



Vidu AI Video Generator (Vidu Studio)
Vidu AI builds coherent short-form stories with consistent characters, smooth motion, synced audio, and strong controls. Try Vidu AI on Pollo AI for free!
Key Features of Vidu AI
- Multi-Mode Video Generation: Turn text, images, or visual references into videos through one flexible workflow.
- Multi-Reference Consistency: Keep your characters, products, and settings recognizable throughout more complex video scenes.
- First-and-Last Frame Control: Define how your video begins and ends while Vidu creates the transition.
- Natural Motion Generation: Bring characters and subjects to life with fluid, expressive, and believable movement.
- Precise Camera Control: Shape camera movement, pacing, and visual emphasis for more intentional storytelling.
- Native Audio-Video Generation: Generate coordinated visuals, dialogue, music, and sound effects in one process.
- Visual Style Versatility: Explore cinematic, realistic, animated, and illustrated looks for different creative goals.
Multi-Mode Video Generation
Start with whatever best expresses your idea. Vidu supports text-to-video, image-to-video, and reference-to-video generation within one platform.
You can explore an early concept, animate an existing image, or build a more directed scene without switching between separate tools or rebuilding your creative workflow from scratch.
Multi-Reference Consistency
Use multiple visual references to help Vidu understand how your characters, products, objects, and environments should appear. This makes it easier to create connected scenes with recognizable recurring elements.
You can develop richer stories, branded content, and product videos while maintaining a clearer visual identity across each generated sequence.
| Image 1 | Image 2 | Output Video |
 |  |
First-and-Last Frame Control
Define both the opening and closing images of your video, then let Vidu generate the movement between them. This gives you greater control over transformations, reveals, entrances, exits, and visual transitions.
Your videos can reach a more purposeful destination instead of relying entirely on an unpredictable ending generated from one starting frame.
| Input | Output video |
  |
Natural Motion Generation
Turn static concepts into active scenes with expressive gestures, fluid body movement, and believable subject animation. Vidu can help your characters walk, react, interact, or perform with greater energy.
By making movement feel more natural, your videos become easier to follow, more emotionally engaging, and less like animated still images.
Precise Camera Control
Guide how your scene is presented by shaping camera movement, shot pacing, and visual emphasis. You can create pushes, pans, tracking shots, or changes in focus that support the story rather than distract from it.
This added direction helps your videos feel more cinematic, deliberate, and visually connected from beginning to end.
| Camera movement | Output video |
| Pan | |
| Zoom |
Native Audio-Video Generation
Create visuals and sound as part of the same generation process. Vidu can coordinate dialogue, voiceover, music, and sound effects with the action on screen, helping each element feel more naturally timed. You can produce fuller narrative videos with less manual audio assembly and fewer separate post-production steps afterward.
| Prompt | Output video |
| In rural Ireland, circa 1860s, two women, their long, modest dresses of homespun fabric whipping gently in the strong coastal wind, walk with determined strides across a windswept cliff top. The ground is carpeted with hardy wildflowers in muted hues. They move steadily towards the precipitous edge, where the vast, turbulent grey-green ocean roars and crashes against the sheer rock face far below, sending plumes of white spray into the air. | |
| A keyboard whose keys are made of different types of candy. Typing makes sweet, crunchy sounds. Audio: Crunchy, sugary typing sounds, delighted giggles. | |
| A snow-covered plain of iridescent moon-dust under twilight skies. Thirty-foot crystalline flowers bloom, refracting light into slow-moving rainbows. A fur-cloaked figure walks between these colossal blossoms, leaving the only footprints in untouched dust. |
Visual Style Versatility
Adapt your videos to different audiences and creative purposes with cinematic, realistic, animated, anime-inspired, or illustrated visual directions. This flexibility helps you create social content, advertisements, concept films, and character-driven stories with a more suitable look.
Your generated videos can better reflect the mood, message, and identity you want to communicate.
| Prompt | Output Video 1 | Output Video 2 |
| Create a video of a rugged pirate with a weathered face and long dreadlocks walking cautiously through a dark cave, his torch flickering and casting shadows on the jagged walls. |
Primary Use Cases of Vidu AI
- Social Media Creators: Generate cinematic short clips from prompts, speeding up posting and improving visual engagement.
- Anime Creators: Build stylized sci-fi anime shorts, testing stories faster without full animation teams.
- Film Teams: Create previsualization shots and reference-based scenes, reducing early production costs.
- Game Developers: Produce animated concept scenes, helping teams pitch worlds and test visual direction faster.
- Ad Teams: Turn product concepts into short video ads, helping teams test hooks before studio production.
- Brand Storytellers: Combine faces, props, and scenes into coherent clips, improving character consistency.
- Art Designers: Animate still artwork and concept images, making portfolios more dynamic and presentation-ready.
- Short Drama Creators: Generate character-led micro scenes, expanding story output without lengthy shooting schedules.
Vidu AI’s Technical Structure
The foundation of Vidu AI relies on a diffusion model with a U-ViT backbone. This structure treats time, text conditions, and noisy 3D patches as tokens within a transformer framework.
It employs long skip connections between shallow and deep layers to enhance processing efficiency. A video autoencoder is utilized to significantly reduce spatial and temporal dimensions during generation.
Vidu AI can handle variable video durations up to 16 seconds at 1080p resolution. The model was trained on vast text-video pairs using an automatic video captioner for improved understanding.
Moreover, a re-captioning technique helps rephrase user inputs to optimize the final video output.
Vidu AI’s Commercialization Model
The product ecosystem includes Vidu MaaS, Vidu SaaS, a mobile application, and an agent platform.
The company operates on a freemium model with tiered subscription plans for advanced features. Free users face watermarks and strict commercial use prohibitions, encouraging upgrades to paid tiers.
The platform has also seen significant adoption across film, advertising, gaming, and smart hardware sectors.
This widespread enterprise adoption helped secure over RMB 600 million in Series A+ funding.
Additionally, Alibaba led a $290 million investment to further accelerate Vidu's global expansion.
Vidu AI Review: Is It Worth Your Time?
Based on users’ comments from review platforms like Trustpilot, here are several key strengths and weaknesses of Vidu AI.
What Users Like
- Exceptionally fast generation speed.
- Strong character consistency when using the reference-to-video feature.
- The visual quality features sharp details and smooth, natural motion.
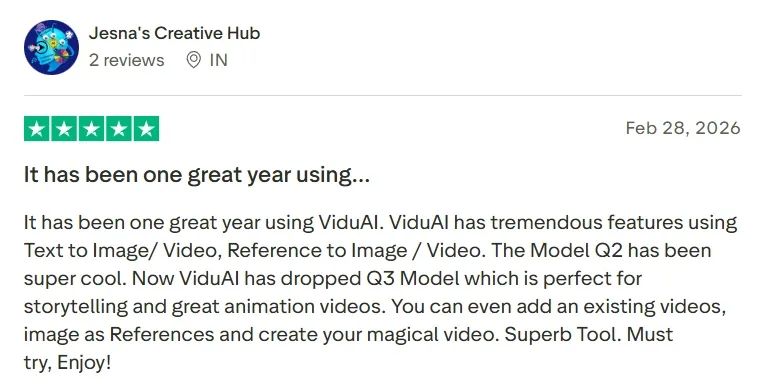
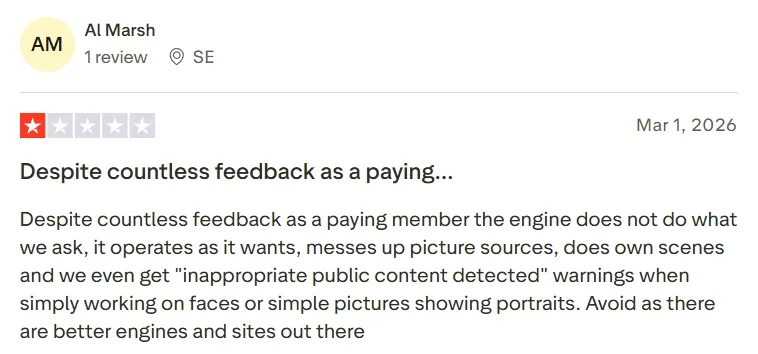
What Users Dislike
- Steep learning curves as precise visuals require professional prompts or iterative generation.
- Strict censorship on generated content can constrain users’ imagination.
Feature Comparison: Vidu AI vs Hailuo AI vs Seedance AI
| Feature | Vidu AI | Hailuo AI | Seedance AI |
| Core Strengths | Anime style, audio-visual sync, multi-shot | Fast generation, ease of use, social media | Cinematic realism, quad-modal input, physics |
| Max Video Length | Up to 16 seconds per shot (Q3 model) | Typically 6 to 10 seconds | Varies; supports multi-shot sequences |
| Resolution | Up to 1080p | Up to 1080p (768p on free plan) | Up to 1080p |
| Audio Generation | Yes, synchronized dialogue and effects | Yes, AI voices and narration | Yes, native audio and lip-sync |
| Best Suited For | Narrative creators, anime artists, marketers | Social media managers, casual creators | Filmmakers, commercial production, concept art |
| Key Limitations | Strict content filters, no refunds | Short duration, inconsistent quality | Limited global access, requires prompt tuning |

How to Use Vidu AI on Pollo AI
Choose the Vidu AI Model
Go to the Pollo AI image to video generator and choose the Vidu AI model.
Input Image and Text Prompt
Upload your image, input text prompt, and customize the creation options.
Create Video
Hit the button and wait a moment for the AI video to generate.
Discover Other AI Video Generators
FAQs
What is Vidu AI?
Vidu AI is a cutting-edge video generation model developed by Shengshu Technology in collaboration with Tsinghua University in China. This innovative platform allows users to create videos from simple text prompts, transforming ideas into dynamic visual content in mere seconds.
What is the process behind Vidu Studio's functionality?
Users provide basic text prompts, which the model swiftly converts into dynamic videos, usually lasting up to 8 seconds. This innovative method enables quick and captivating AI video production, making it an invaluable resource for content creators.
Is Vidu Studio available for free?
Vidu Studio offers a free version that provides users with 80 credits per month to test its features, allowing you to test out with video generation without any initial investment. However, for more extensive use and access to premium features, it may be necessary to upgrade to one of the paid subscription plans.
Is Vidu AI genuinely effective?
While Vidu AI occasionally struggles with complex scenes, it excels in stylized prompts, especially those that play to its strengths, like anime-style visuals. Additionally, Vidu AI demonstrates impressive capabilities in ensuring performance when transferring styles between formats, showcasing its potential for diverse applications in video content generation.
When should I use Vidu Studio?
You should consider using Vidu Studio when you need to create engaging content quickly, such as for social media posts and marketing videos, etc. Its ability to create high-class videos in a matter of seconds makes it ideal for fast-paced environments where time is crucial.
Is Vidu AI Chinese?
Yes, Vidu AI is a Chinese AI video generator launched by Shengshu Technology in collaboration with Tsinghua University. Unveiled at the Zhongguancun Forum in Beijing, Vidu AI aims to compete with global AI tools like OpenAI's Sora by offering text-to-video capabilities that can generate high-definition videos based on simple text prompts.
Is Vidu Studio private?
Vidu Studio takes user privacy seriously and implements measures to protect personal information. This information is utilized to improve services and facilitate customer communication. Vidu Studio ensures that personal data is not shared with third parties without user consent except in specific legal situations.
Are there any products that work better than Vidu AI?
Certainly! In today's market, Vidu AI has garnered significant attention. However, many users of visual content are looking for alternatives to Vidu AI that can address their specific requirements, such as user-friendly interface, cost-effectiveness or more available options for customization.
Among them, we recommend you try Pollo AI. It's a powerful AI video generator with all the best models, including Vidu AI and Seedance 2.0, and can deliver realistic and expressive results. It offers an image to video AI, text to video AI, consistent character video maker, video-to-video generator, AI animation generator and many others.

Try Vidu AI for Free on Pollo AI Instantly
Pollo AI offers features that easily create vivid AI videos, all while maintaining quality. Elevate your video production and try Vidu AI on Pollo AI today!