



Seedance 2.0:人人都是导演的时代,一本完整的实操指南
过去几天,字节跳动的AI视频模型Seedance 2.0彻底席卷了互联网。
现在到处都是用 Seedance 2.0 生成的视频。
人们正利用它制作电影级别的追逐戏。其他人则用它来重现通常在大制作广告中才能看到的电影级镜头运动。甚至有人把它拍成了时代剧、穿越剧或纯粹的武术动作片——这些镜头如此清晰细腻,以至于你很难分辨它们究竟是人工智能生成的,还是由真人演员拍摄的。
说实话,这绝非夸张。
通过此次更新,Seedance 2.0 基本上将人工智能视频创作的门槛降到了最低。
话不多说,让我们先来看一段简短的蒙太奇 ↓
那么……看起来怎么样?
为什么它能如此迅速地爆红?因为它终于解决了困扰创作者多年的一个难题:人工智能视频过去专注于内容生成,而现在,它关注的是内容控制。
自由混合图像、视频、音频和文本——任何人都可以执导。

这一次,情况有所不同。
Seedance 2.0 不再仅仅是一个文本转视频工具,它已经发展成为一个真正的多模态视频创作平台,能够理解创作意图。
你可以同时输入图片、视频片段、音频和文本。你只需告诉它每种素材的作用,它就会将所有素材融合在一起,制作成一个完整的视频。
听起来有点抽象?没关系。
我会一步一步地讲解每个功能和工作流程,并向你展示人们究竟是如何使用它的。
首先,Seedance 2.0 究竟能做什么?
Seedance 2.0 的核心在于一项关键升级:多模态。
早期的AI 视频模型,你的输入选项通常仅限于两件事:要么编写文本提示,要么上传单个第一帧图像。
如果你想控制镜头运动、面部表情或背景音乐节奏,一切都必须通过文字来表达。而最终效果如何,几乎完全取决于你编写提示的能力。
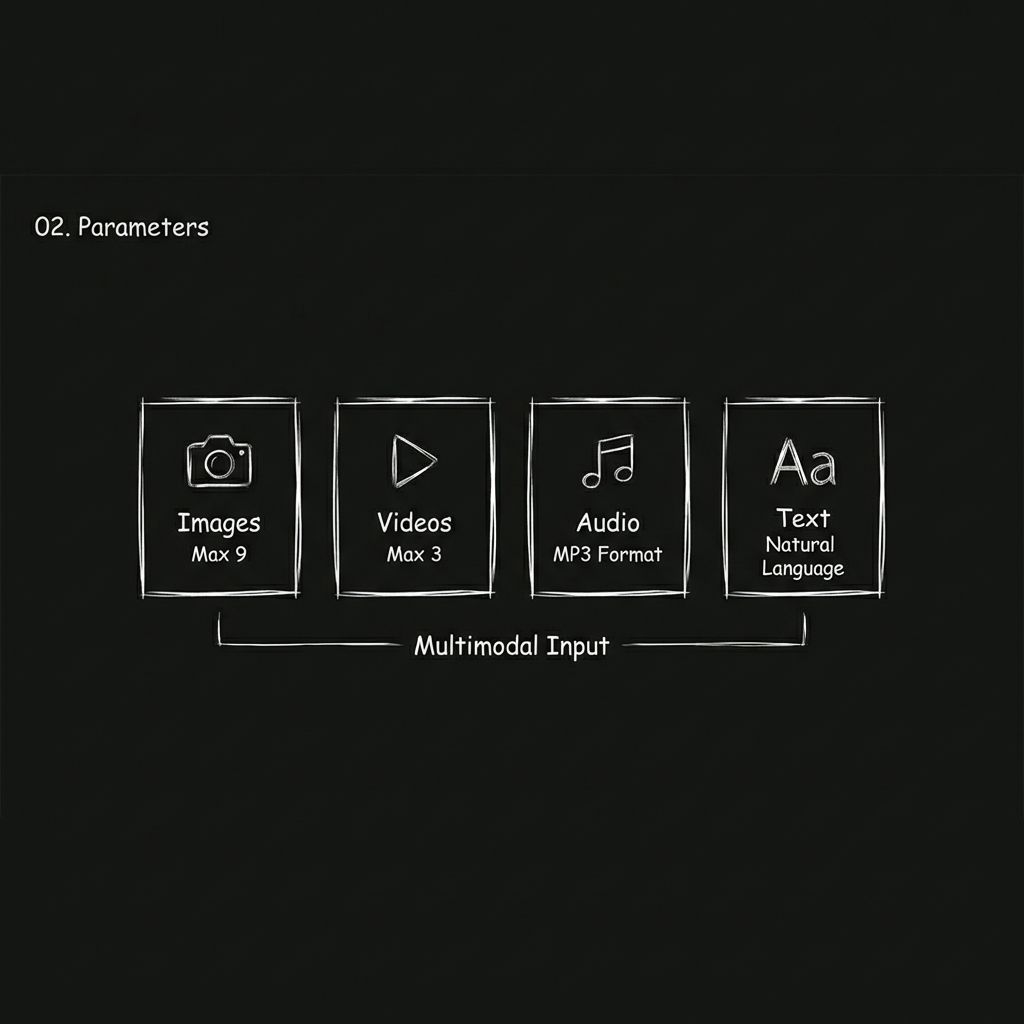
Seedance 2.0 通过将输入扩展到四种不同的模式来改变这一点。
图片
您最多可以上传 9 张图片。这些图片可以用来展示角色外貌、场景风格、服装细节、产品图片,甚至是故事板帧。
视频
您最多可以上传 3 个视频片段,总时长不超过 15 秒。模型可以从这些片段中学习镜头运动、动作节奏和转场风格。实际上,这相当于给模型提供了一个视觉样本进行学习。
声音的
支持上传MP3文件,最多3个,总时长不超过15秒。您可以指定背景音乐、音效样式,甚至可以参考其他视频的旁白语气。
文本
您只需输入标准自然语言,即可描述您想要的视觉效果、动作和节奏。
所有四种输入方式均可自由组合。所有方式上传的文件总数上限为 12 个。
生成的视频最长可达15秒。您可以选择4到15秒之间的任意时长,输出视频带有内置音效和背景音乐。
简而言之,你终于可以像真正的电影制作人一样指导人工智能了:
- 图片定义了视觉风格。
- 视频定义了运动。
- 音频定义了节奏。
- 文字讲述故事。
Seedance 2.0 输入输出规格
| 范围 | 描述 |
| 图像输入 | 最多 9 张图片 |
| 视频输入 | 最多 3 个视频片段,总时长不超过 15 秒。 |
| 音频输入 | 支持 MP3 格式,最多 3 个文件,总时长不超过 15 秒。 |
| 文本输入 | 自然语言描述(支持英语和中文) |
| 输出持续时间 | 4到15秒 |
| 音频输出 | 内置音效和背景音乐 |
| 文件总数限制 | 所有上传资料最多只能包含 12 个文件。 |
开始之前的小提示:参考资料越多,并不一定能带来更好的结果。
优先上传对视觉效果或节奏影响最大的素材,并合理分配上传名额。
使用方法:分步指南
第一步:选择合适的切入点
打开智梦,找到 Seedance 2.0。
您可以通过集萌平台访问 Seedance 2.0。不久后,它也将在Pollo AI 的图像转视频页面上线。
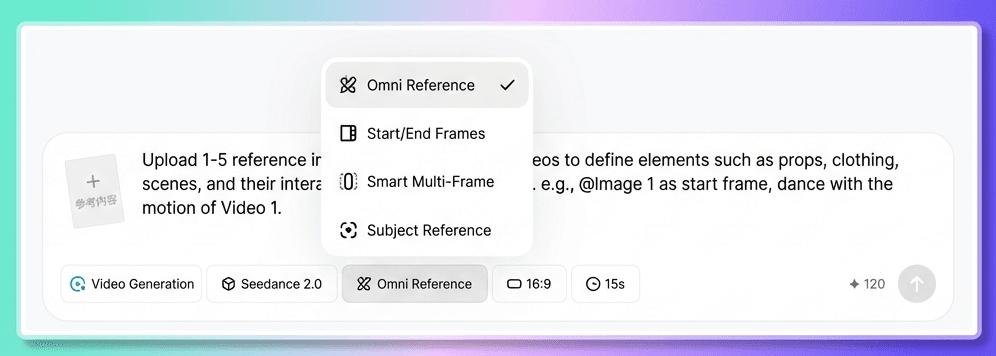
你会看到两个不同的入口。
- 首帧和末帧:当您仅上传单个首帧图像以及文本提示时,请使用此选项。
- 一体化参考:当您需要多模态输入(例如图像、视频、音频和文本的组合)时,请使用此选项。
如何决定使用哪个选项?遵循一个简单的规则:如果您的素材只有一张图片和一段文字,请选择“首尾帧”;如果您有多张图片,或者涉及视频或音频,请选择“一体化参考”。
大多数情况下,一体化参考标准是更佳选择。它支持所有类型的参考输入,也是 Seedance 2.0 全面展现其最新功能的理想之选。
第二步:上传您的素材
点击上传按钮,从本地设备选择文件。图片、视频和音频文件都可以直接拖入。上传完成后,所有素材都会显示在输入区域。您可以将鼠标悬停在每个文件上预览其内容。
上传前的小提示:请仔细考虑哪些素材最重要。您最多可以上传 12 个文件,因此请优先上传对视觉风格和节奏影响最大的文件。
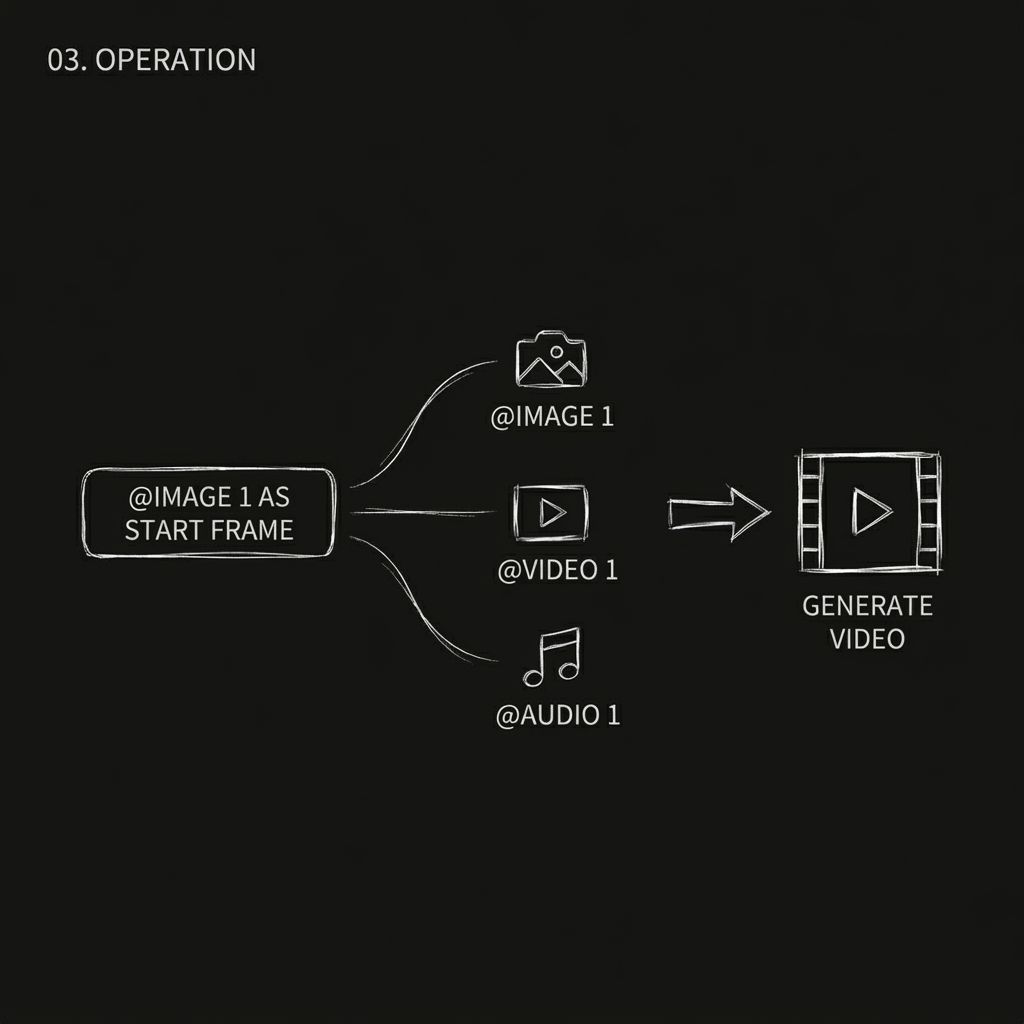
步骤 3. 使用“@”符号为每个资产分配角色(最重要的一步)
这是 Seedance 2.0 的核心交互,也是许多初学者容易忽略的部分。
上传资源后,您需要在提示信息中使用 `@资源名称` 明确告诉模型每个资源的用途。模型不会自动猜测。如果您没有清楚地说明,模型可能会错误地使用资源。
例如:
- @图片 1 作为第一帧
- @视频1作为摄像机参考
- @音频 1 用于背景音乐
如何触发“@”
方法一
直接在输入框中输入“@”符号。此时将显示所有已上传资源的列表。点击您想要引用的资源,它将被插入到提示符中。
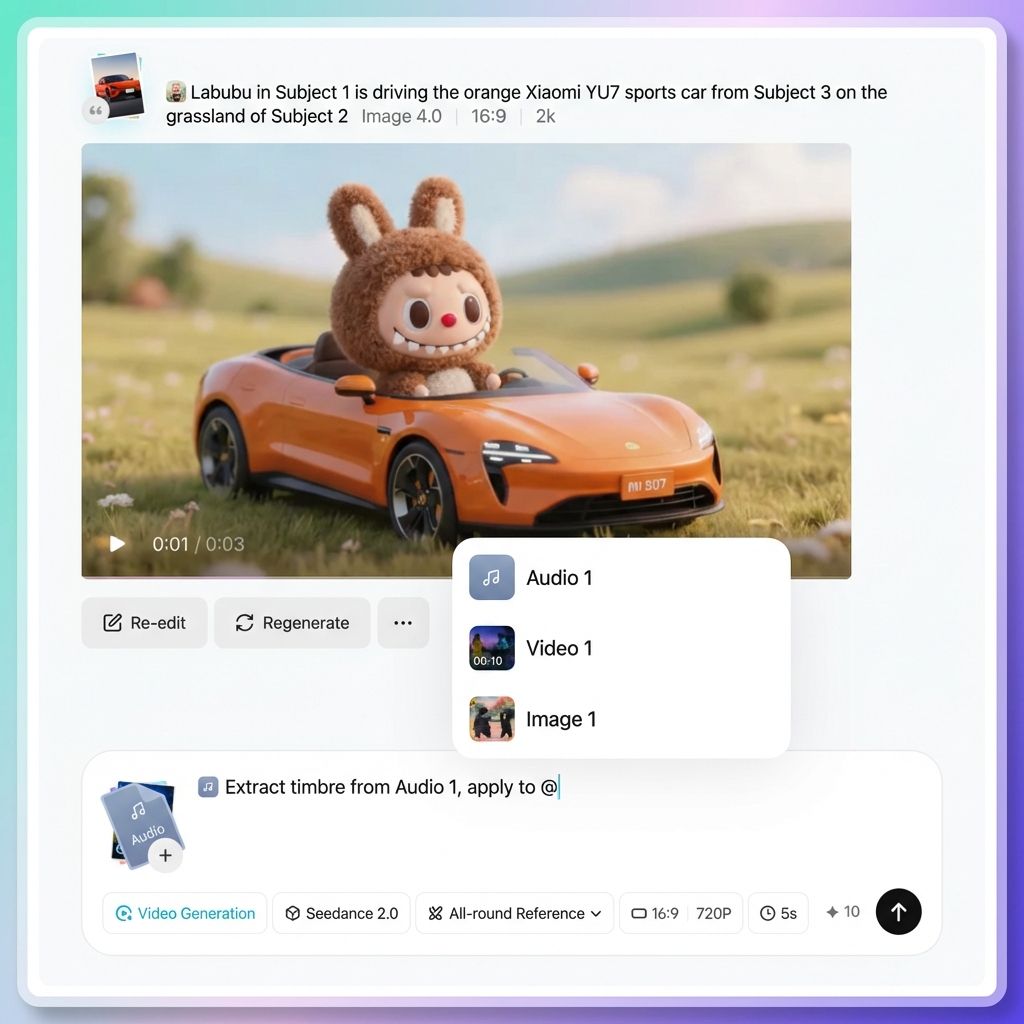
方法二
点击输入框旁边的参数工具栏中的“@”按钮。这将同时显示资产列表。
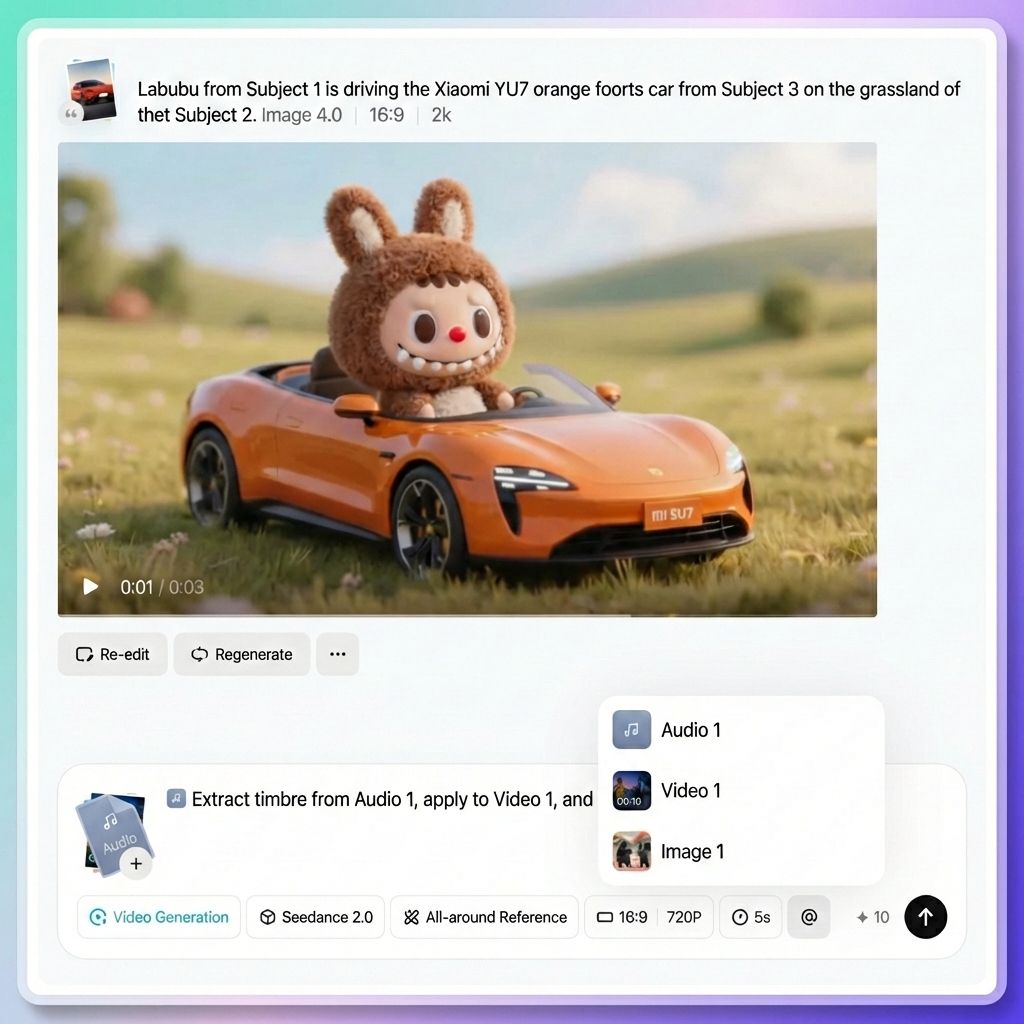
正确使用“@”的示例
- 指定首帧和引用:将 @Image 1 设置为首帧,引用 @Video 1 的摄像机语言,并使用 @Audio 1 作为背景音乐。
- 明确角色定位:@Image 1 中的女性角色为主角,@Image 2 中的男性角色为配角。
- 指定摄像机运动参考:完全参考 @Video 1 中的所有摄像机运动和转场。
- 指定场景参考:使用 @Image 3 作为左侧场景的参考,使用 @Image 4 作为右侧场景的参考。
- 指定动作参考:@Image 1 中的角色应参考 @Video 1 中的舞蹈动作。
- 指定语音参考:旁白语音应参考@Video 1 中的语音语调。
需要警惕的常见陷阱
处理大量素材时,务必仔细检查每个“@”引用是否指向正确的文件。如果将图像引用为视频,或者不小心将角色 A 的图像分配给了角色 B,输出结果很快就会变得混乱不堪。
您可以将鼠标悬停在提示中引用的任何资源上进行预览,并确保所有内容都已正确链接。
第四步:撰写清晰有效的提示语
使用“@”为所有资产分配角色后,剩下的就是用自然语言描述你想要的视觉效果和操作。
以下是撰写更好题目的四个实用技巧。

技巧一:按时间顺序结构写作
如果你的视频包含多个场景或叙事转折,最好按时间顺序分段描述。
例如:
0-3秒
男主角举起手中的篮球,抬头看向镜头,说道:“我只是想喝一杯。难道我真的要穿越时空了吗?”
4-8秒
镜头突然剧烈晃动。画面切换到雨夜,一座古老的宅邸。身着传统服饰的女主角冷冷地看向镜头。
9-13秒
镜头切换到一位身着明朝服饰的人物……
这种写作方式有助于模型更准确地理解每个部分的节奏和内容。
建议二:明确区分“参考文献”和“编辑”
这两个概念并不相同。
“参考 @Video 1 的镜头运动”是指使用其镜头运动风格来生成新内容。
“将 @Video 1 中的女性角色替换为传统歌剧演员”是指修改原视频本身。
请明确说明您想要哪个,以便模型能够做出正确的反应。
技巧 3:使用相机语言时要具体明确
不用担心写太多。该模型现在对相机语言的理解能力非常强。
推拉、摇摄、跟踪、轨道滑轨、环绕拍摄、俯拍、低角度拍摄、一镜到底、希区柯克式变焦、鱼眼镜头。它理解所有这些专业术语。
如果您不熟悉技术术语,也没关系。简单的描述同样有效,例如“镜头缓缓从角色身后移动到前方”。
技巧 4. 为连续动作添加过渡效果
如果你想让角色执行一系列相互关联的动作,一定要清楚地描述动作之间的过渡。
例如,“角色直接从跳跃过渡到翻滚,保持动作的连贯性和流畅性。”这有助于避免最终视频中出现不自然的跳切。
步骤 5. 选择持续时间并生成
选择您需要的视频长度,介于 4 秒到 15 秒之间。
重要提示:
如果您要延长现有视频,例如在片段末尾添加五秒钟,则此处选择的持续时间仅指新生成的部分,而不是视频的总长度。如果您想将视频延长五秒钟,请选择五秒。
然后点击“生成”,等待结果。
如果您不满意,可以多次生成。人工智能的输出结果具有一定的随机性,因此即使输入相同,每次生成的结果也可能略有不同。只需选择您最喜欢的版本即可。
深入了解 Seedance 2.0 的核心功能
以下是 Seedance 2.0 的十大最强大功能。每一项功能都附有实用的使用指南和真实案例。
功能一:视觉质量的重大飞跃
让我们从基础知识开始。
Seedance 2.0 进行了全面的底层升级。物理效果更加精准,动作更加流畅,场景中的视觉风格也更加一致。
图像生成最基本的层面已经发生了质的飞跃:
- 更真实的物理效果:衣服的运动、水花飞溅和物体碰撞都表现得更加自然。
- 更流畅、更自然的动作:行走、跑步,甚至复杂的动作都不再显得僵硬或机械。
- 更准确的指令理解:如果你说“一个女孩优雅地晾衣服”,它就能真正理解“优雅地”的意思。
- 更稳定的风格一致性:视觉风格从始至终保持连贯性,没有突然的转变。

用法示例
一个女孩优雅地晾晒衣服。晾完一件后,她又从桶里拿出一件,用力抖了抖。
这在实践中意味着什么?
当你生成像“一个女孩优雅地晾晒衣服,然后从桶里拿出另一件衣服用力抖动”这样的场景时,布料的运动、她手臂的力量以及布料的质地都感觉非常接近真实影像。
更复杂的场景也完全可以实现。
镜头跟随一名身穿黑衣的男子高速奔跑。一群人从后方追赶。镜头切换到侧视视角。惊慌失措之下,他撞到路边的水果摊,摔倒在地,但很快又爬起来,继续奔跑。
版本 2.0 现在可以一致地生成包含追逐场景、碰撞和动态摄像机切换的场景。
还有更极端的例子。一些创作者仅凭一个提示,就能让画中人物偷偷伸手去拿一罐可乐,喝了一口,听到脚步声后迅速放回原处,然后镜头切换到最后一个画面,画面逐渐拉近,最终定格在黑色背景上,只有可乐罐和艺术化的字幕。这种叙事复杂性在以前几乎是不可想象的。
能力 2. 自由多式联运
这是 2.0 版本中最重要的升级。现在您可以使用任何类型的材料作为参考。
该公式可概括如下:
Seedance 2.0 = 多模态参考 + 强大的创意生成能力 + 精准的指令理解
您可以参考:
- 动作、效果和视觉格式
- 镜头运动和镜头语言
- 角色形象和场景风格
- 声音和音乐节奏

实用技巧
| 你想做什么 | 如何撰写提示 |
| 我有一个关键帧图像,想将其与视频运动关联起来。 | “以@Image 1 为关键帧,参考@Video 1 中的镜头抖动” |
| 扩展现有视频 | 将视频 1 延长 5 秒(设置生成持续时间为 5 秒) |
| 合并多个视频 | “在@Video 1 和 @Video 2 之间插入一个场景,内容为xxx” |
| 使用视频中的音频 | 无需单独上传音频,直接引用视频即可。 |
| 持续行动 | “角色从跳跃直接过渡到翻滚,保持动作流畅连贯。” |
能力3:一致性显著提高
任何接触过人工智能视频的人都知道,一致性是最令人沮丧的问题。
镜头切换时人物面部发生变化,角度改变时产品细节消失,场景风格也突然跳跃。
2.0 版本认真致力于解决这个问题。
上传人物参考图片后,人物的外貌、服装和姿势在整个视频中保持一致。产品展示也是如此。从多个角度旋转包袋时,包袋的正面、侧面和材质细节都保持不变。
可以保持不变的要素:
- 面部特征(面部结构、肤色、表情)
- 服装细节(质地、颜色、图案)
- 品牌元素(标志、字体、配色方案)
- 场景风格(光照、氛围、色调)
用法示例
图片1中的男子下班后沿着走廊走着,看起来很疲惫。他的脚步渐渐慢了下来。他走到家门口停了下来,深吸一口气让自己平静下来,然后摸索着找到钥匙,打开门走了进去。他的小女儿和宠物狗高兴地跑过来,拥抱了他。

通过引用 @Image1,角色的外观在整个序列中保持一致。
功能四:精确的摄像机运动和动作复制
这是 2.0 版本中最受关注的功能之一。
过去,如果你想让人工智能模仿电影镜头运动,要么你得写出一长串技术术语,然后祈祷一切顺利,要么它根本就行不通。
现在只需两步即可:
上传一段包含你喜欢的镜头运动的参考视频,然后写道:
“请参考@Video1中的镜头运动。”
该模型分析参考视频中的摄像机逻辑(推、拉、平移、跟踪、旋转、缩放、连续拍摄等),并将相同的运动风格应用于您的新内容。
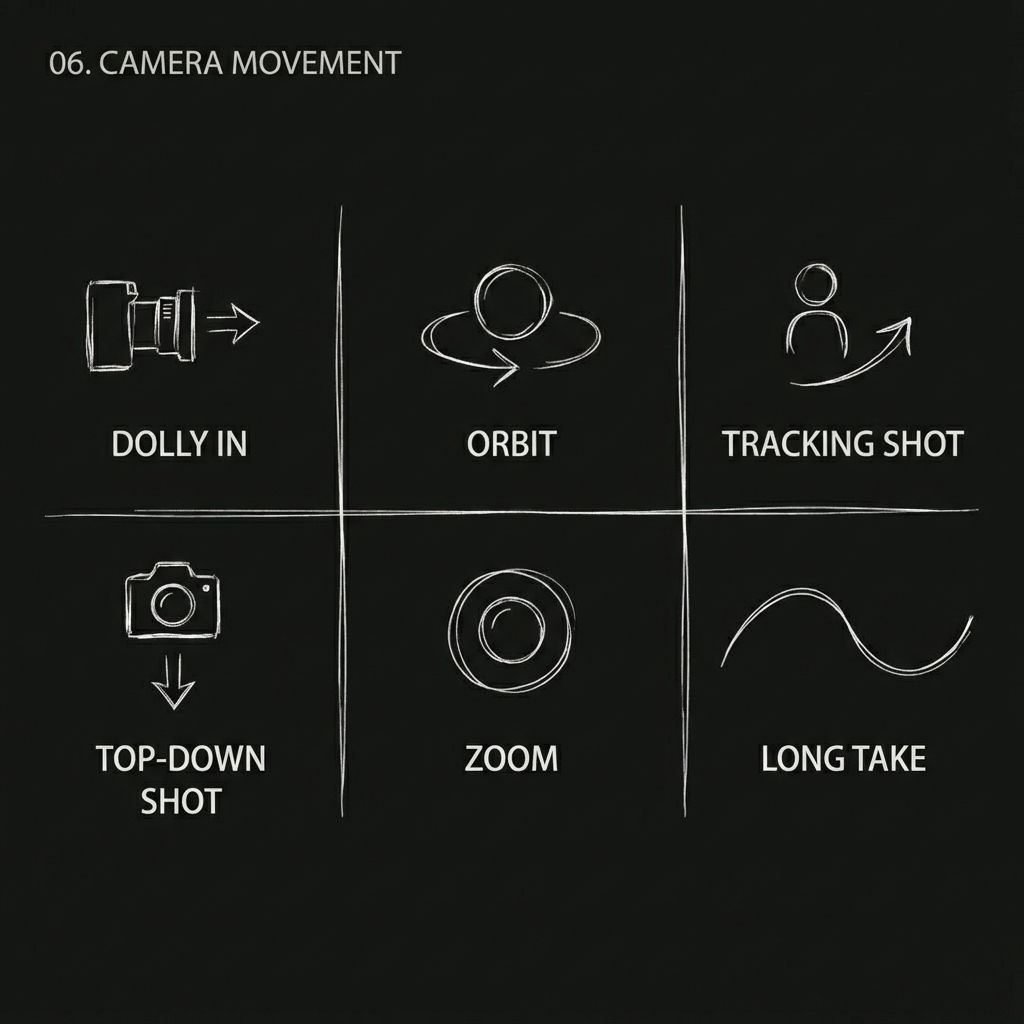
可复制的镜头运动:
- 希区柯克式变焦
- 轨道跟踪拍摄
- 一镜到底
- 推拉/摇摄/跟踪拍摄
- 低角度拍摄
- 鸟瞰图
例如:重现经典武侠场景
功能五:精确再现创意模板和效果
看到喜欢的酷炫广告创意、转场效果或电影片段了吗?
直接上传作为参考。该模型可以识别其中的运动节奏、视觉结构和镜头语言,并帮助您创作自己的版本。
可以重新创作的创意内容类型:
- 创意转场效果,例如拼图破碎、粒子扩散和虹膜式传送门转场
- 成品广告风格
- MV风格的节奏编辑
- 电影特效镜头
- 服装变换和换脸效果
例子:
特效已全部开启……
功能 6. 视频扩展和延续
已经有一段满意的视频,想继续讲述故事?或者想在现有视频片段前添加背景故事?视频扩展功能都能满足这些需求。
向前延伸
上传现有视频,并写上“将@Video 1 延长 X 秒”,然后描述你想生成的新场景。
向后延伸
输入“向前延伸 X 秒”,并添加对你想创建的早期故事情节的描述。
使用规则
明确告诉模型:“将@Video 1 延长 X 秒。”
生成时,请选择与扩展时长相同的持续时间。例如,如果要扩展 5 秒,则将生成时长设置为 5 秒。
您可以在扩展部分添加新的情节元素和视觉描述。
支持向前和向后扩展。
用法示例
通过引用图片和视频,上面原本两秒钟的视频片段可以延长到十五秒钟。
扩展部分可以详细描述,包括摄像机运动、视觉元素和屏幕上的文字。
功能7:更逼真的音频
2.0 版本生成的视频带有内置音效和背景音乐,整体音频质量与以前相比有了显著提高。
以下是一些与音频相关的应用案例。
语音语调参考
上传一段视频或音频片段,让模特模仿其中的说话语气或叙述风格。
多语对话
角色能说中文、英文、西班牙文、韩文等多种语言,情感表达也相当到位。
多角色对话
一段视频可以包含多个角色,每个角色都有自己的台词。成功的例子包括猫狗脱口秀、时代剧对话和军事战术对话。
方言支持
一些创作者成功地创建了用四川方言点奶茶的角色,效果出奇地地道。
音效匹配
脚步声、雷声、人群噪音、设备碰撞声和其他环境声音都可以相当精确地生成。
能力八:更连贯的一镜到底拍摄
“一镜到底”拍摄要求场景在较长时间内保持连续,同时还要处理复杂的空间转换和镜头运动。这对人工智能来说始终是一个难题。
Seedance 2.0 在这方面取得了显著进展。如果您上传多张不同场景的图片,并描述类似“一个连续的跟踪镜头,跟随一名跑步者从街道跑上楼梯,穿过走廊,到达屋顶,最终俯瞰城市”,该模型可以实现场景之间的自然过渡,而不会出现明显的断点。
更复杂的长镜头拍摄也是可能的。例如,“从第一人称视角,透过飞机舷窗,看到云朵变成冰淇淋,然后将镜头拉回机舱,角色拿起冰淇淋咬一口。”
即使是这种涉及视角转换和现实与幻想融合的一镜到底的拍摄场景,Seedance 2.0 也能轻松应对。
影片中还有一些谍战片式的长镜头。镜头跟随一位身穿红衣的女特工穿过人群。她转过一个街角,遇到一个蒙面女孩,然后继续追捕,进入一座豪宅,目标人物在那里消失,整个过程没有一个剪辑。
在一镜到底的镜头中达到这种叙事密度已经相当令人印象深刻了。
用法示例
@Image1 @Image2 @Image3 @Image4 @Image5,一个连续的跟踪镜头,跟随一名跑步者从街道上跑上楼梯,穿过走廊,到达屋顶,最后俯瞰城市。
提示
将多张图片按顺序排列。模特将在连续拍摄中按顺序展示这些场景。
功能9.人工智能视频编辑
已经有视频素材,不想从头开始,只想修改其中的一部分?现在你可以使用现有视频作为输入,进行针对性编辑。
角色替换
将视频中的角色 A 替换为角色 B,同时保持其原有的动作和表情不变。例如,“将视频 1 中的女主唱替换为图片 1 中的男主角,并完全复制其原有的动作。”
剧情反转
保留场景和人物不变,但彻底改写故事情节。有些创作者将桥上浪漫的赏月场景改编成戏剧性的转折,男主角将女主角推入水中。另一些创作者则将紧张的酒吧谈判场景改成喜剧桥段,比如有人突然掏出一大包零食。
元素修改
改变发型、添加道具或更换背景。例如,“将视频 1 中女子的发型改为一头红色长发,并让图片 1 中的大白鲨缓缓出现在她身后。”
品牌整合
将品牌元素插入现有视频中。例如,在炸鸡视频中添加一个带有品牌标志的纸袋特写镜头。
示例——字符替换:
重制黑神话:悟空,然后让他和美国队长对战。
功能 10:节拍同步编辑
上传一段节奏感强的音乐视频作为参考。该模型可以检测节奏变化,并使场景切换精准地落在节拍上。
基本节拍同步
上传图片素材和音乐参考视频,然后写:
“将画面与 @Video 的节奏同步。”
动态节拍同步
写:
“使人物更具动感,增强整体梦幻般的视觉风格,增加视觉张力,并根据音乐需要调整镜头比例。”
景观节拍同步
将多张风景图片与音乐结合使用时,请这样写:
“风景场景参考了@Video的节奏,并将转场与视觉风格和音乐节拍同步。”
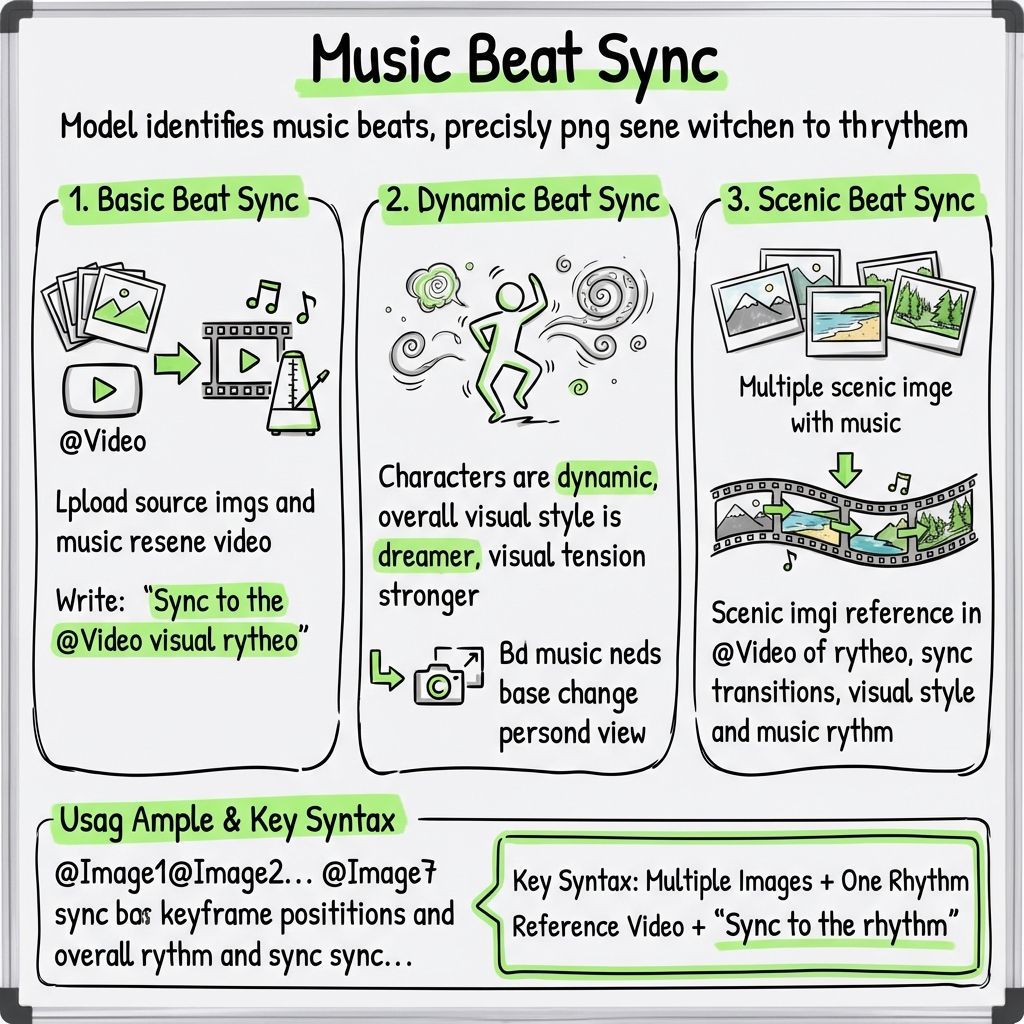
用法示例
@Image1 @Image2 @Image3 @Image4 @Image5 @Image6 @Image7
根据@Video的关键帧位置和整体节奏同步这些图像。使角色更具动感,并赋予整体视觉风格更梦幻的感觉。
关键公式
多张图片 + 一个节奏参考视频 + “与节奏同步”。
能力11. 更具说服力的情感表现
人工智能生成的视频中,面部表情僵硬和情绪转换生硬一直是常见问题。2.0 版本在这方面有了显著改进。
您可以上传一段视频作为情感参考,让模特模仿视频中的表情变化。例如,“@Image 1 中的女子走到镜子前,停顿片刻,陷入沉思,然后突然崩溃尖叫。她抓镜子的动作以及崩溃时的情绪强度应完全参考 @Video 1。”

你也可以用文字精确地描述情绪转变。例如,从温柔到冷漠,从紧张到放松,或者从愤怒到释然。模型能够理解这些情绪变化,并通过面部表情、肢体语言和语调来反映出来。
它甚至可以处理带有喜剧色彩的夸张表情。例如,“角色突然抬起头,开始大声喊叫”。