



Seedance 2.0: una guida completa e pratica all'era in cui tutti diventano registi
Negli ultimi giorni, il modello video AI Seedance 2.0 di ByteDance ha completamente conquistato Internet.
I video generati da Seedance 2.0 sono ormai ovunque.
C'è chi lo usa per creare sequenze di inseguimento degne di un film. Altri stanno ricreando i movimenti di macchina cinematografici che normalmente si vedono negli spot pubblicitari ad alto budget. Alcuni lo stanno persino trasformando in drammi d'epoca, storie di viaggi nel tempo o veri e propri film d'azione di arti marziali: riprese così pulite e dettagliate che è davvero difficile capire se siano state realizzate da un'intelligenza artificiale o girate con attori veri.
E onestamente non è un'esagerazione.
Con questo aggiornamento, Seedance 2.0 ha praticamente abbattuto la barriera alla creazione di video tramite intelligenza artificiale.
Basta parlare, iniziamo con un rapido montaggio ↓
Allora... come ti sembra?
Perché la sua popolarità è esplosa così rapidamente? Perché ha finalmente risolto un problema che tormenta i creatori da anni: i video basati sull'intelligenza artificiale erano un tempo una questione di generazione. Ora, è una questione di controllo.
Combina liberamente immagini, video, audio e testo: chiunque può dirigere.

Questa volta le cose sono diverse.
Seedance 2.0 non è più solo uno strumento di conversione da testo a video . Si è evoluto in una piattaforma di creazione video realmente multimodale, in grado di comprendere l'intento creativo.
Puoi fornirgli immagini, videoclip, audio e testo contemporaneamente. Gli indichi la funzione di ogni risorsa. Poi, il video viene fuso insieme in un unico video completo.
Sembra un po' astratto? Non preoccuparti.
Analizzerò passo dopo passo ogni funzionalità e flusso di lavoro e ti mostrerò esattamente come le persone lo utilizzano.
Cominciamo dall'inizio: cosa può fare realmente Seedance 2.0?
Alla base di Seedance 2.0 c'è un aggiornamento fondamentale: la multimodalità.
Con i precedenti modelli video basati sull'intelligenza artificiale , le opzioni di input erano solitamente limitate a due sole cose: scrivere un prompt di testo o caricare una singola immagine del primo fotogramma.
Se si voleva controllare il movimento della telecamera, le espressioni facciali o il ritmo della musica di sottofondo, tutto doveva essere forzato nel testo. Il successo o il fallimento dipendeva quasi interamente dalla propria abilità nello scrivere i prompt.
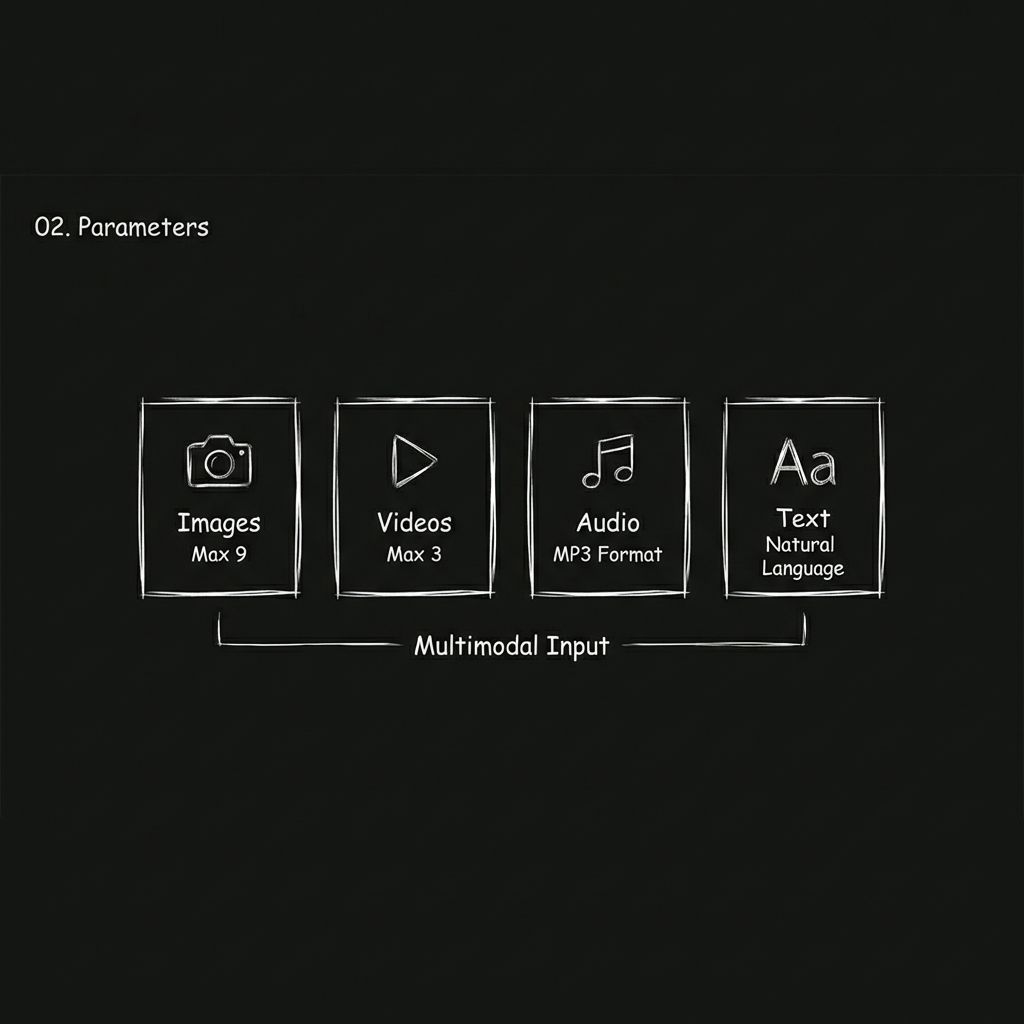
Seedance 2.0 cambia questa situazione espandendo gli input in quattro diverse modalità.
Immagini
Puoi caricare fino a 9 immagini. Queste possono definire l'aspetto del personaggio, lo stile della scena, i dettagli dell'abbigliamento, le immagini del prodotto o persino i fotogrammi dello storyboard.
Video
È possibile caricare fino a 3 videoclip, con una durata totale non superiore a 15 secondi. Il modello può fare riferimento al movimento della telecamera, al ritmo del movimento e agli stili di transizione di queste clip. In pratica, questo funziona come fornire al modello un campione visivo da cui imparare.
Audio
Sono supportati i caricamenti in formato MP3, fino a 3 file con una durata totale non superiore a 15 secondi. È possibile specificare musica di sottofondo, stili di effetti sonori o persino fare riferimento al tono della narrazione di un altro video.
Testo
Basta descrivere gli elementi visivi, le azioni e il ritmo desiderati inserendo un linguaggio naturale standard.
Tutti e 4 i tipi di input possono essere combinati liberamente. Il numero totale di file caricabili in tutte le modalità è limitato a 12.
Il video generato può durare fino a 15 secondi. È possibile scegliere una durata compresa tra 4 e 15 secondi e l'output include effetti sonori e musica di sottofondo integrati.
In parole povere, finalmente puoi dirigere l'intelligenza artificiale come un vero regista:
- Le immagini definiscono lo stile visivo.
- Il video definisce il movimento.
- L'audio definisce il ritmo.
- Il testo definisce la storia.
Specifiche di input e output di Seedance 2.0
| Parametro | Descrizione |
| Input immagine | Fino a 9 immagini |
| Ingresso video | Fino a 3 clip, con una durata totale non superiore a 15 secondi |
| Ingresso audio | Supporta MP3, fino a 3 file, con una durata totale non superiore a 15 secondi |
| Inserimento di testo | Descrizione in linguaggio naturale (supportati inglese e cinese) |
| Durata dell'output | da 4 a 15 secondi |
| Uscita audio | Effetti sonori e musica di sottofondo integrati |
| Limite totale dei file | Un massimo di 12 file tra tutti i materiali caricati |
Un consiglio rapido prima di iniziare : più materiale di riferimento non sempre porta a risultati migliori.
Dai priorità alle risorse che hanno il maggiore impatto sugli elementi visivi o sul ritmo e distribuisci saggiamente gli slot di caricamento.
Come usarlo: una guida passo passo
Fase 1. Scegliere il punto di ingresso giusto
Apri Jimeng e individua Seedance 2.0.
Puoi accedere a Seedance 2.0 tramite Jimeng. Sarà presto disponibile anche sulla pagina Pollo AI Image to Video .
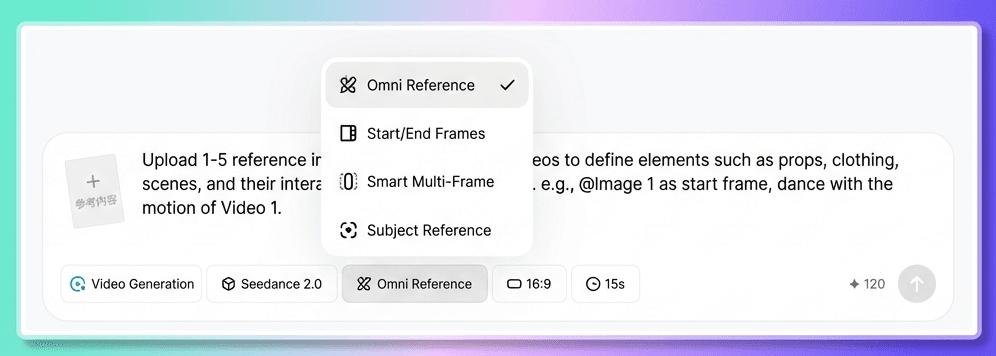
Vedrai due punti di ingresso diversi.
- Primo e ultimo fotogramma : utilizzare questa opzione quando si carica solo un'immagine del primo fotogramma insieme a un prompt di testo.
- Riferimento all-in-one : utilizzare questa opzione quando sono necessari input multimodali, ad esempio una combinazione di immagini, video, audio e testo.
Come decidi quale usare? Segui una semplice regola: se i tuoi materiali sono composti da una sola immagine e testo, scegli "Primo e ultimo fotogramma"; se hai più di un'immagine, o se sono presenti video o audio, scegli "Riferimento completo".
Nella maggior parte dei casi, All-in-One Reference è la scelta migliore. Supporta tutti i tipi di input di riferimento ed è anche il punto in cui Seedance 2.0 può mostrare appieno le sue ultime funzionalità.
Passaggio 2. Carica le tue risorse
Fai clic sul pulsante di caricamento e seleziona i file dal tuo dispositivo locale. Immagini, video e audio possono essere trascinati direttamente. Una volta completato il caricamento, tutte le risorse appariranno nell'area di input. Puoi passare il mouse su ciascun elemento per visualizzarne l'anteprima del contenuto.
Un rapido promemoria prima di caricare: rifletti attentamente su quali risorse sono più importanti. Puoi caricare fino a 12 file in totale, quindi dai priorità a quelli che hanno il maggiore impatto sullo stile visivo e sul ritmo.
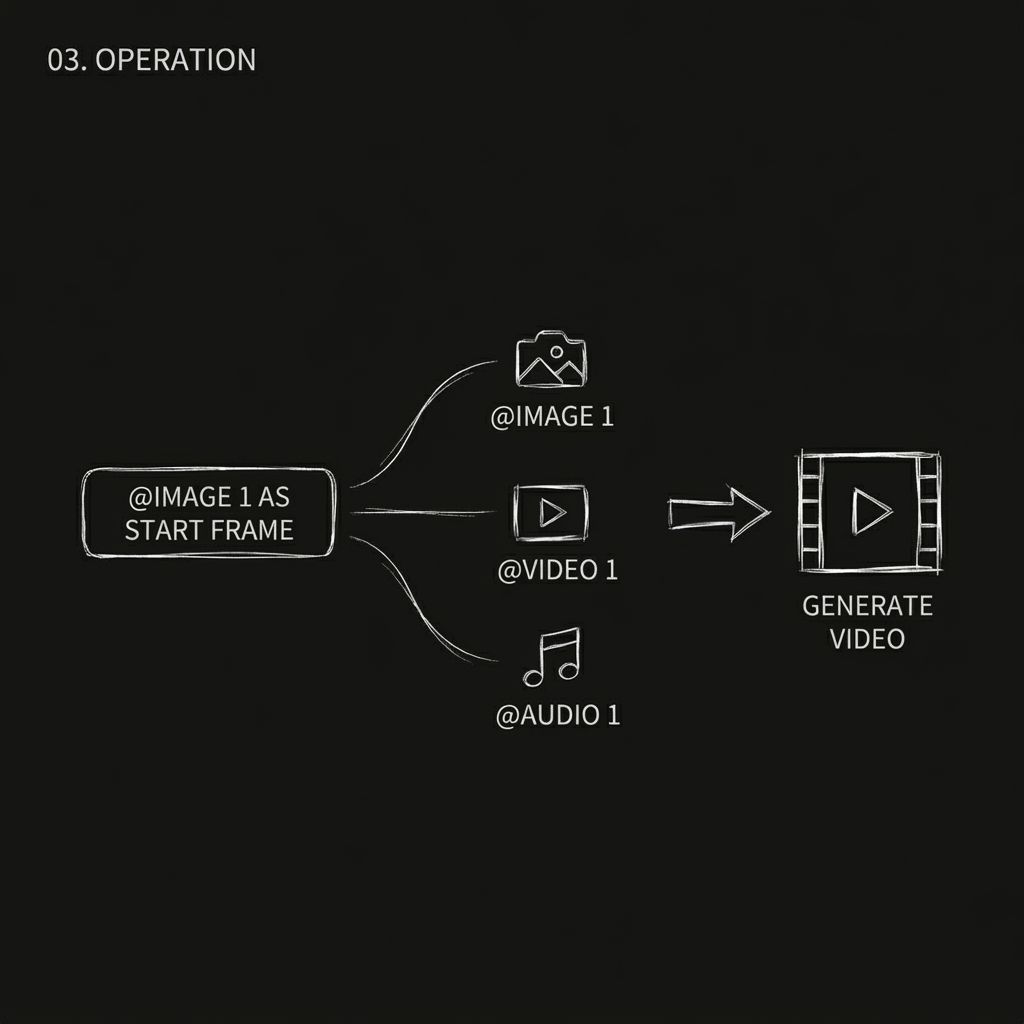
Passaggio 3. Assegnare un ruolo a ciascuna risorsa utilizzando "@" (passaggio più importante)
Questa è l'interazione principale in Seedance 2.0, ma anche la parte che molti principianti tendono a trascurare.
Dopo aver caricato le risorse, è necessario indicare esplicitamente al modello a cosa serve ciascuna di esse utilizzando @nome risorsa all'interno del prompt. Il modello non indovina. Se non lo si spiega chiaramente, potrebbe utilizzare le risorse in modo errato.
Per esempio:
- @Immagine 1 come primo fotogramma
- @Video 1 come riferimento della telecamera
- @Audio 1 per la musica di sottofondo
Come attivare “@”
Metodo 1
Digita il simbolo "@" direttamente nella casella di input. Apparirà un elenco di tutte le risorse caricate. Fai clic su quella a cui desideri fare riferimento e verrà inserita nel prompt.
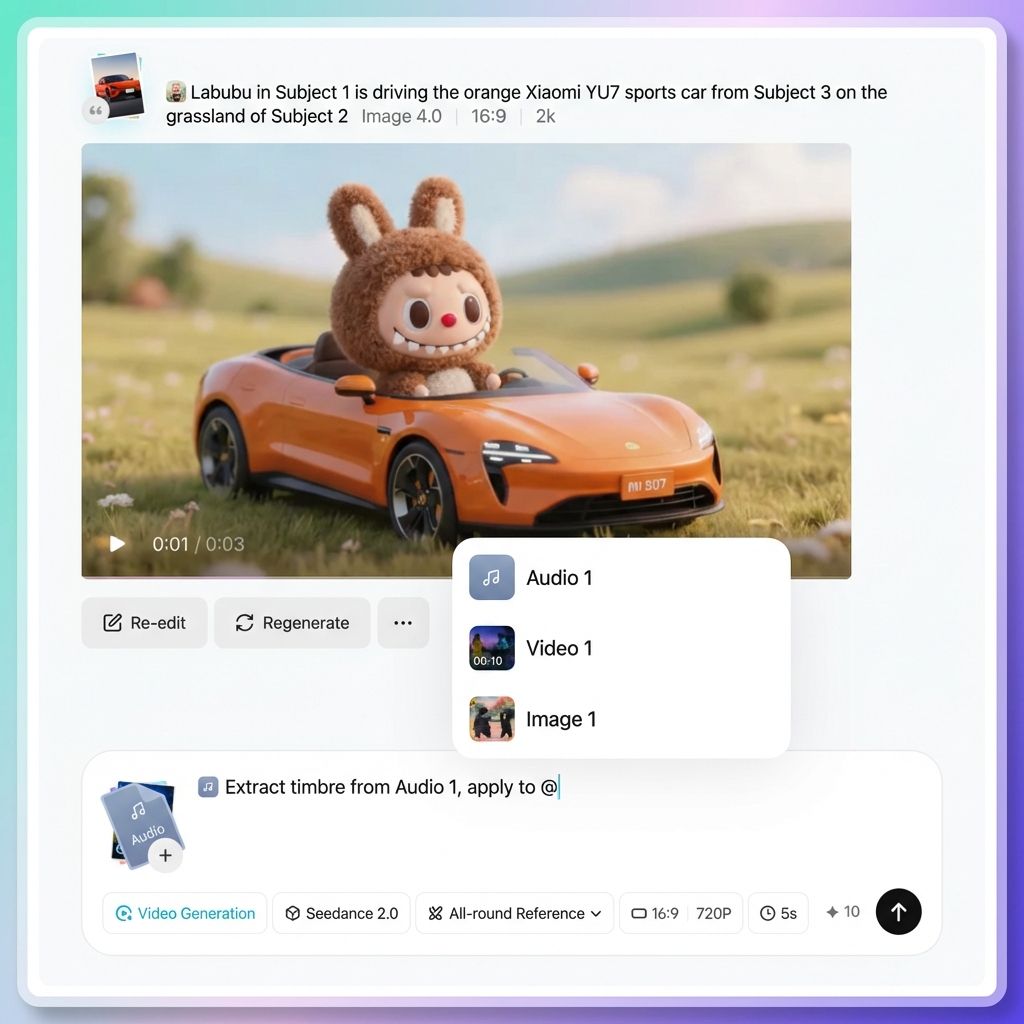
Metodo 2
Fare clic sul pulsante "@" nella barra degli strumenti dei parametri accanto alla casella di input. Verrà visualizzato anche l'elenco delle risorse.
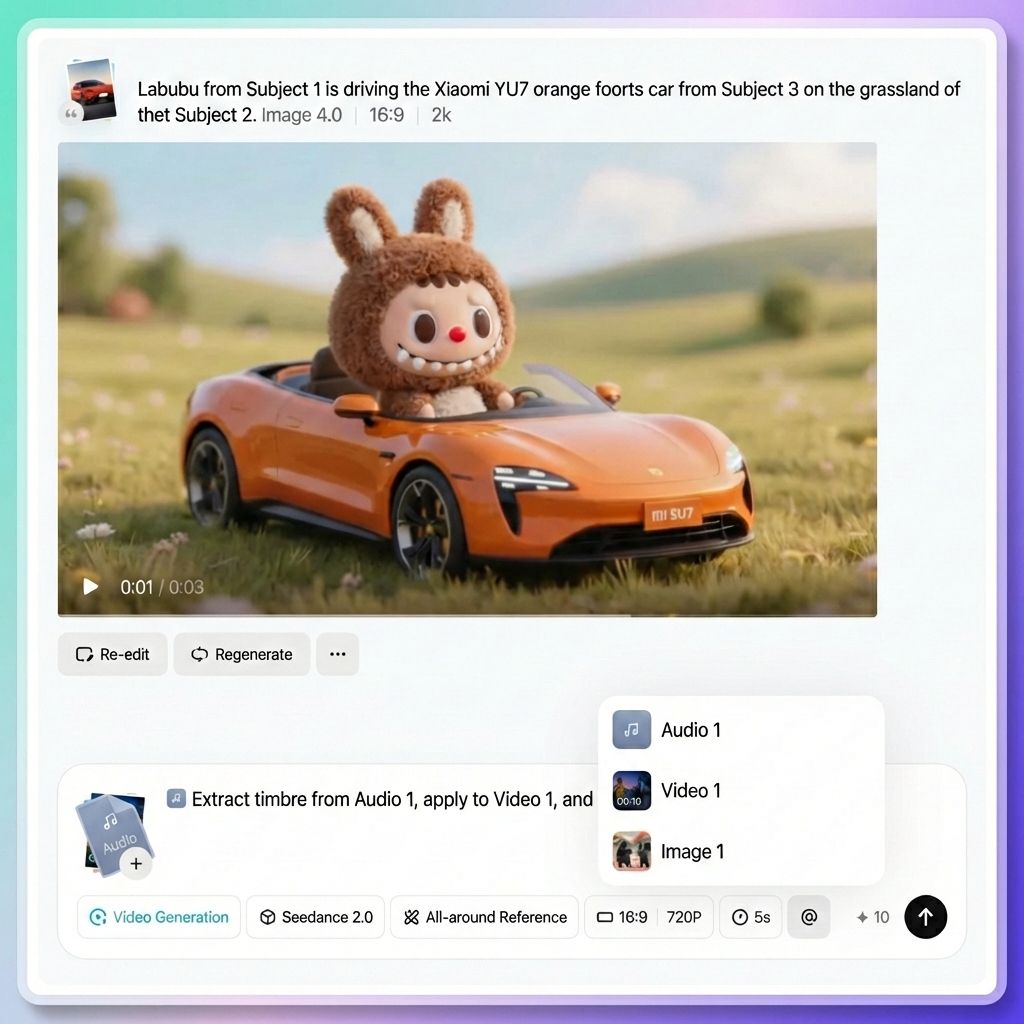
Esempi di utilizzo corretto di “@”
- Specificare il primo fotogramma e fare riferimento a: @Image 1 come primo fotogramma, fare riferimento alla lingua della telecamera di @Video 1 e utilizzare @Audio 1 per la musica di sottofondo
- Specificare i ruoli dei personaggi: il personaggio femminile in @Image 1 come personaggio principale e il personaggio maschile in @Image 2 come ruolo di supporto
- Specifica il riferimento al movimento della telecamera: fai riferimento completo a tutti i movimenti e alle transizioni della telecamera da @Video 1
- Specificare i riferimenti alla scena: utilizzare @Image 3 come riferimento per la scena a sinistra e @Image 4 come riferimento per la scena a destra
- Specificare il riferimento all'azione: il personaggio in @Image 1 dovrebbe fare riferimento ai movimenti di danza di @Video 1
- Specificare il riferimento vocale: la voce della narrazione deve fare riferimento al tono di voce di @Video 1
Insidia comune a cui fare attenzione
Quando si lavora con molte risorse, verificare sempre che ogni riferimento "@" corrisponda al file corretto. Se si fa riferimento a un'immagine come se fosse un video o si assegna accidentalmente l'immagine del Personaggio A al Personaggio B, l'output può rapidamente diventare caotico.
Puoi passare il mouse su qualsiasi risorsa referenziata nel prompt per visualizzarne l'anteprima e assicurarti che tutto sia collegato correttamente.
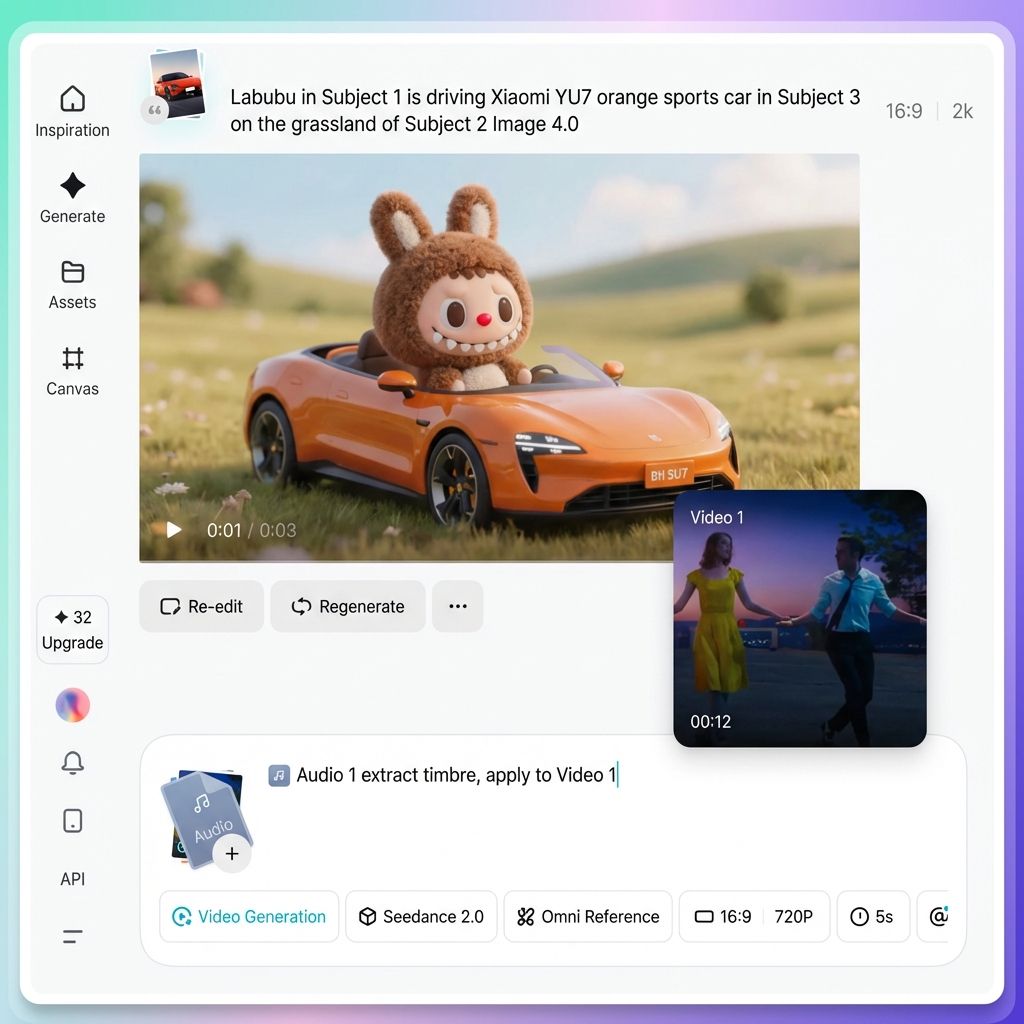
Fase 4. Scrivi un prompt chiaro ed efficace
Dopo aver assegnato i ruoli a tutte le risorse utilizzando "@", il resto consiste nel descrivere gli elementi visivi e le azioni desiderati in linguaggio naturale.
Ecco quattro consigli pratici per scrivere prompt migliori.

Suggerimento 1. Scrivi con una struttura cronologica
Se il tuo video contiene più scene o cambi narrativi, è meglio descriverli in segmenti in base al tempo.
Per esempio:
0–3 secondi
Il protagonista maschile solleva un pallone da basket, guarda verso la telecamera e dice: "Volevo solo bere qualcosa. Sto davvero per viaggiare nel tempo?"
4–8 secondi
La telecamera trema improvvisamente e violentemente. La scena si sposta su una notte piovosa in un'antica residenza. Una protagonista femminile in costume tradizionale guarda freddamente verso la telecamera.
9–13 secondi
La telecamera inquadra un personaggio vestito con abiti della dinastia Ming...
Scrivere in questo modo aiuta il modello a comprendere con maggiore precisione il ritmo e il contenuto di ogni segmento.
Suggerimento 2. Sii esplicito riguardo a "riferimento" rispetto a "modifica"
Questi due concetti non sono la stessa cosa.
"Fare riferimento al movimento della telecamera di @Video 1" significa utilizzare lo stile del movimento della telecamera per generare nuovi contenuti.
"Sostituire il personaggio femminile in @Video 1 con un'artista lirica tradizionale" significa modificare il video originale stesso.
Sii chiaro su quale vuoi, in modo che il modello possa rispondere correttamente.
Suggerimento 3. Sii specifico con il linguaggio della telecamera
Non preoccuparti di scrivere troppo. La comprensione del linguaggio della telecamera da parte della modella è ora molto solida.
Spingere, tirare, spostare, inseguire, dolly, orbitare, riprese dall'alto, riprese dal basso, riprese in un solo piano sequenza, zoom Hitchcock, obiettivi fisheye. Comprende tutti questi termini professionali.
Anche se non si ha familiarità con la terminologia tecnica, va bene. Anche descrizioni semplici funzionano altrettanto bene, come "la telecamera si sposta lentamente da dietro il personaggio a davanti".
Suggerimento 4. Aggiungi transizioni per azioni continue
Se vuoi che un personaggio esegua una sequenza di azioni collegate, assicurati di descrivere chiaramente le transizioni.
Ad esempio, "il personaggio passa direttamente da un salto a una capriola, mantenendo il movimento continuo e fluido". Questo aiuta a evitare stacchi innaturali nel video finale.
Passaggio 5. Seleziona la durata e genera
Scegli la durata del video che preferisci, compresa tra 4 e 15 secondi.
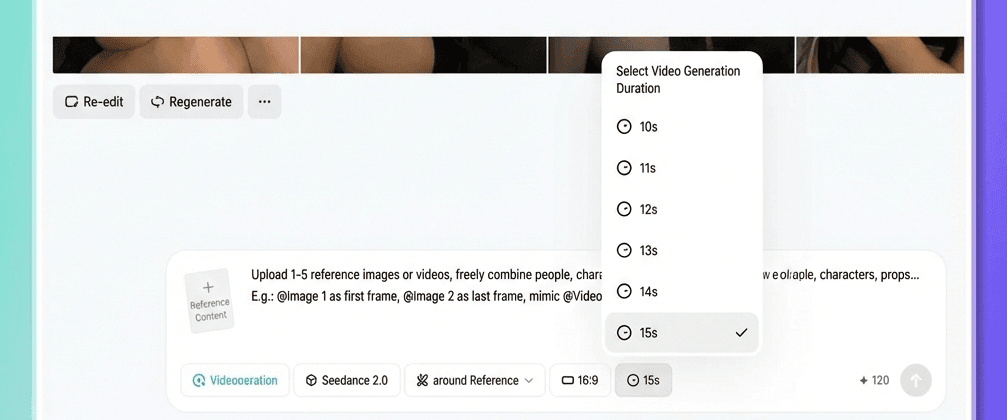
Una nota importante:
Se si desidera estendere un video esistente, ad esempio aggiungendo altri cinque secondi alla fine di una clip, la durata selezionata qui si riferisce solo alla porzione appena generata, non alla lunghezza totale del video. Se si desidera estendere il video di cinque secondi, selezionare cinque secondi.
Quindi fare clic su Genera e attendere il risultato.
Se non sei soddisfatto, sentiti libero di generare più volte. Gli output dell'IA hanno un elemento di casualità, quindi anche con gli stessi input, ogni risultato può essere leggermente diverso. Scegli semplicemente la versione che preferisci.
Un'analisi approfondita delle funzionalità principali di Seedance 2.0
Di seguito sono elencate le dieci funzionalità più potenti di Seedance 2.0. Ognuna è corredata da istruzioni pratiche per l'uso ed esempi concreti.
Capacità 1. Un grande passo avanti nella qualità visiva
Cominciamo dalle basi.
Seedance 2.0 ha subito un aggiornamento completo e fondamentale. La fisica è più precisa, i movimenti sono più fluidi e gli stili visivi rimangono più coerenti in tutta la scena.
Al livello più elementare della generazione delle immagini, si è verificato un salto qualitativo:
- Fisica più realistica : il movimento degli abiti, gli schizzi d'acqua e le collisioni degli oggetti si comportano tutti in modo più naturale.
- Movimenti più fluidi e naturali : camminare, correre e perfino le azioni più complesse non sembrano più rigide o meccaniche.
- Comprensione più accurata delle istruzioni : se dici "una ragazza che appende i vestiti con grazia", capisci davvero cosa significa "con grazia".
- Maggiore coerenza stilistica : lo stile visivo rimane coerente dall'inizio alla fine, senza bruschi cambiamenti.

Esempio di utilizzo
Una ragazza appende con grazia i vestiti ad asciugare. Dopo averne finito uno, ne prende un altro da un secchio e lo scuote con forza.
Cosa significa questo in pratica?
Quando si crea una scena come "una ragazza che appende con grazia i vestiti, poi ne prende un altro da un secchio e lo scuote con forza", il movimento del tessuto, la forza nelle sue braccia e la consistenza del tessuto sembrano tutti straordinariamente vicini a un filmato reale.
Anche scene più complesse sono facilmente realizzabili.
La telecamera segue un uomo vestito di nero mentre fugge a tutta velocità. Un gruppo di persone lo insegue alle spalle. L'inquadratura passa a una visuale laterale. Nel panico, l'uomo si schianta contro un chiosco di frutta a bordo strada, cade, si rialza e continua a correre.
Nella versione 2.0 è ora possibile generare in modo coerente scene che includono sequenze di inseguimento, collisioni e transizioni dinamiche della telecamera.
Ci sono esempi ancora più estremi. Alcuni creatori hanno utilizzato un singolo prompt per far sì che un personaggio all'interno di un dipinto allungasse di nascosto la mano per prendere una lattina di Coca-Cola, ne bevesse un sorso, la riponesse rapidamente sentendo dei passi e poi passasse a un'inquadratura finale che si sposta verso uno sfondo nero, mostrando solo la lattina di Coca-Cola con sottotitoli artistici. Questo livello di complessità narrativa sarebbe stato quasi impensabile prima.
Capacità 2. Combinazione multimodale libera
Questo è l'aggiornamento più importante della versione 2.0. Ora puoi utilizzare qualsiasi tipo di materiale come riferimento.
La formula può essere riassunta come segue:
Seedance 2.0 = riferimento multimodale + forte generazione creativa + comprensione precisa delle istruzioni
Puoi fare riferimento a:
- Azioni, effetti e formati visivi
- Movimento della telecamera e linguaggio delle inquadrature
- Aspetto del personaggio e stile della scena
- Suono e ritmo musicale

Consigli pratici
| Cosa vuoi fare | Come scrivere il prompt |
| Hai un'immagine fotogramma chiave e vuoi fare riferimento al movimento del video | "@Image 1 come fotogramma chiave, fai riferimento al movimento della telecamera da @Video 1" |
| Estendi un video esistente | "Estendi @Video 1 di 5 secondi" (Imposta la durata della generazione a 5 secondi) |
| Combina più video | "Inserisci una scena tra @Video 1 e @Video 2, il contenuto è xxx" |
| Utilizzare l'audio di un video | Non è necessario caricare l'audio separatamente, basta fare riferimento direttamente al video |
| Azione continua | "Il personaggio passa direttamente dal salto alla capriola, mantenendo il movimento fluido e continuo" |
Capacità 3: Miglioramento significativo della coerenza
Chiunque abbia lavorato con l'intelligenza artificiale nei video sa che la coerenza è il problema più frustrante.
I volti cambiano da uno scatto all'altro, i dettagli dei prodotti scompaiono quando cambia l'angolazione e gli stili delle scene cambiano improvvisamente.
La versione 2.0 si impegna seriamente per risolvere questo problema.
Dopo aver caricato un'immagine di riferimento del personaggio, l'aspetto, l'abbigliamento e la postura della persona rimangono coerenti per l'intero video. Lo stesso vale per le presentazioni dei prodotti. Ruotando una borsa da più angolazioni, i dettagli della parte anteriore, laterale e del materiale rimangono intatti.
Elementi che possono rimanere coerenti:
- Caratteristiche del viso (struttura del viso, tono della pelle, stile di espressione)
- Dettagli dell'abbigliamento (texture, colori, motivi)
- Elementi del marchio (logo, tipografia, schema dei colori)
- Stile della scena (illuminazione, atmosfera, tonalità del colore)
Esempio di utilizzo
L'uomo @Image1 cammina lungo un corridoio dopo il lavoro, con un'aria esausta. I suoi passi rallentano. Si ferma davanti alla porta d'ingresso, fa un respiro profondo per ricomporsi, cerca le chiavi, apre la porta ed entra. La sua giovane figlia e il suo cagnolino gli corrono incontro felici e lo abbracciano.

Facendo riferimento a @Image1, l'aspetto del personaggio rimane coerente per tutta la sequenza.
Capacità 4: Riproduzione precisa del movimento e dell'azione della telecamera
Questa è una delle caratteristiche più discusse della versione 2.0.
In passato, se si voleva che l'intelligenza artificiale imitasse i movimenti della telecamera cinematografica, bisognava scrivere un lungo elenco di termini tecnici e sperare nel meglio, altrimenti semplicemente non avrebbe funzionato.
Ora bastano due passaggi:
Carica un video di riferimento con il movimento della telecamera che preferisci, quindi scrivi:
"Fai riferimento al movimento della telecamera da @Video1."
Il modello analizza la logica della telecamera nel video di riferimento (spinta, trazione, panoramica, tracciamento, orbita, zoom, ripresa continua, ecc.) e applica lo stesso stile di movimento al nuovo contenuto.
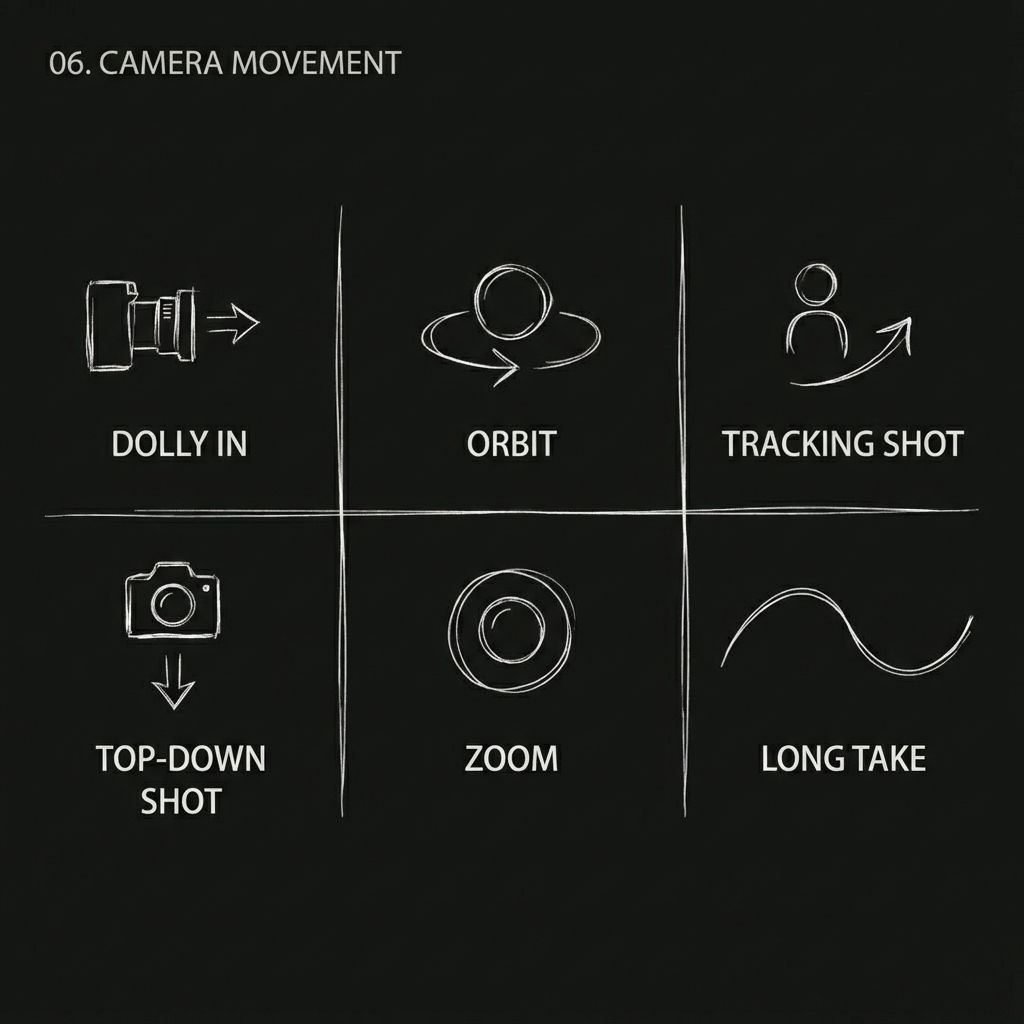
Movimenti della telecamera che possono essere replicati:
- Zoom di Hitchcock
- Ripresa di tracciamento dell'orbita
- Una ripresa continua
- Riprese push/pull/pan/tracking
- Ripresa dal basso
- Vista dall'alto a volo d'uccello
Esempio: Ricreare una scena classica di Wuxia
Capacità 5. Ricreazione precisa di modelli ed effetti creativi
Hai notato un concept pubblicitario, un effetto di transizione o una clip di un film che ti piace?
Caricalo direttamente come riferimento. Il modello può identificare il ritmo del movimento, la struttura visiva e il linguaggio della telecamera al suo interno, aiutandoti a ricreare la tua versione.
Tipi di contenuti creativi che possono essere ricreati:
- Transizioni creative, come la rottura di puzzle, la dispersione di particelle e le transizioni di portale in stile iride
- Stili pubblicitari finiti
- Modifica del ritmo in stile MV
- Riprese con effetti speciali cinematografici
- Effetti di trasformazione dell'outfit e di scambio del viso
Esempio:
Effetti speciali al massimo...
Capacità 6. Estensione e continuazione video
Hai già un video di cui sei soddisfatto e vuoi continuare a raccontarne la storia? O magari vuoi aggiungere una storia di fondo prima della clip esistente? La funzione di estensione video gestisce entrambe le cose.
Estendere in avanti
Carica il video esistente e scrivi "estendere @Video 1 di X secondi", seguito da una descrizione delle nuove scene che vuoi generare.
Estendere all'indietro
Scrivi "estendere X secondi prima" e aggiungi una descrizione della trama precedente che vuoi creare.
Regole di utilizzo
Di' chiaramente al modello: "estendere @Video 1 di X secondi".
Durante la generazione, seleziona una durata pari alla lunghezza dell'estensione. Ad esempio, se desideri estendere di cinque secondi, scegli cinque secondi come durata della generazione.
Nella parte estesa è possibile includere nuovi elementi della trama e descrizioni visive.
Sono supportate sia l'estensione in avanti che quella all'indietro.
Esempio di utilizzo
Facendo riferimento a immagini e video, la clip originale di due secondi sopra può essere estesa a quindici secondi.
La parte estesa può essere descritta in dettaglio, includendo i movimenti della telecamera, gli elementi visivi e il testo sullo schermo.
Capacità 7. Audio più realistico
I video generati dalla versione 2.0 sono dotati di effetti sonori e musica di sottofondo integrati e la qualità audio complessiva è notevolmente migliorata rispetto a prima.
Ecco alcuni casi d'uso correlati all'audio.
Riferimento del tono della voce
Carica un video o una clip audio e lascia che il modello ne imiti il tono di voce o lo stile di narrazione.
Dialogo multilingue
I personaggi parlano cinese, inglese, spagnolo, coreano e altre lingue. La comunicazione emotiva è gestita molto bene.
Dialogo multi-personaggio
Un singolo video può presentare più personaggi, ognuno dei quali recita le proprie battute. Esempi di successo sono i talk show con cani e gatti, i dialoghi dei drammi in costume e le conversazioni tattiche militari.
Supporto dialettale
Alcuni creatori sono riusciti a creare personaggi che parlano in dialetto del Sichuan mentre ordinano un tè al latte. Il risultato è sorprendentemente autentico.
Abbinamento degli effetti sonori
Passi, tuoni, rumori della folla, collisioni di attrezzature e altri suoni ambientali possono essere tutti generati con ragionevole precisione.
Capacità 8. Riprese in un'unica ripresa più coerenti
Una ripresa "one-take" richiede che la scena rimanga continua per un periodo di tempo prolungato, gestendo al contempo complesse transizioni spaziali e movimenti della telecamera. Questa è sempre stata una sfida difficile per l'intelligenza artificiale.
Seedance 2.0 ha fatto notevoli progressi in questo ambito. Se si caricano più immagini da scene diverse e si scrive qualcosa come "una carrellata continua che segue un corridore dalla strada su per le scale, attraverso un corridoio, sul tetto e infine si affaccia sulla città", il modello può completare transizioni naturali tra le scene senza interruzioni evidenti.
Sono possibili anche sequenze in un'unica ripresa più complesse. Ad esempio, "da una prospettiva in prima persona, guarda attraverso il finestrino di un aereo dove le nuvole si trasformano in gelato, quindi sposta la telecamera all'interno della cabina mentre il personaggio prende il gelato e ne dà un morso".
Anche questo tipo di sequenza in un'unica ripresa, che prevede cambi di prospettiva e un mix di realismo e fantasia, può essere gestita da Seedance 2.0.
Ci sono anche scene in un solo piano sequenza in stile thriller di spionaggio. La telecamera segue un'agente in rosso che si muove tra la folla. Gira un angolo e incontra una ragazza mascherata, poi continua l'inseguimento fino a una villa dove la vittima scompare, il tutto senza un singolo stacco.
Raggiungere questo livello di densità narrativa in una ripresa continua è già piuttosto impressionante.
Esempio di utilizzo
@Image1 @Image2 @Image3 @Image4 @Image5, una ripresa continua che segue un corridore dalla strada su per le scale, attraverso un corridoio, sul tetto e infine si affaccia sulla città.
Mancia
Disporre più immagini in sequenza. Il modello presenterà queste scene in ordine all'interno della ripresa continua.
Capacità 9. Montaggio video AI
Hai già un video e non vuoi partire da zero, ma modificarne solo una parte? Ora puoi utilizzare un video esistente come input e apportare modifiche mirate.
Sostituzione del personaggio
Sostituisci il personaggio A nel video con il personaggio B, mantenendo invariate le azioni e le espressioni originali. Ad esempio, "sostituisci la cantante solista nel Video 1 con il protagonista maschile dell'Immagine 1, replicando integralmente i movimenti originali".
Inversione di trama
Mantenete invariate la scena e i personaggi, ma riscrivete completamente la trama. Alcuni autori hanno trasformato una romantica scena di osservazione della luna su un ponte in un colpo di scena drammatico in cui il protagonista maschile spinge la protagonista femminile in acqua. Altri hanno trasformato una tesa trattativa al bar in un momento comico in cui qualcuno tira fuori un enorme sacchetto di snack.
Modifica dell'elemento
Cambia acconciatura, aggiungi oggetti di scena o cambia sfondo. Ad esempio, "cambia l'acconciatura della donna nel Video 1 con lunghi capelli rossi e fai in modo che il grande squalo bianco dell'Immagine 1 emerga lentamente a metà strada dietro di lei".
Integrazione del marchio
Inserisci elementi del brand in un video esistente. Ad esempio, aggiungi un primo piano di un sacchetto di carta con il logo del brand in un video di pollo fritto.
Esempio: sostituzione del carattere:
Ricrea Black Myth: Wukong, poi fallo combattere contro Capitan America.
Capacità 10: Modifica sincronizzata al ritmo
Carica un video musicale ritmato come riferimento. Il modello è in grado di rilevare i cambi di tempo e di adattare i tagli di scena con precisione a ritmo.
Sincronizzazione del ritmo di base
Carica il materiale fotografico e un video musicale di riferimento, quindi scrivi:
“Sincronizza le immagini al ritmo di @Video.”
Sincronizzazione dinamica del battito
Scrivere:
“Rendere i personaggi più dinamici, migliorare lo stile visivo generale sognante, aumentare la tensione visiva e adattare la scala delle inquadrature secondo necessità in base alla musica.”
Sincronizzazione del ritmo del paesaggio
Quando si combinano più immagini di paesaggi con la musica, scrivere:
“Le scene paesaggistiche richiamano il ritmo di @Video e sincronizzano le transizioni con lo stile visivo e i ritmi musicali.”
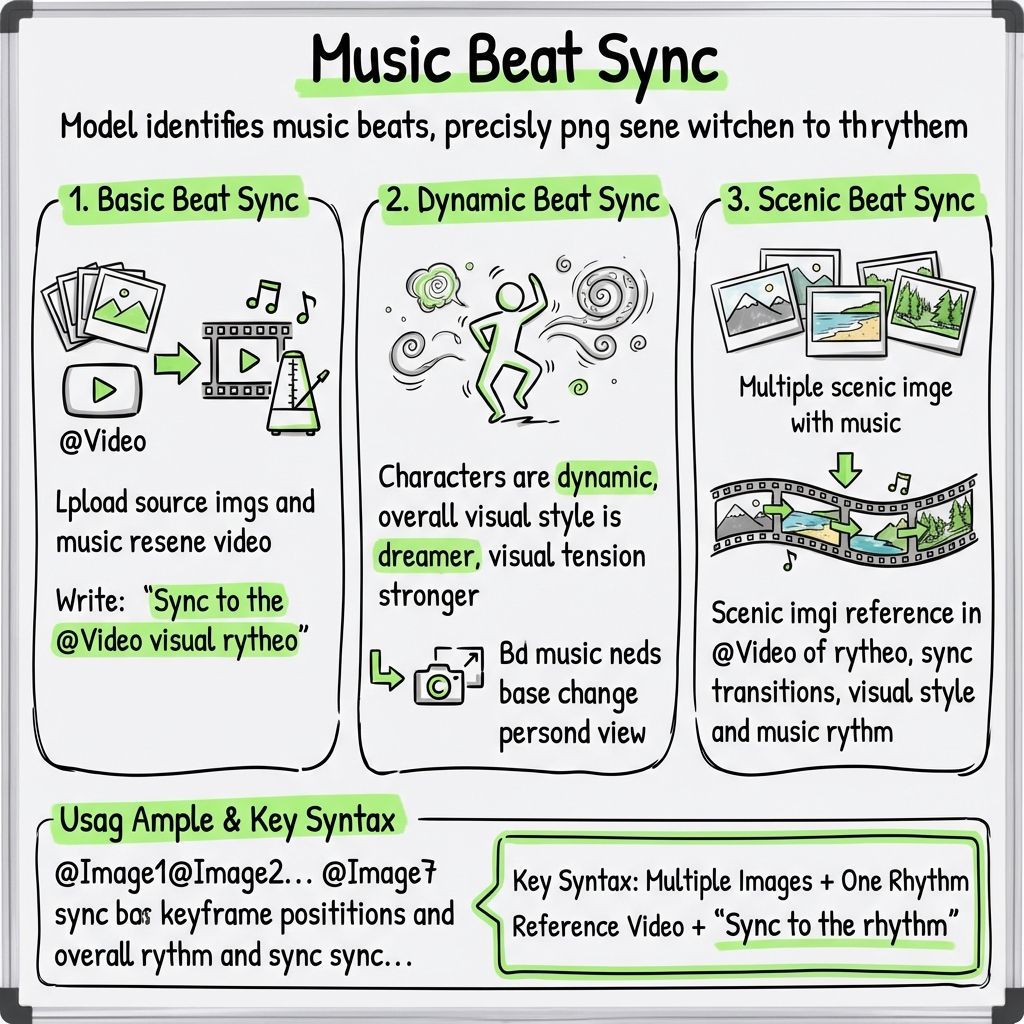
Esempio di utilizzo
@Immagine1 @Immagine2 @Immagine3 @Immagine4 @Immagine5 @Immagine6 @Immagine7
Sincronizza queste immagini in base alle posizioni dei fotogrammi chiave e al ritmo generale di @Video. Rendi i personaggi più dinamici e dona allo stile visivo complessivo un'atmosfera più sognante.
Formula chiave
Immagini multiple + un video di riferimento al ritmo + "Sincronizza al ritmo".
Capacità 11. Prestazioni emotive più convincenti
Espressioni facciali rigide e transizioni emotive imbarazzanti sono da tempo problemi comuni nei video generati dall'intelligenza artificiale. La versione 2.0 mostra un netto miglioramento in quest'area.
Puoi caricare un video come riferimento emotivo e lasciare che la modella imiti i cambiamenti di espressione che ne derivano. Ad esempio, "la donna in @Immagine 1 cammina verso lo specchio, si ferma a riflettere, poi improvvisamente scoppia a urlare. L'azione di afferrare lo specchio e l'intensità emotiva del crollo dovrebbero fare pieno riferimento a @Video 1".

È anche possibile descrivere con precisione le transizioni emotive nel testo. Ad esempio, il passaggio da un atteggiamento gentile a uno freddo, da teso a rilassato, o dalla rabbia al sollievo. Il modello può comprendere questi cambiamenti emotivi e rifletterli attraverso le espressioni facciali, il linguaggio del corpo e il tono della voce.
Può persino gestire espressioni esagerate con un tono comico. Ad esempio, "il personaggio alza improvvisamente lo sguardo e inizia a gridare a gran voce".