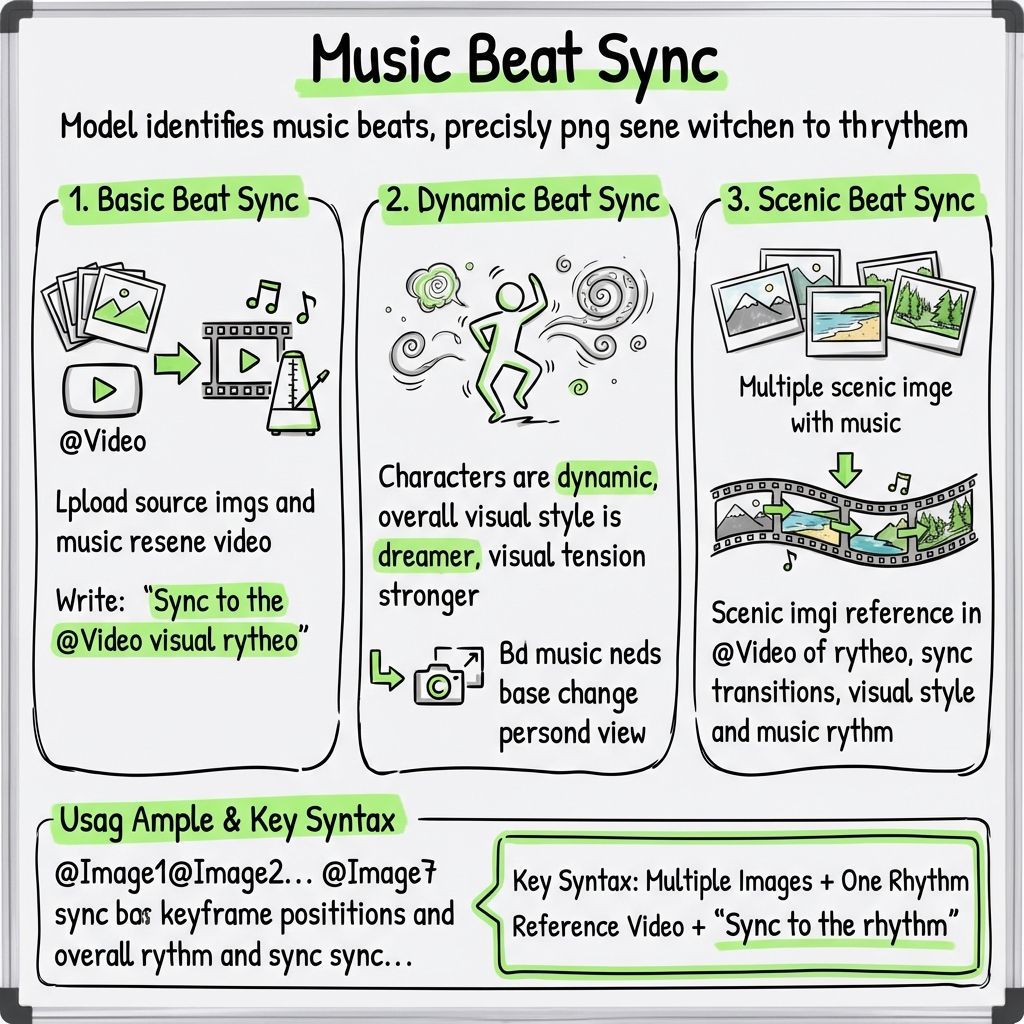
Anwendungsbeispiel
@Image1 @Image2 @Image3 @Image4 @Image5 @Image6 @Image7
Synchronisiere diese Bilder entsprechend den Keyframe-Positionen und dem Gesamtrhythmus von @Video. Verleihe den Charakteren mehr Dynamik und dem gesamten visuellen Stil eine verträumtere Note.
Schlüsselformel
Mehrere Bilder + ein Rhythmus-Referenzvideo + „Synchronisieren Sie sich zum Rhythmus“.
Fähigkeit 11. Überzeugendere emotionale Darbietung
Steife Gesichtsausdrücke und unnatürliche Gefühlsübergänge sind seit Langem ein häufiges Problem in KI-generierten Videos. Version 2.0 zeigt in diesem Bereich deutliche Verbesserungen.
Sie können ein Video als emotionale Referenz hochladen und das Model die darin enthaltenen Gesichtsausdrücke imitieren lassen. Zum Beispiel: „Die Frau in @Bild 1 geht zum Spiegel, hält inne, denkt nach und bricht dann plötzlich in Schreie aus. Die Handlung, den Spiegel zu greifen, und die emotionale Intensität des Zusammenbruchs sollten sich vollständig auf @Video 1 beziehen.“

Emotionale Übergänge lassen sich auch präzise in Textform beschreiben. Zum Beispiel der Wechsel von Sanftmut zu Kälte, von Anspannung zu Entspannung oder von Wut zu Erleichterung. Das Modell erkennt diese emotionalen Veränderungen und spiegelt sie durch Mimik, Körpersprache und Tonfall wider.
Es kann sogar übertriebene Gesichtsausdrücke mit komödiantischem Unterton darstellen. Zum Beispiel: „Die Figur blickt plötzlich auf und beginnt laut zu schreien.“