



Seedance 2.0:誰もが監督になれる時代のための完全実践ガイド
ここ数日、ByteDance の AI ビデオ モデルSeedance 2.0がインターネットを席巻しました。
Seedance 2.0 で生成されたビデオは今やどこにでもあります。
映画レベルの追跡シーンを制作するためにAIを活用している人もいます。また、大予算のCMで見られるような映画的なカメラワークを再現する人もいます。中には、時代劇やタイムトラベル、本格的な格闘アクション映画にAIを活用する人もいます。その映像は非常に鮮明で精細なので、AIが作成したのか、実際の俳優が撮影したのか見分けるのが本当に難しいほどです。
正直に言うと、それは誇張ではありません。
このアップデートにより、Seedance 2.0 は AI ビデオ作成の障壁を根本から取り除きました。
話はこれくらいにして、まずは簡単なモンタージュから始めましょう↓
それで…どんな感じでしょうか?
なぜこれほど急速に人気が爆発したのか?それは、長年クリエイターを悩ませてきた問題がついに解決されたからだ。AI動画はかつては「生成」が全てだったが、今は「制御」が全てだ。
画像、ビデオ、オーディオ、テキストを自由に組み合わせて、誰でも監督できます。

今回は状況が違います。
Seedance 2.0は、もはや単なるテキストから動画を作成するツールではありません。クリエイティブな意図を理解できる、真にマルチモーダルな動画作成プラットフォームへと進化しました。
画像、動画クリップ、音声、テキストを同時に入力できます。それぞれのアセットの役割を指定すると、全てがブレンドされ、1本の動画が完成します。
少し抽象的ですか?大丈夫ですよ。
すべての機能とワークフローを段階的に説明し、人々がどのように使用しているかを正確に示します。
まず第一に: Seedance 2.0 は実際に何ができるのでしょうか?
Seedance 2.0 の根底には、マルチモーダル性という重要なアップグレードが 1 つあります。
以前のAI ビデオ モデルでは、入力オプションは通常、テキスト プロンプトを書き込むか、最初のフレームの画像を 1 つアップロードするかの 2 つに限定されていました。
カメラの動き、表情、BGMのテンポなどをコントロールしたければ、すべてをテキストに押し込まなければなりませんでした。それがうまくいくかどうかは、プロンプトを書くのがどれだけ上手いかにほぼ完全に左右されました。
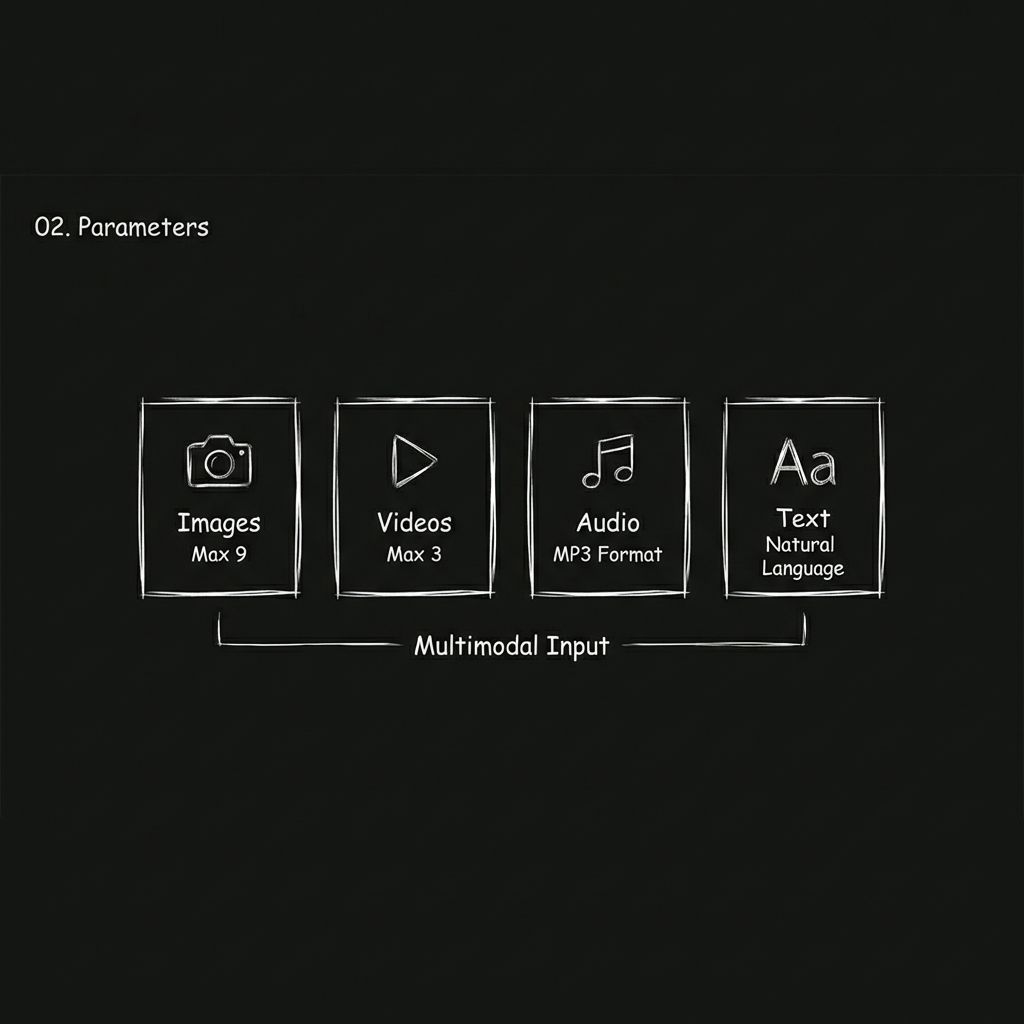
Seedance 2.0 では、入力を 4 つの異なる様式に拡張することでこれを変更します。
画像
最大9枚の画像をアップロードできます。これらの画像で、キャラクターの外見、シーンのスタイル、衣装のディテール、商品のビジュアル、さらにはストーリーボードのフレームなどを定義できます。
ビデオ
動画クリップは最大3つまでアップロードでき、合計再生時間は15秒以内です。モデルはこれらのクリップからカメラの動き、モーションリズム、トランジションスタイルを参照できます。これは、モデルに学習用の視覚的なサンプルを与えるようなものです。
オーディオ
MP3ファイルのアップロードは最大3ファイルまでサポートされており、合計再生時間は15秒以内です。BGMや効果音のスタイルを指定したり、他の動画のナレーショントーンを参照したりすることも可能です。
文章
標準的な自然言語を入力するだけで、必要なビジュアル、アクション、ペースを記述できます。
4つの入力タイプは自由に組み合わせることができます。アップロードできるファイル数は、全モダリティ合わせて12個までに制限されています。
生成される動画の長さは最大15秒です。4秒から15秒の間で任意の長さを選択でき、出力にはサウンドエフェクトとBGMが組み込まれています。
簡単に言えば、ついに本物の映画製作者のように AI を監督できるようになります。
- 画像は視覚的なスタイルを定義します。
- ビデオは動きを定義します。
- オーディオはリズムを定義します。
- テキストはストーリーを定義します。
Seedance 2.0 入力および出力仕様
| パラメータ | 説明 |
| 画像入力 | 最大9枚の画像 |
| ビデオ入力 | 最大3つのクリップ、合計再生時間は15秒以内 |
| オーディオ入力 | MP3 をサポート、最大 3 つのファイル、合計再生時間は 15 秒以内 |
| テキスト入力 | 自然言語による説明(英語と中国語をサポート) |
| 出力期間 | 4~15秒 |
| オーディオ出力 | 内蔵サウンドエフェクトとバックグラウンドミュージック |
| 合計ファイル制限 | アップロードされたすべての資料で最大12ファイル |
始める前の簡単なヒント: 参考資料を増やしても、必ずしも結果が良くなるとは限りません。
ビジュアルやペースに最も大きな影響を与えるアセットを優先し、アップロードスロットを賢く割り当てます。
使い方:ステップバイステップのチュートリアル
ステップ1. 適切なエントリーポイントを選択する
Jimeng を開き、Seedance 2.0 を見つけます。
Seedance 2.0はJimengからアクセスできます。また、 Pollo AI Image to Videoページでも近日中に公開予定です。
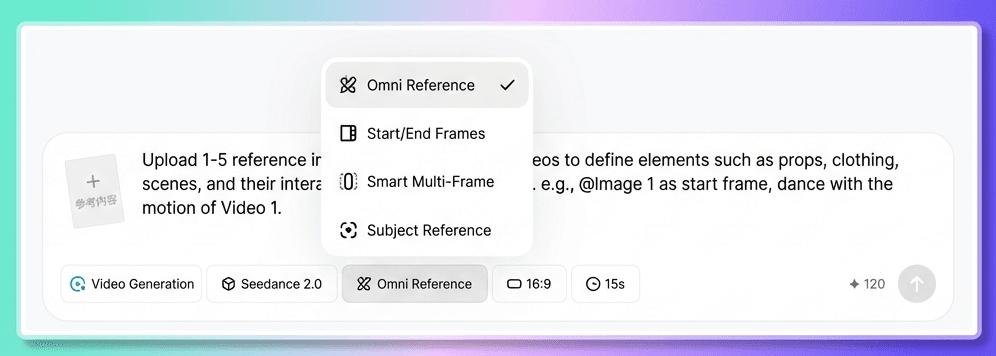
2 つの異なるエントリ ポイントが表示されます。
- 最初と最後のフレーム: テキストプロンプトとともに最初のフレームの画像を 1 つだけアップロードする場合は、このオプションを使用します。
- オールインワン リファレンス: 画像、ビデオ、オーディオ、テキストの組み合わせなど、マルチモーダル入力が必要な場合はこのオプションを使用します。
どちらを使用するかをどのように決めますか?簡単なルールに従ってください。資料が 1 枚の画像とテキストのみで構成されている場合は、「最初と最後のフレーム」を選択します。複数の画像がある場合、またはビデオやオーディオが含まれている場合は、「オールインワン リファレンス」を選択します。
ほとんどの場合、All-in-One Reference の方が優れた選択肢です。あらゆる種類のリファレンス入力をサポートし、Seedance 2.0 の最新機能を最大限に発揮できるのもこのAll-in-One Referenceです。
ステップ2. アセットをアップロードする
アップロードボタンをクリックして、ローカルデバイスからファイルを選択してください。画像、動画、音声はすべて直接ドラッグ&ドロップできます。アップロードが完了すると、すべてのアセットが入力エリアに表示されます。各アイテムにマウスオーバーすると、その内容をプレビューできます。
アップロード前にもう一度ご確認ください。どのアセットが最も重要かをよく考えてください。アップロードできるファイルは合計12個までなので、ビジュアルスタイルとペースに最も影響を与えるものを優先してください。
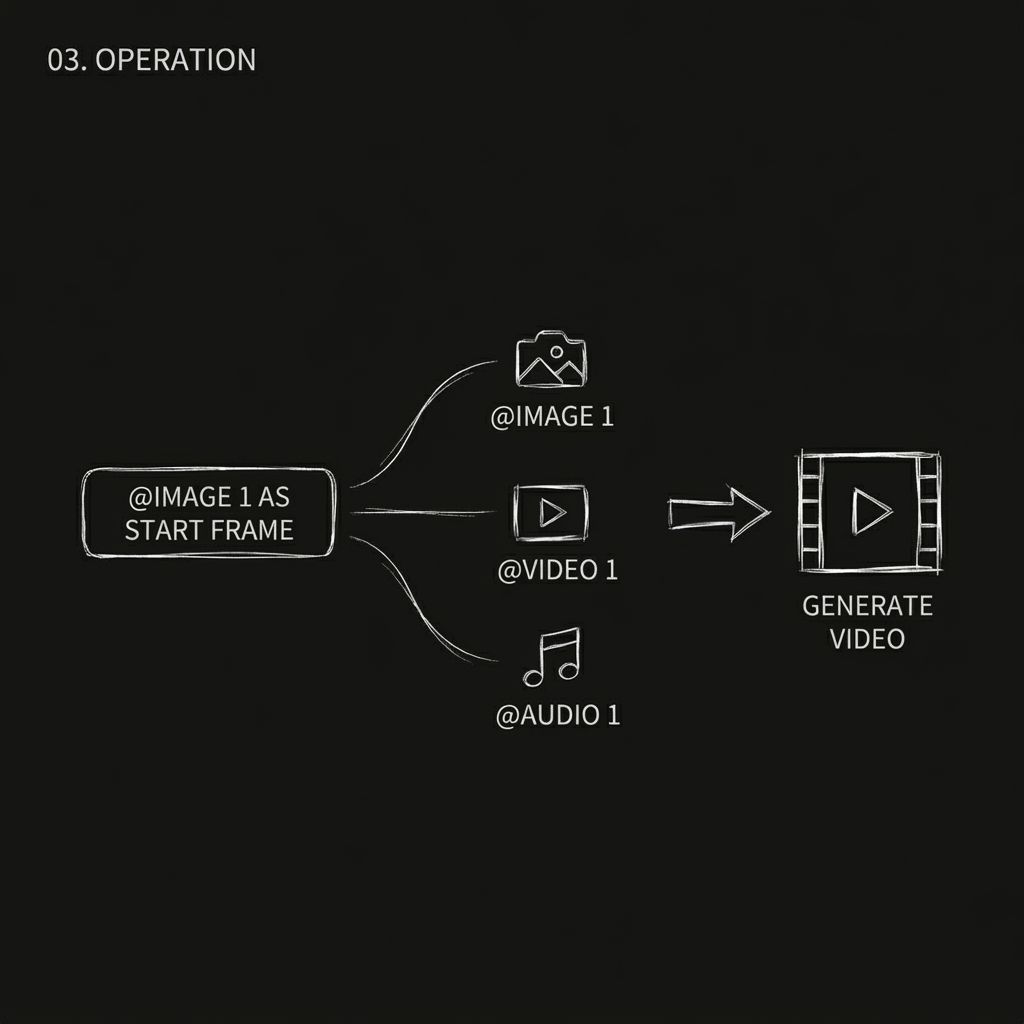
ステップ3. 「@」を使用して各アセットに役割を割り当てる(最も重要なステップ)
これは Seedance 2.0 の核となるインタラクションであり、多くの初心者が見落としがちな部分でもあります。
アセットをアップロードしたら、プロンプト内で@アセット名を使用して、モデルにそれぞれのアセットの用途を明示的に伝える必要があります。モデルは推測しません。明確に説明しないと、アセットを誤って使用してしまう可能性があります。
例えば:
- 最初のフレームとして@Image 1
- @ビデオ 1 をカメラ参照として使用
- @Audio 1(バックグラウンドミュージック用)
「@」をトリガーする方法
方法1
入力ボックスに「@」記号を直接入力してください。アップロードされたすべてのアセットのリストが表示されます。参照したいアセットをクリックすると、プロンプトに挿入されます。
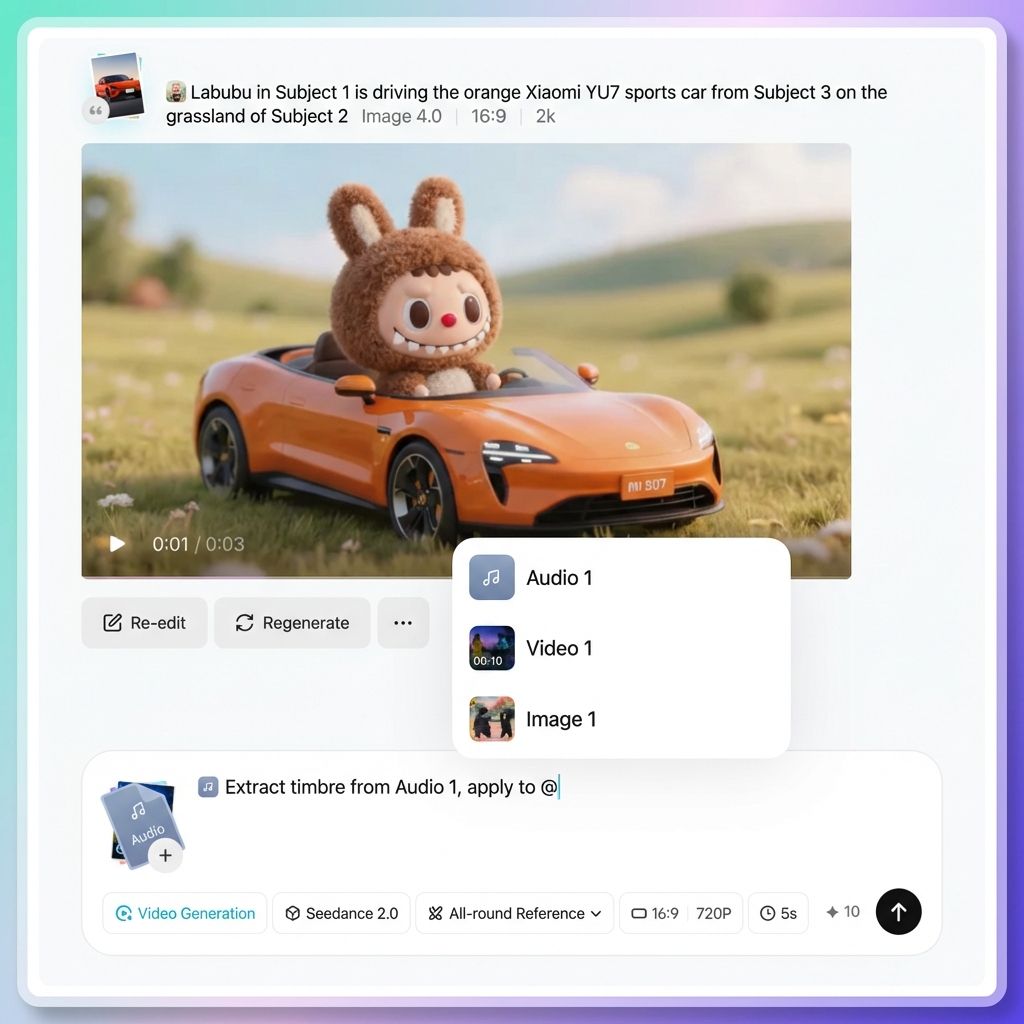
方法2
入力ボックスの横にあるパラメータツールバーの「@」ボタンをクリックします。これによりアセットリストも表示されます。
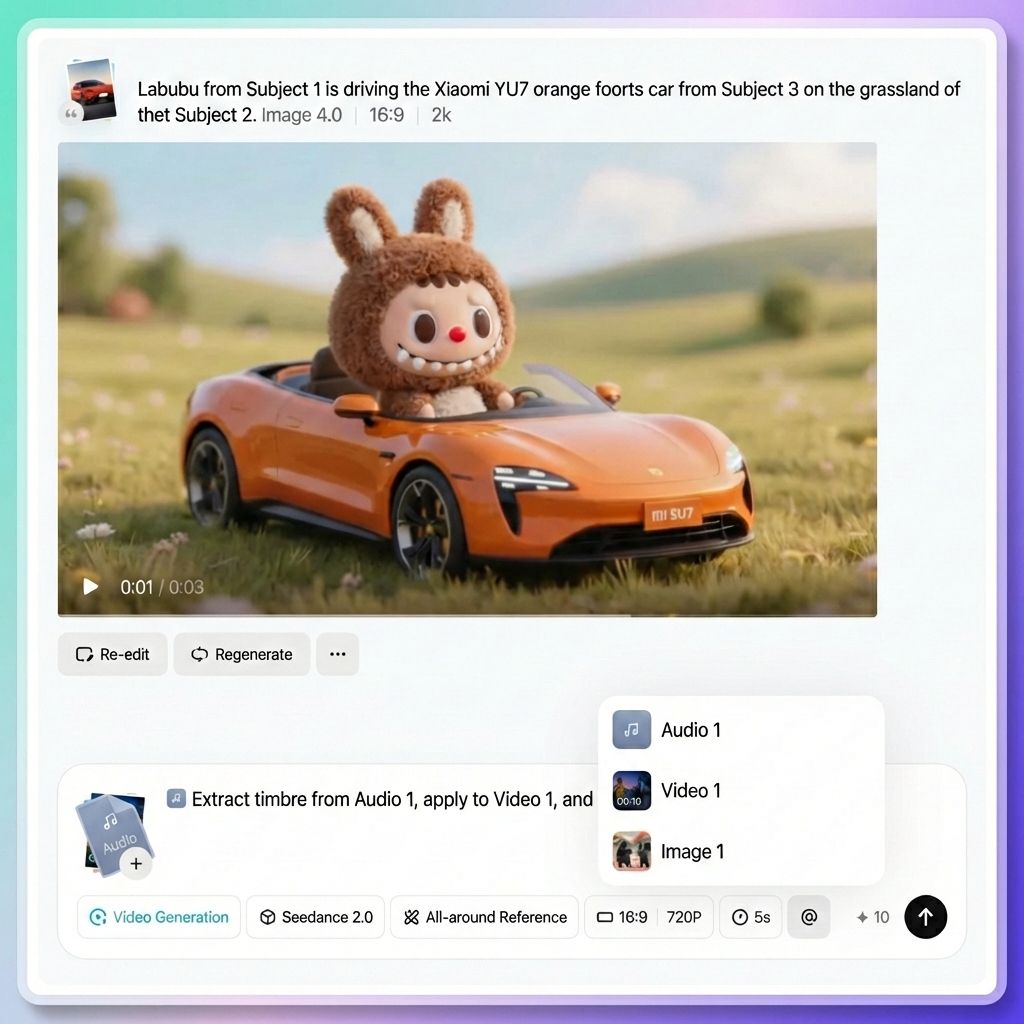
正しい「@」の使用例
- 最初のフレームを指定して参照します。最初のフレームとして@Image 1 を指定し、@Video 1 のカメラ言語を参照し、バックグラウンドミュージックとして@Audio 1 を使用します。
- キャラクターの役割を指定します:@画像1の女性キャラクターを主人公、@画像2の男性キャラクターを脇役とします
- カメラの動きの参照を指定: @Video 1 からのすべてのカメラの動きとトランジションを完全に参照します。
- シーン参照を指定します。左のシーンの参照として@Image 3 を使用し、右のシーンの参照として@Image 4 を使用します。
- アクション参照を指定: @Image 1 のキャラクターは、@Video 1 のダンスの動きを参照する必要があります。
- 音声参照を指定: ナレーションの音声は、@ビデオ 1 の音声トーンを参照する必要があります。
注意すべきよくある落とし穴
多数のアセットを扱う際は、必ずすべての「@」参照が正しいファイルと一致していることを確認してください。画像を動画として参照したり、キャラクターAの画像を誤ってキャラクターBに割り当てたりすると、出力がすぐに混乱する可能性があります。
プロンプト内の参照されているアセットの上にマウスを置くと、プレビューが表示され、すべてが正しくリンクされていることを確認できます。
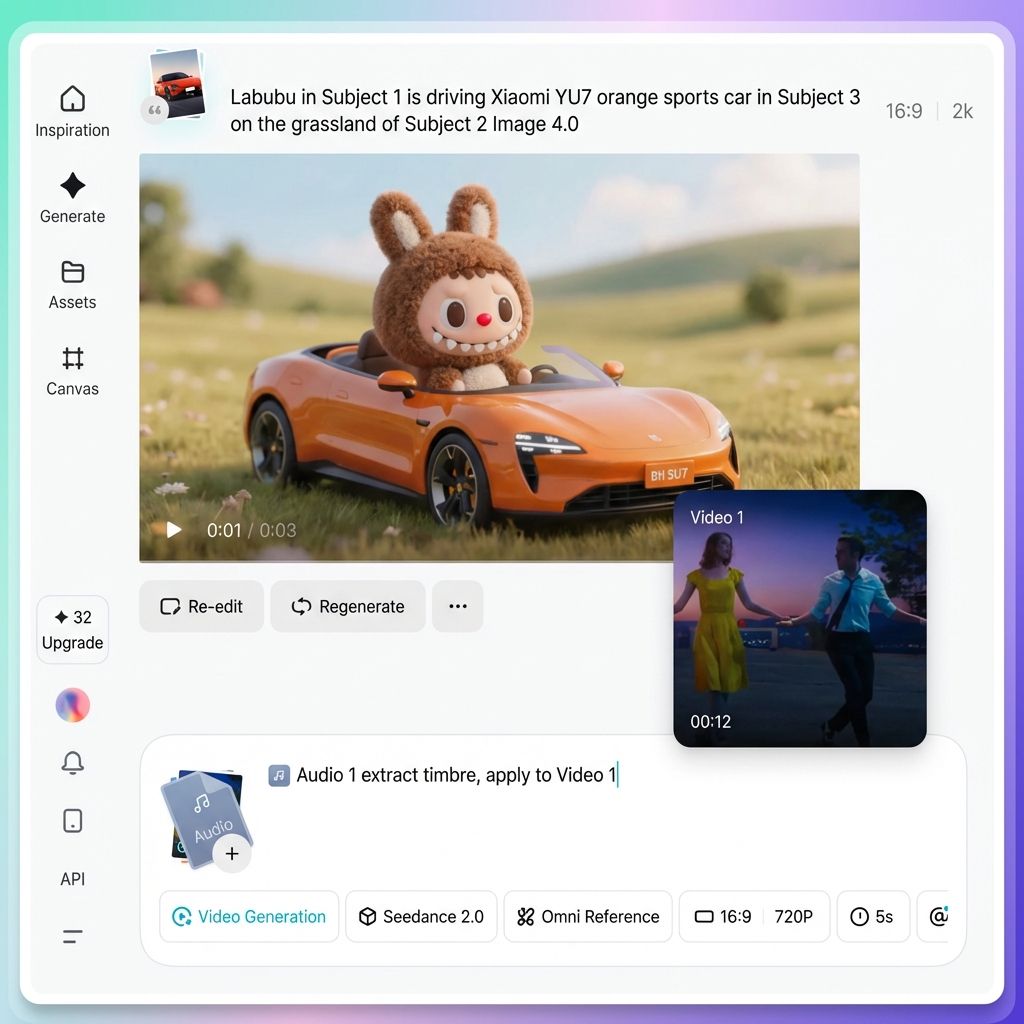
ステップ4. 明確で効果的なプロンプトを書く
「@」を使用してすべてのアセットに役割を割り当てたら、残りは自然言語で必要なビジュアルとアクションを記述するだけです。
より良いプロンプトを書くための 4 つの実用的なヒントを紹介します。

ヒント1.タイムライン構造で書く
動画に複数のシーンや物語の転換が含まれる場合は、時間に基づいてセグメントごとに説明するのが最適です。
例えば:
0~3秒
主人公の男性はバスケットボールを手に掲げ、カメラを見上げてこう言った。「ただ飲み物が飲みたかっただけなんだ。本当にタイムトラベルするのかな?」
4~8秒
突然、カメラが激しく揺れる。場面は古い屋敷の雨の夜へと切り替わる。民族衣装をまとったヒロインの女性がカメラに向かって冷ややかな視線を向ける。
9~13秒
カメラは明朝の衣装を着た人物に切り替わります…
このように記述することで、モデルは各セグメントのペースとコンテンツをより正確に理解できるようになります。
ヒント2.「参照」と「編集」を明確に区別する
これら 2 つの概念は同じではありません。
「@Video 1 のカメラの動きを参考にする」とは、そのカメラモーションスタイルを使用して新しいコンテンツを生成することを意味します。
「@ビデオ 1 の女性キャラクターを伝統的なオペラ演奏者に置き換える」とは、元のビデオ自体を変更することを意味します。
どちらを望んでいるかを明確にして、モデルが正しく応答できるようにします。
ヒント3. カメラマンの言葉遣いを具体的にする
書きすぎを心配する必要はありません。モデルのカメラ操作の理解力は格段に向上しています。
プッシュ、プル、パン、トラック、ドリー、オービット、トップダウンショット、ローアングルショット、ワンテイクショット、ヒッチコックズーム、魚眼レンズ。これらの専門用語をすべて理解します。
専門用語に詳しくなくても大丈夫です。「カメラがキャラクターの後ろから前にゆっくりと移動する」など、分かりやすい説明でも構いません。
ヒント4. 連続アクションにトランジションを追加する
キャラクターに連続したアクションを実行させたい場合は、遷移を明確に記述するようにしてください。
例えば、「キャラクターはジャンプから直接ロールに移行し、動きを連続的かつ滑らかに保ちます。」これにより、最終的な動画で不自然なジャンプカットが発生するのを防ぐことができます。
ステップ5. 期間を選択して生成する
必要なビデオの長さ(4~15 秒)を選択します。
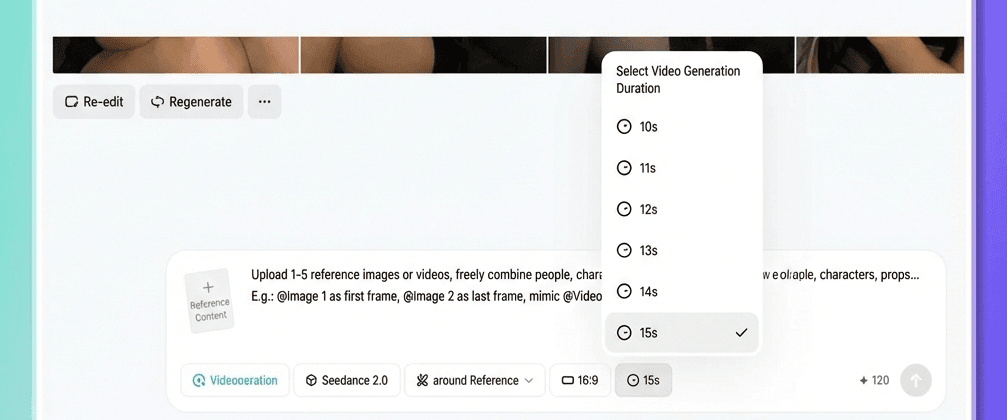
重要な注意点が 1 つあります。
既存の動画を延長する場合(例えば、クリップの最後に5秒追加する場合)、ここで選択する長さは新しく生成された部分のみを指し、動画全体の長さを指すものではありません。動画を5秒延長したい場合は、5秒を選択してください。
次に、「生成」をクリックして結果を待ちます。
満足できない場合は、お気軽に複数回生成してください。AIの出力にはランダム性があるため、同じ入力であっても、毎回結果がわずかに異なる場合があります。一番気に入ったバージョンをお選びください。
Seedance 2.0 のコア機能を詳しく見る
Seedance 2.0の最も強力な10の機能をご紹介します。それぞれに実用的な使い方ガイドと実例が付属しています。
機能1. 画質の大幅な向上
まずは基礎から始めましょう。
Seedance 2.0は、基盤を全面的にアップグレードしました。物理演算はより正確に、動きはより滑らかになり、ビジュアルスタイルはシーン全体でより一貫性を保ちます。
画像生成の最も基本的な層では、質的な飛躍がありました。
- よりリアルな物理特性: 衣服の動き、水しぶき、物体の衝突など、すべてがより自然に動作します。
- よりスムーズで自然な動き: 歩く、走る、さらには複雑な動作でも、ぎこちなく機械的に見えなくなります。
- より正確な指示理解:「女の子が優雅に服を掛けている」と言うと、「優雅に」の意味を真に理解します。
- より安定したスタイルの一貫性: 視覚的なスタイルは、突然の変化がなく、最初から最後まで一貫したままです。

使用例
少女が優雅に洗濯物を干している。一枚干すと、バケツからもう一枚取り出し、力強く振る。
これは実際には何を意味するのでしょうか?
「女の子が優雅に服を掛け、バケツからまた服を取り出して勢いよく振る」といったシーンを生成した際に、布の動きや腕の力加減、布の質感などが実写映像に驚くほど近いと感じました。
より複雑なシーンも容易に実現できます。
カメラは猛スピードで逃走する黒服の男を追う。背後から一団が追いかけてくる。ショットはサイドトラッキングに切り替わる。パニックに陥った男は道端の果物屋に激突し、転倒するが、立ち上がって走り続ける。
バージョン 2.0 では、追跡シーケンス、衝突、動的カメラ トランジションを含むシーンを一貫して生成できるようになりました。
さらに極端な例もあります。あるクリエイターは、たった一つの指示で、絵画の中の登場人物がこっそりとコーラの缶に手を伸ばし、一口飲み、足音が聞こえるとすぐに缶を戻し、そして最後のショットへと移行し、コーラの缶だけが描かれた黒い背景に芸術的な字幕が映し出されるという描写をしています。これほど複雑な物語は、かつてはほとんど考えられなかったでしょう。
機能2. 自由なマルチモーダル組み合わせ
これはバージョン2.0における最も重要なアップグレードです。あらゆるタイプの資料を参照資料として使用できるようになりました。
この式は次のように要約できます。
Seedance 2.0 = マルチモーダル参照 + 強力な創造的生成 + 正確な指示理解
以下を参照できます:
- アクション、効果、視覚形式
- カメラの動きとショット言語
- キャラクターの外見とシーンスタイル
- 音と音楽のリズム

実用的なヒント
| 何をしたいのか | プロンプトの書き方 |
| キーフレーム画像があり、ビデオモーションを参照したい場合 | 「@Image 1 をキーフレームとして、@Video 1 のカメラの揺れを参照します」 |
| 既存のビデオを拡張する | 「@Video 1 を 5 秒延長する」(生成時間を 5 秒に設定) |
| 複数のビデオを組み合わせる | 「@ビデオ 1 と @ビデオ 2 の間にシーンを挿入します。コンテンツは xxx です」 |
| ビデオの音声を使用する | 音声を別途アップロードする必要はなく、ビデオを直接参照するだけです |
| 継続的なアクション | 「キャラクターはジャンプからロールに直接移行し、動きをスムーズかつ連続的に保ちます」 |
能力3: 一貫性の大幅な向上
AI ビデオに取り組んだことがある人なら誰でも、一貫性が最もイライラする問題であることを知っています。
ショットごとに顔が変わったり、角度が変わると商品の詳細が消えたり、シーンのスタイルが突然変わったりします。
バージョン 2.0 では、この問題を解決するために真剣に取り組んでいます。
キャラクターの参考画像をアップロードすると、動画全体を通して人物の外見、服装、姿勢が統一されます。これは商品紹介にも当てはまります。バッグを複数の角度から回転させても、正面、側面、素材のディテールはそのまま残ります。
一貫性を保つことができる要素:
- 顔の特徴(顔の構造、肌の色、表情)
- 衣服の詳細(質感、色、模様)
- ブランド要素(ロゴ、タイポグラフィ、配色)
- シーンスタイル(照明、雰囲気、色調)
使用例
男性@Image1は仕事帰りに廊下を歩いている。疲れ切った様子だ。足取りが緩む。玄関で立ち止まり、深呼吸をして気持ちを落ち着かせ、鍵を探し、鍵を開けて中に入る。幼い娘と飼い犬が嬉しそうに駆け寄り、抱きしめる。

@Image1 を参照することで、シーケンス全体を通じてキャラクターの外観の一貫性が保たれます。
機能4: 正確なカメラモーションとアクションの再現
これは 2.0 で最も話題になった機能の 1 つです。
これまで、AI に映画のカメラの動きを模倣させたい場合、長い技術用語のリストを書いてうまくいくことを祈るしかなく、そうしないとうまくいかなかったのです。
今では、次の 2 つの手順だけが必要です。
気に入ったカメラの動きが映っている参考動画をアップロードし、次のように記述します。
「@Video1 のカメラの動きを参考にしてください。」
モデルは、参照ビデオ内のカメラ ロジック (プッシュ、プル、パン、トラック、オービット、ズーム、連続ショットなど) を分析し、同じ動きのスタイルを新しいコンテンツに適用します。
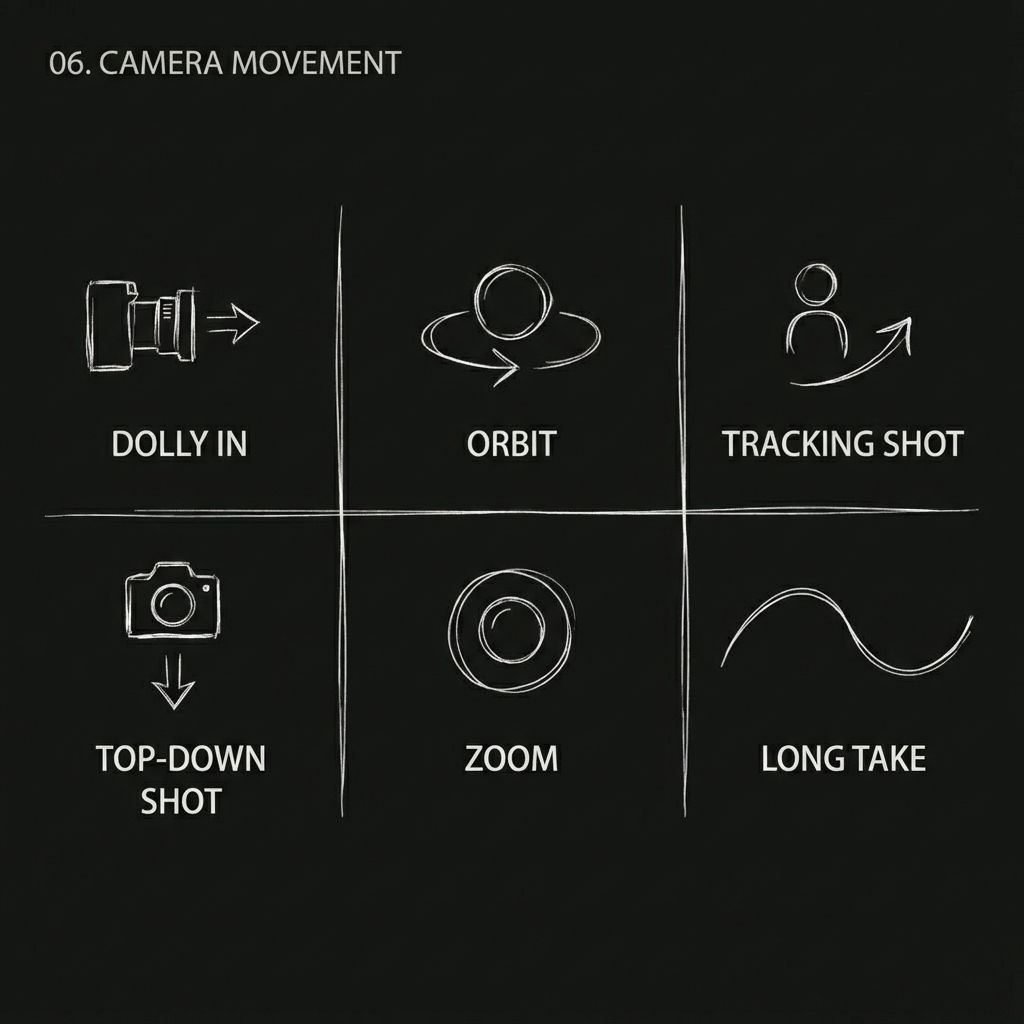
再現可能なカメラの動き:
- ヒッチコックズーム
- 軌道追跡ショット
- 1回の連続テイク
- プッシュ/プル/パン/トラッキングショット
- ローアングルショット
- 上空からの鳥瞰図
例: 古典的な武侠のシーンを再現する
機能5. クリエイティブテンプレートとエフェクトの正確な再現
気に入ったクールな広告コンセプト、トランジション効果、または映画のクリップを見つけましたか?
参考資料として直接アップロードしてください。モデルは、動画内の動きのリズム、視覚的な構造、カメラワークを識別し、独自のバージョンを再現するのに役立ちます。
再作成できるクリエイティブコンテンツの種類:
- パズルの粉砕、粒子の分散、虹彩スタイルのポータル遷移などのクリエイティブな遷移
- 完成した広告スタイル
- MV風リズム編集
- 映画のような特殊効果ショット
- 衣装の変身と顔の交換エフェクト
例:
特殊効果も最大限に発揮…
機能6. ビデオの拡張と継続
すでに満足のいく動画があり、ストーリーを続けたいですか?それとも、既存のクリップの前にバックストーリーを追加したいですか?動画拡張機能なら、そのどちらにも対応できます。
前方に伸びる
既存のビデオをアップロードし、「@Video 1 を X 秒延長」と入力し、生成する新しいシーンの説明を続けます。
後方に伸ばす
「X 秒前に延長」と書き、作成したい以前のストーリーラインの説明を追加します。
使用ルール
モデルに明確に指示します。「@Video 1 を X 秒延長してください。」
生成時に、延長する長さと同じ長さを選択します。例えば、5秒延長したい場合は、生成長さとして5秒を選択します。
拡張部分には、新しいプロット要素と視覚的な説明を含めることができます。
前方拡張と後方拡張の両方がサポートされています。
使用例
画像や動画を参考にすれば、上記の 2 秒のオリジナル クリップを 15 秒まで延長できます。
拡張部分については、カメラの動き、視覚要素、画面上のテキストなど、詳細に説明できます。
機能7. よりリアルなオーディオ
バージョン 2.0 で生成されたビデオには、サウンド効果とバックグラウンド ミュージックが組み込まれており、全体的なオーディオ品質が以前に比べて大幅に向上しています。
ここでは、オーディオ関連の使用例をいくつか紹介します。
声のトーンの参考
ビデオまたはオーディオ クリップをアップロードし、モデルがその話し方やナレーション スタイルを模倣できるようにします。
多言語対話
登場人物は中国語、英語、スペイン語、韓国語など様々な言語を話します。感情表現も非常に巧みです。
複数のキャラクターによる会話
1本の動画に複数のキャラクターが登場し、それぞれがセリフを話すこともあります。犬猫トークショー、時代劇のセリフ、軍事戦術に関する会話など、成功例はたくさんあります。
方言サポート
ミルクティーを注文しながら四川語を話すキャラクターを生成することに成功したクリエイターもいます。その出来栄えは驚くほど本物らしく感じられます。
効果音マッチング
足音、雷、群衆の騒音、機器の衝突、その他の環境音はすべて、かなりの精度で生成できます。
機能8. より一貫性のあるワンテイクショット
「ワンテイク」ショットでは、複雑な空間遷移とカメラの動きを扱いながら、長時間にわたってシーンを連続的に維持する必要があります。これはAIにとって常に困難な課題でした。
Seedance 2.0はこの分野で明確な進歩を遂げました。異なるシーンから複数の画像をアップロードし、「ランナーが通りから階段を上り、廊下を抜け、屋上へ行き、最後に街を見下ろすまでの連続トラッキングショット」などと記述すれば、モデルはシーン間の自然な遷移を、途切れることなく実現できます。
より複雑なワンテイクシーケンスも可能です。例えば、「一人称視点で飛行機の窓から雲がアイスクリームに変わる様子を撮影し、登場人物がアイスクリームを手に取って一口食べるシーンでカメラを機内に引き戻す」といった具合です。
視点の切り替えやリアリズムとファンタジーの融合を伴うこのようなワンテイクのシーケンスも、Seedance 2.0 で処理できます。
スパイ・スリラー風のワンカットシーンもいくつかある。カメラは赤い服を着た女性エージェントが群衆の中を進む様子を捉える。彼女は角を曲がると仮面の少女と遭遇し、追跡を続けるが、ターゲットは屋敷の中で姿を消す。全てカットカットなしで。
連続ショットでこのレベルの物語の密度を達成することは、すでにかなり印象的です。
使用例
@Image1 @Image2 @Image3 @Image4 @Image5、ランナーが通りから階段を上り、廊下を抜けて屋上に出て、最後に街を見下ろすまでを追う連続トラッキング ショット。
ヒント
複数の画像を連続して並べます。モデルは連続ショット内でこれらのシーンを順番に提示します。
機能9. AIビデオ編集
すでにビデオがあり、ゼロから始めるのではなく、一部だけを修正したいですか?既存のビデオを入力として使用し、対象を絞った編集を行うことができます。
文字の置き換え
動画内のキャラクターAをキャラクターBに置き換えますが、元の動作や表情はそのままにしてください。例えば、「動画1の女性リードシンガーを画像1の男性リードシンガーに置き換え、元の動きを完全に再現する」などです。
プロットの逆転
シーンと登場人物はそのままに、ストーリーラインを完全に書き換える。橋の上でロマンチックな月見シーンを、男性主人公が女性主人公を水に突き落とすというドラマチックな展開に変えるクリエイターもいる。また、バーでの緊迫した交渉を、誰かが大きな袋に入ったスナック菓子を取り出すというコメディシーンに変えるクリエイターもいる。
要素の変更
髪型を変えたり、小道具を追加したり、背景を変えたりしてみましょう。例えば、「動画1の女性の髪型を長い赤毛に変え、@画像1のホホジロザメを彼女の後ろ半分にゆっくりと浮かび上がらせる」といった具合です。
ブランド統合
既存の動画にブランド要素を挿入します。例えば、フライドチキンの動画にブランドロゴが入った紙袋のクローズアップを追加します。
例 - 文字の置換:
Black Myth: Wukong を再現し、キャプテン・アメリカと戦わせます。
機能10: ビート同期編集
リズミカルなミュージックビデオを参考にアップロードしてください。モデルはテンポの変化を検出し、シーンのカットをビートに合わせて正確に調整できます。
基本的なビート同期
画像素材と音楽参考動画をアップロードし、以下を記入してください。
「ビジュアルを@Video のリズムに同期させます。」
ダイナミックビートシンク
書く:
「キャラクターをよりダイナミックにし、全体的に夢のようなビジュアルスタイルを強化し、視覚的な緊張感を高め、必要に応じて音楽に合わせてショットのスケールを調整します。」
ランドスケープビートシンク
複数の風景画像と音楽を組み合わせる場合は、次のように記述します。
「風景シーンは@Videoのリズムを参考にし、トランジションをビジュアルスタイルと音楽のビートに同期させます。」
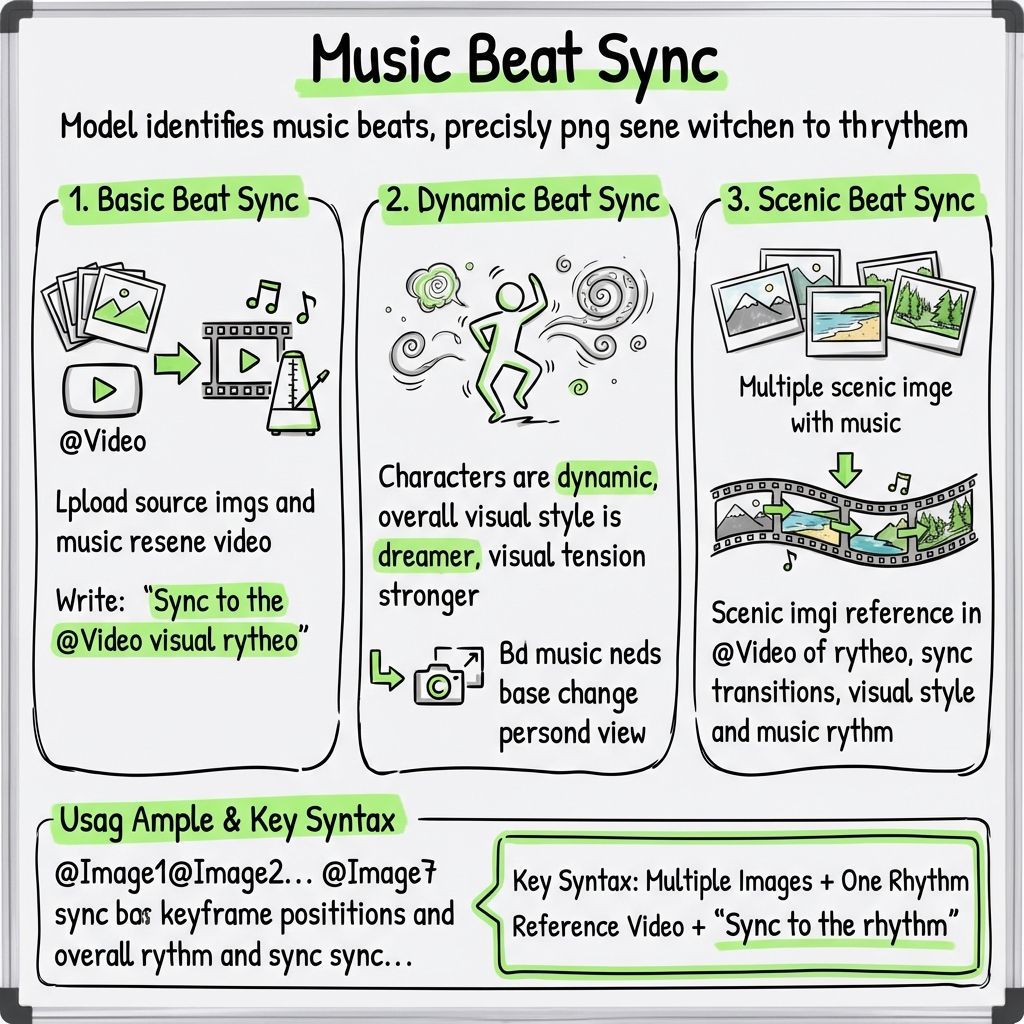
使用例
@画像1 @画像2 @画像3 @画像4 @画像5 @画像6 @画像7
これらの画像を、@Videoのキーフレームの位置と全体のリズムに合わせて同期させます。キャラクターをよりダイナミックにし、ビジュアルスタイル全体に夢のような雰囲気を与えます。
キーフォーミュラ
複数の画像+リズム参考動画1本+「リズムに合わせる」
能力11. より説得力のある感情表現
AI生成動画では、表情の硬直や感情の移り変わりが長年の課題となっていました。バージョン2.0では、この点が明確に改善されています。
感情表現の参考として動画をアップロードし、モデルにその動画の表情変化を真似させることができます。例えば、「@画像1の女性は鏡に向かって歩き、考え事をしながら立ち止まり、突然泣き崩れて叫び声を上げます。鏡を掴む動作と、その泣き崩れる感情の激しさは、@動画1を完全に反映しているはずです。」といった具合です。

感情の移り変わりをテキストで正確に表現することもできます。例えば、穏やかな表情から冷たい表情へ、緊張した表情からリラックスした表情へ、怒りの表情から安堵の表情へなどです。モデルはこれらの感情の変化を理解し、表情、ボディランゲージ、声のトーンを通して表現します。
コメディ調の誇張表現にも対応可能です。例えば、「登場人物が突然顔を上げて大声で叫び始める」といった表現です。